AI测试 也许这有你想知道的人工智能 (AI) 测试 -- 开篇
人工智能测试
什么是人工智能,人工智能是怎么测试的。可能是大家一开始最想了解的。
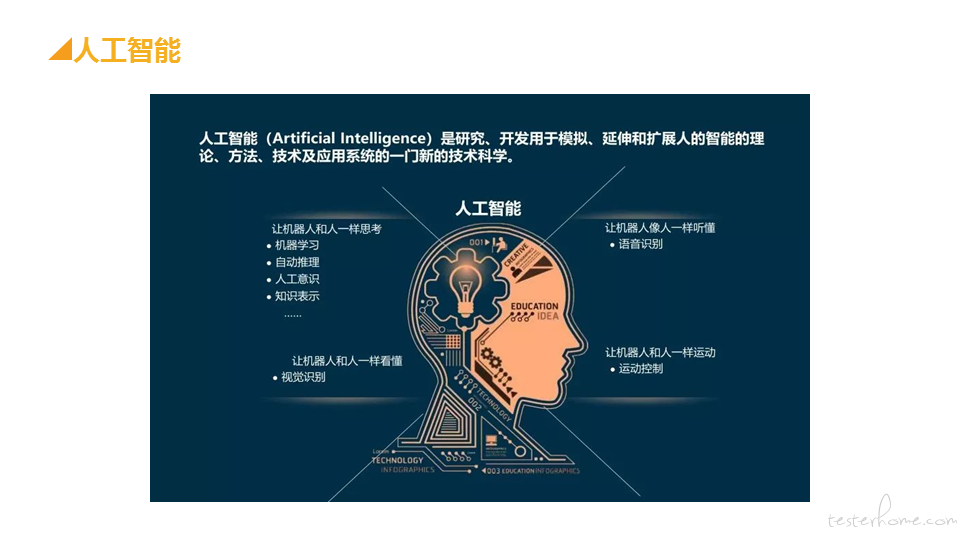
大家看图中关于人工智能的定义。通俗点来说呢,就是 让机器实现原来只有人类才能完成的任务;比如看懂照片,听懂说话,思考等等。
很多人测试的同学会问,那人工智能是怎么测试的?其实这个问题本身问的不太对。
举个例子,把 人工智能 比做 水果。如果有人问你 “水果是怎么吃的”,你可能不知道怎么回答。
在不知道是什么类型的水果,或者具体是什么水果的时候,恐怕不能很好的回答这个问题。
那正确的问法是什么,可以从具体的人工智能应用的来问:
- 机器学习项目怎么测试
- 推荐系统项目怎么测试
- 图像识别项目怎么测试
- 自然语言处理项目怎么测试。
目前应用最广泛的人工智能也是这四个类型。
测试什么
一般这些项目都要测试什么,要进行什么类型的测试。
1. 模型评估测试
模型评估主要是测试 模型对未知新数据的预测能力,即泛化能力。
泛化能力越强,模型的预测能力表现越好。而衡量模型泛化能力的评价指标,就是性能度量 (performance measure)。性能度量一般有错误率、准确率、精确率、召回率等。
2. 稳定性/鲁棒性测试
稳定性/鲁棒性主要是测试算法多次运行的稳定性;以及算法在输入值发现较小变化时的输出变化。
如果算法在输入值发生微小变化时就产生了巨大的输出变化,就可以说这个算法是不稳定的。
3. 系统测试
将整个基于算法模型的代码作为一个整体,通过与系统的需求定义作比较,发现软件与系统定义不符合或与之矛盾的地方。
系统测试主要包括以下三个方面:
1、项目的整体业务流程
2、真实用户的使用场景
3、数据的流动与正确
4. 接口测试
接口测试是测试系统组件间接口的一种测试。接口测试主要用于检测外部系统与系统之间以及内部各个子系统之间的交互点。测试的重点是要检查数据的交换,传递和控制管理过程,以及系统间的相互逻辑依赖关系等。
5. 文档测试
文档测试是检验用户文档的完整性、正确性、一致性、易理解性、易浏览性。
在项目的整个生命周期中,会得到很多文档,在各个阶段中都以文档作为前段工作成果的体现和后阶段工作的依据。为避免在测试的过程中发现的缺陷是由于对文档的理解不准确,理解差异或是文档变更等原因引起的,文档测试也需要有足够的重视。
6. 性能测试
7. 白盒测试 -- 代码静态检查
8. 竞品对比测试
如果有涉及时,可针对做竞品对比测试,清楚优势和劣势。比如 AI 智能音箱产品。
9. 安全测试
发布上线后,线上模型监控
测试数据
不管是机器学习,推荐系统,图像识别还是自然语言处理,都需要有一定量的测试数据来进行运行测试。
算法测试的核心是对学习器的泛化误差进行评估。为此是使用测试集来测试学习器对新样本的差别能力。然后以测试集上的测试误差作为泛化误差的近似。测试人员使用的测试集,只能尽可能的覆盖正式环境用户产生的数据情况。正式环境复杂多样的数据情况,需要根据上线后,持续跟进外网数据。算法模型的适用性一定程度上取决于用户数据量,当用户量出现大幅增长,可能模型会随着数据的演化而性能下降,这时模型需要用新数据来做重新训练。
上线只是完成了一半测试,并不像 APP 或者 WEB 网站测试一样,测试通过后,发布到正式环境,测试工作就完成了。
测试集如何选取很关键,一般遵循两个原则:
- 测试集独立同分布
- 测试数据的数量和训练数据的比例合理
测试集独立同分布
不能使用训练数据来做为测试数据,此为独立。
测试数据需要和训练数据是同一个分布下的数据,此为分布。
举个例子,训练数据中正样本和负样本的分布为 7:3,测试数据的分布也需要为 7:3,或者接近这个分布,比较合理
测试数据的数量和训练数据的比例合理
当数据量比较小时,可以使用 7 :3 训练数据和测试数据
(西瓜书中描述 常见的做法是将大约 2/3 ~ 4/5 的样本数据用于训练,剩余样本用于测试)
或者 6: 2 : 2 训练数据,验证数据和测试数据。
如果只有 100 条,1000 条或者 1 万条数据,那么上述比例划分是非常合理的。
如果数据量是百万级别,那么验证集和测试集占数据总量的比例会趋向于变得更小。如果拥有百万数据,我们只需要 1000 条数据,便足以评估单个分类器,并且准确评估该分类器的性能。假设我们有 100 万条数据,其中 1 万条作为验证集,1 万条作为测试集,100 万里取 1 万,比例是 1%,即:训练集占 98%,验证集和测试集各占 1%。对于数据量过百万的应用,训练集可以占到 99.5%,验证和测试集各占 0.25%,或者验证集占 0.4%,测试集占 0.1%。

一般算法工程师会将整个数据集,自己划分为训练集、验证集、测试集。或者训练集、验证集 等等。(这里的测试集是算法工程师的测试数据)
算法工程师提测时,写明自测时的准确率或其他指标。测试人员另外收集自己的测试集。
测试数据可以测试人员自己收集。或者公司的数据标注人员整理提供。或者爬虫。外部购买。
测试人员可以先用算法工程师的测试集进行运行测试查看结果。再通过自己的测试集测试进行指标对比。
测试用例思考点
下篇继续
