HttpRunner HttpRunnerManager 定制化支持微服务和 jenkins 持续集成以及 docker 方式部署
前言
HttpRunner 是一款面向 HTTP(S) 协议的通用测试框架,只需编写维护一份 YAML/JSON 脚本,即可实现自动化测试、性能测试、线上监控、持续集成等多种测试需求。并且整套框架都是由 python 语言开发,对于 python 技术栈的工程师熟悉和使用 HttpRunner 框架进行接口测试会非常便利。在功能和特性上 HttpRunner 框架与现在主流的 Java 语言开发的接口测试框架不相伯仲。HttpRunner 测试框架的使用方法@debugtalk大神已经写得非常详细了,具体请看HttpRunner 中文使用手册。本文想讲述一下 HttpRunnerManager 平台的 docker 部署方式和一些定制化改动,目的是完善围绕 HttpRunner 为核心的接口测试平台化建设。具体内容会涉及以下几个方面
- HttpRunnerManager docker 部署方式详解
- 支持微服务架构的环境配置方式
- 支持 jenkins 持续集成远程调用平台脚本
HttpRunnerManager Docker 部署
1.拉取项目代码
将项目代码拉取到本地
git clone https://github.com/HttpRunner/HttpRunnerManager.git
2.搭建 mysql 数据库
- 拉取镜像 在https://hub.docker.com/_/mysql/ 中找到 mysql 的官方镜像库,选择 mysql 8 进行拉取,docker pull mysql:8,mysql 版本按照要求大于 5.7 即可。
- 启动 mysql 镜像
docker run --name trtjk-mysql -p 3306:3306 -d --restart always -v /mysql/data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=xxxx mysql:8--name定义容器名称,-p 对外暴露端口,-d --restart always后台执行容器挂了自动重启,-v外挂在目录,将 mysql 数据持久化到本地。最后是镜像名称,启动成功后可以在外部直接访问到数据库
3.安装 rabbitmq 消息中间件
docker run -d --name rabbitmq --publish 5671:5671 \
--publish 5672:5672 --publish 4369:4369 --publish 25672:25672 --publish 15671:15671 --publish 15672:15672 \
rabbitmq:management
http://host:15672/#/ host 即为你部署 rabbitmq 的服务器 ip 地址 username:guest、Password:guest, 成功登陆即可
4.部署 HttpRunner-manager 平台代码
- 制作 dockerfile
HttpRunner-manager 是 Django 应用,我们按照 Django 官方要求编写 dockerfile,我们使用 python3.6 镜像为基础,创建工作目录/usr/src/app,执行 requirements.txt 安装依赖文件,将项目代码全部拷贝到工作目录中,最后执行命令启动平台
FROM python:3.6.6-stretch
RUN apt-get update \
&& apt-get install -y --no-install-recommends \
postgresql-client \
&& rm -rf /var/lib/apt/lists/*
WORKDIR /usr/src/app
COPY requirements.txt ./
RUN pip install -r requirements.txt
COPY . .
EXPOSE 8000
CMD ["python", "manage.py", "runserver", "0.0.0.0:8000"]
- 修改 httprunner-manager 的配置文件
if DEBUG:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'HttpRunner', # 新建数据库名
'USER': 'user', # 数据库登录名
'PASSWORD': 'xxxx', # 数据库登录密码
'HOST': 'trtjk-mysql', # 数据库所在服务器ip地址
'PORT': '3306', # 监听端口 默认3306即可
}
}
STATICFILES_DIRS = (
os.path.join(BASE_DIR, 'static'), # 静态文件额外目录
)
else:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'HttpRunner', # 新建数据库名
'USER': 'user', # 数据库登录名
'PASSWORD': 'xxxx', # 数据库登录密码
'HOST': 'trtjk-mysql', # 数据库所在服务器ip地址
'PORT': '3306', # 监听端口 默认3306即可
}
}
数据库 HOST 配置的 mysql 名称,在启动 docker 时会用–link 指定到 mysql docker,这样在改变服务器地址的时候仍然可以连接到 mysql 数据库
djcelery.setup_loader()
CELERY_ENABLE_UTC = True
CELERY_TIMEZONE = 'Asia/Shanghai'
BROKER_URL = 'amqp://guest:guest@xx.xxx.xxx.xxx:5672//' # 127.0.0.1即为rabbitmq-server所在服务器ip地址
CELERYBEAT_SCHEDULER = 'djcelery.schedulers.DatabaseScheduler'
CELERY_RESULT_BACKEND = 'djcelery.backends.database:DatabaseBackend'
这里要修改一下 rabbitmq 的 ip 地址,改成宿主机地址
- Build httprunner-manager 镜像
将 dockerfile 放到项目代码同级目录,执行docker build -t django-httprunner-managerment .
- 启动 httprunner-manager 容器
docker run --name httprunner-managerment -p 8000:8000 --link trtjk-mysql:trtjk-mysql -v /root/jenkins/workspace/HttpRunner-Managerment:/usr/src/app -d --restart always django-httprunner-managerment
-v 命令可以帮助我们更新代码,不需要重新 build 容器
- 初始化数据库
这里也可以进入容器直接执行以下几条 python 命令,执行一次即可
docker exec -d httprunner-managerment bash -c "python manage.py makemigrations ApiManager | python manage.py migrate | "python manage.py createsuperuser"
- 启动 celery worker 进行异步任务
docker exec -d httprunner-managerment bash -c "python manage.py celery -A HttpRunnerManager worker --loglevel=info"这里并没有按照平台要求启动定时任务,因为后面会讲到使用 jenkins 来控制执行
5.jenkins 构建 HttpRunnerManager 平台
采用 jenkinsfile 方式持续部署平台代码,增加 webhook,在提交代码后自动部署
pipeline {
agent{
label 'master'
}
options {
//仅保留最近10次的构建记录
buildDiscarder(logRotator(numToKeepStr: '10'))
//输出时间戳
timestamps()
}
environment{
//设置Project路径
PROJECT_PATH = "${GLOBAL_WORKSPACE_PATH}/${JOB_NAME}"
}
stages {
stage('build httprunner-managerment') {
agent{
label 'db-slave-backup'
}
steps {
dir("${PROJECT_PATH}") {
sh "echo ${PROJECT_PATH}"
sh "/usr/bin/docker restart httprunner-managerment"
sh '/usr/bin/docker exec -d httprunner-managerment bash -c "python manage.py celery -A HttpRunnerManager worker --loglevel=info "'
}
}
}
}
post {
failure {
//当此Pipeline失败时打印消息
echo 'failure'
}
success {
//当此Pipeline成功时打印消息
echo 'success'
}
}
}
支持微服务架构的环境配置方法
目前我司大中台有三套环境:测试,UAT,生产,在执行接口测试的时候需要灵活的在三种环境中切换,微服务架构特点是每一个应用中心会暴露一个单独的 host,接口测试脚本会用参数化的方式配置这些 host,HttpRunner 框架自带.env 配置文件可以完美的解决 host 配置问题。但 HttpRunner-manager 的环境配置只支持一个 Base_url 生效,折中的办法是每个环境的接口用例都单独加一个配置,配置里面写好所有中心的 host 地址,但这样无形中增加了很多工作量。因此我们修改了平台代码,将所有中心 host 地址存入数据库,以服务端环境名称分组,执行接口测试脚本的时候只需要传入一个环境参数来区分不同环境
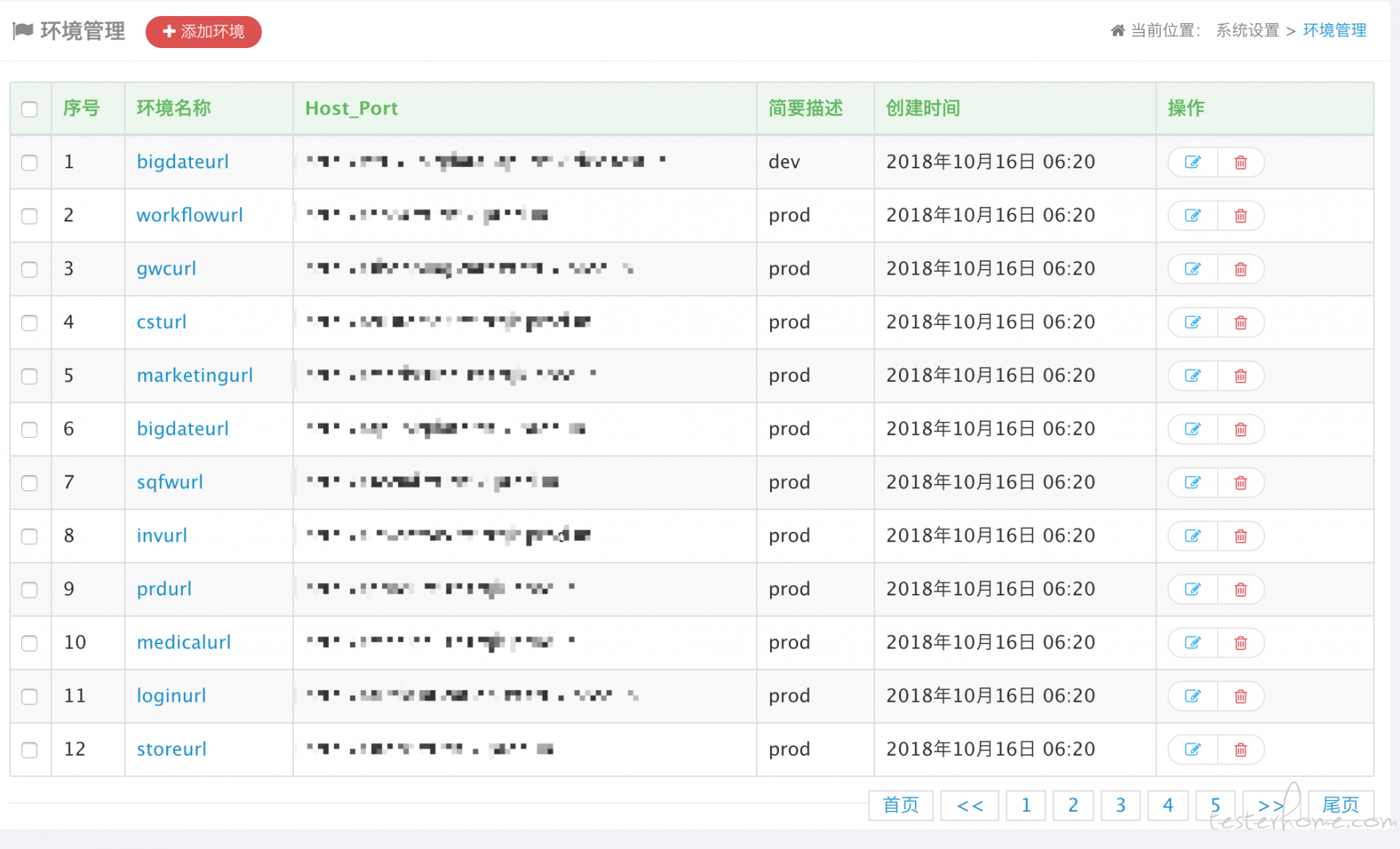
- 修改思路
HttpRunner-manager 平台在执行接口脚本的时候会把每一个用例以 yaml 的形式单独存到本地通过 Httprunner 执行。因此我们需要在存储的时候把 Url 中的 $prdUrl 这类参数解析成对应环境中完整的 host 地址。
- 在 views.py 的 run_test 函数中将所有 host 存入到 os.env 中
env_name = kwargs.pop('env_name')
envs = EnvInfo.objects.filter(simple_desc=env_name)
for env in envs:
os.environ[env.env_name.lower()] = env.base_url
- 在 runner.py 的 run_by_single 函数中将接口脚本中 host 参数 $prdUrl 解析成完整的 host 地址
jenkins 持续集成远程调用平台脚本
HttpRunner-manager 平台执行接口测试脚本支持同步任务和异步任务,异步任务使用 celery+rabbitMq 方式执行,只有异步任务会记录报告到平台中。平台本身支持创建定时任务异步执行脚本,但这样无法把接口自动化测试融入到产品持续集成流水线中,解决这个问题的方法是使用 post 命令远程触发平台执行用例,具体脚本如下:
class Run_Script():
def __init__(self):
self.cookie = self.get_cookie()
def get_cookie(self):
"""
此方法用于获取login接口中返回的cookie
:return:
:param self:
:return:
"""
Login_url = 'http://xxx.xxx.xx:8000/api/login/'
form_data = {"account": 'xxxx', 'password': 'xxxxx'}
Login_headers = {'Content-Type': 'application/x-www-form-urlencoded'}
res = requests.post(url=Login_url, data=form_data, headers=Login_headers)
cookies = "sessionid=" + res.cookies.get_dict()['sessionid']
return cookies
def post_request(self, id, env_name, report_name, receiver):
"""
此方法用于异步启动前端HttpRunner,并在前端生成报告
:param id:
:param env_name:
:param report_name:
:param receiver:
"""
payload = {"id": id, "env_name": env_name, "type": "module", "report_name": report_name, "receiver": receiver}
url = "http://xxx.xxx.xx:8000/api/run_test/"
headers = {'Content-Type': 'application/json', 'X-Requested-With': 'XMLHttpRequest', 'Cookie': self.cookie}
res = requests.post(url, json=payload, headers=headers)
print(res.text)
def query_module(self):
"""
此方法用于返回数据库中的模块id、name
:return:
"""
pro_dic = {}
module_dic = {}
# 连接数据库
mysql = Mysql_Query('xxx.xxx.xx', 'user', 'password', 'HttpRunner')
sql = 'select id,project_name from ProjectInfo'
# 返回sql影响成功的行数rows,将结果放入一个集合,等待被查询
rows = mysql.query(sql)
for id, project in rows:
pro_dic.setdefault(id)
pro_dic[id] = project
sql = 'select id,module_name,belong_project_id from ModuleInfo'
rows = mysql.query(sql)
for id, module, pro_id in rows:
if 'api' in module or 'env' in module or '环境变量' in module:
continue
else:
module_dic.setdefault(pro_dic[pro_id])
if module_dic[pro_dic[pro_id]] is None:
module_dic[pro_dic[pro_id]] = [[module, id]]
else:
module_dic[pro_dic[pro_id]].append([module, id])
return module_dic
执行接口测试的 jenkins 任务配置在产品构建成功后,执行的时候按照所有项目所有模块顺序执行,失败后发送邮件通知到测试同学,邮件通知平台自带稍微修改一下就可以用了
后话
待办事项
- 集成 locust 压测工具到平台中,增加平台压力测试能力
- 首页统计和展示所有接口性能数据
首先感谢@debugtalk和@yinquanwang两位大神,从你们的开源项目中我们学习到了很多,少走了很多弯路,在极短的时间内完成了从 Postman 工具到平台化进行接口测试的进化。感谢团队小伙伴们的支持,没有你们的参与,平台也不会这么快落地。
 。这种没法提 pr 吧?
。这种没法提 pr 吧?