序列模型 (RNN)
之前我们介绍了 CNN(卷积神经网络) 来处理计算机视觉问题,CNN 有效解决了 DNN 在图片识别领域的不足。 让深度学习可以应用在更加广泛的领域中。 但是这样还不够,我们希望它能够在 NLP(自然语言识别) 等领域也能够发挥出很强的能力。这时候出现的问题就是我们的神经网络中的任何神经元都是独立的,没有考虑到上下文依赖。 比如如果我们想做一个文本分类或者是机器翻译应用。比如我们想翻译如下的一句话:This is an apple。 我们想把它翻译成英文。如果按照之前学习的 DNN 模型去训练模型可能就是下面这个样子的。
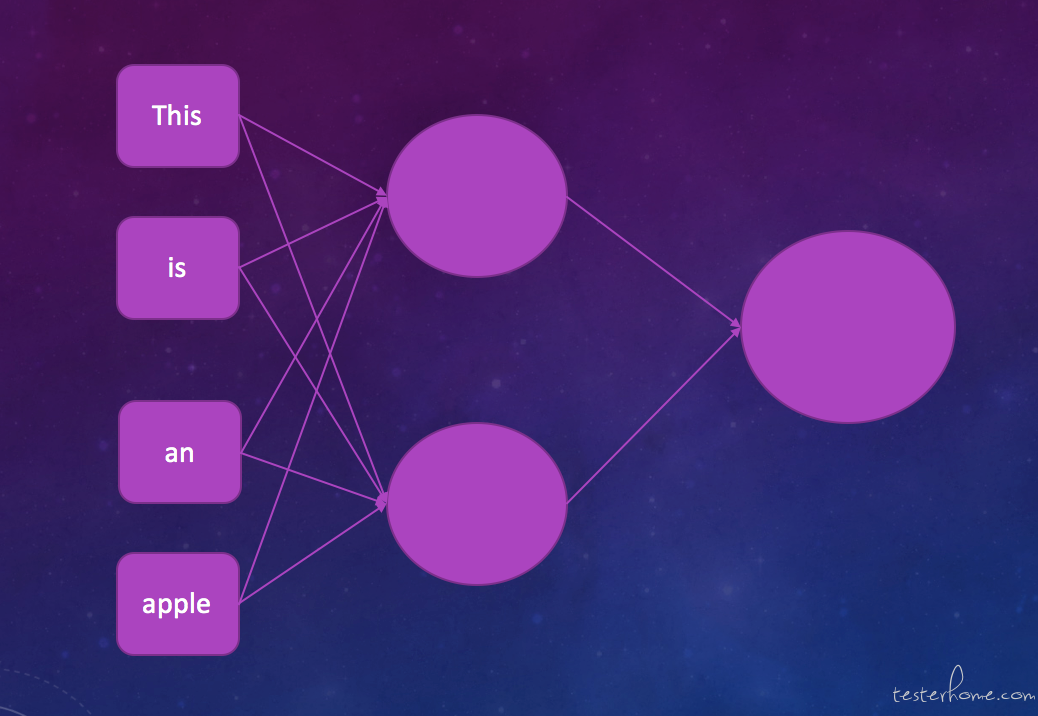
我们把每一个单词都作为特征输出到模型中训练一个模型。 但是这里的问题就在于在这种模型算法中,特征与特征是相互独立的。他们之间完全没有任何关系。 而我们的自然语言是有上下文依赖的。单词与单词之间不同的组合,甚至句子不同的组合都会产生不同的含义。为了解决这种问题,循环神经网络 (RNN) 应运而生。
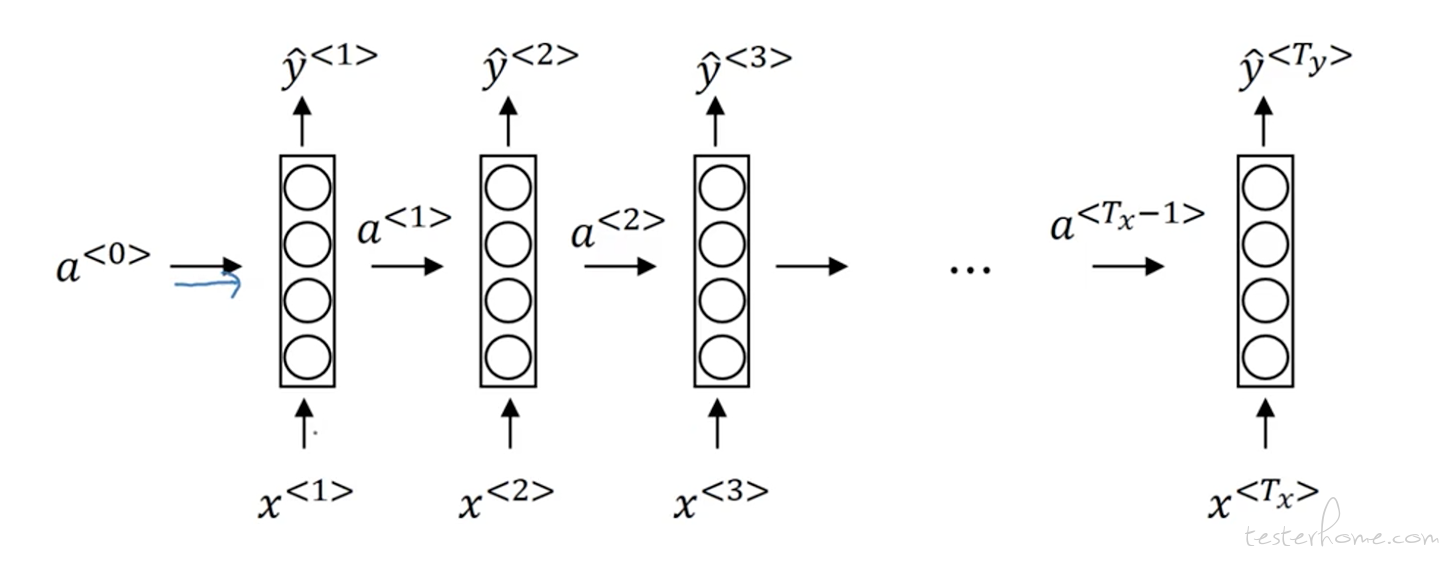
OK,我们假设一种现在商业中非常常见的场景 -- 情感分类。 通过用户的评论判断出对用户对一个事物的好感程度。 比如电影的评论和店铺的评论。 然后将好感度按不同的程度分类。比如,从一星到 5 星。 为了解决这样一个问题,就出现了上图一样的循环神经网络,之后都简称 RNN。 RNN 与其他神经网络不同的是,在训练中,我们的特征是有时序状态的。并且计算当前特征的神经元,除了有当前特征这个输入外,还会有之前时间序列上的特征的输入。 也就是说,模型会记忆之前的特征,做完处理后输入到当前的神经元中。 这样我们的模型就可以处理上下游依赖了。 就像上面的图一样, x 代表我们的输入特征,神经网络呈现时序性, 处理完上一个特征后,带着计算出的激活值输入到下一个神经元。 下一个神经元使用之前的计算结果和当前的特征来预测新的结果。 当然很多时候我们不仅要考虑前文, 也要顾及后果。 文本中之后的单词也会对当前的内容产生影响。 所以我们也就有了双向循环神经网络--BRNN。
词嵌入
简单说说词嵌入。 词嵌入在 NLP 中占有非常大的意义。 在处理自然语言中,我们需要一个很庞大的词典和语料库。在训练 RNN 的时候,我们要把每一个特征与词典中的某一个次对应,只有出现在词典上,我们才能知道这个词有什么样的意义。 单这时候我们还是遇到了一些问题。 比如我们有一句英文:This is an apple juice。 假如我们的 RNN 在预测 juice 这个单词的时候成功的判断出了这个词出现的概率。 那之后在出现相关的语境的时候, 比如:This is an orange juice。 在遇到了 orange 的时候,我们希望模型能够让模型判断 apple 和 orange 是一个类似的东西,从而判断出后面的单词为 juice 的概率很大。 但这时候纯 RNN 就做不了了,虽然 RNN 能够记忆住上下文,但是每个次的关联是判断不出来的。 所以这时候词嵌入出现了。
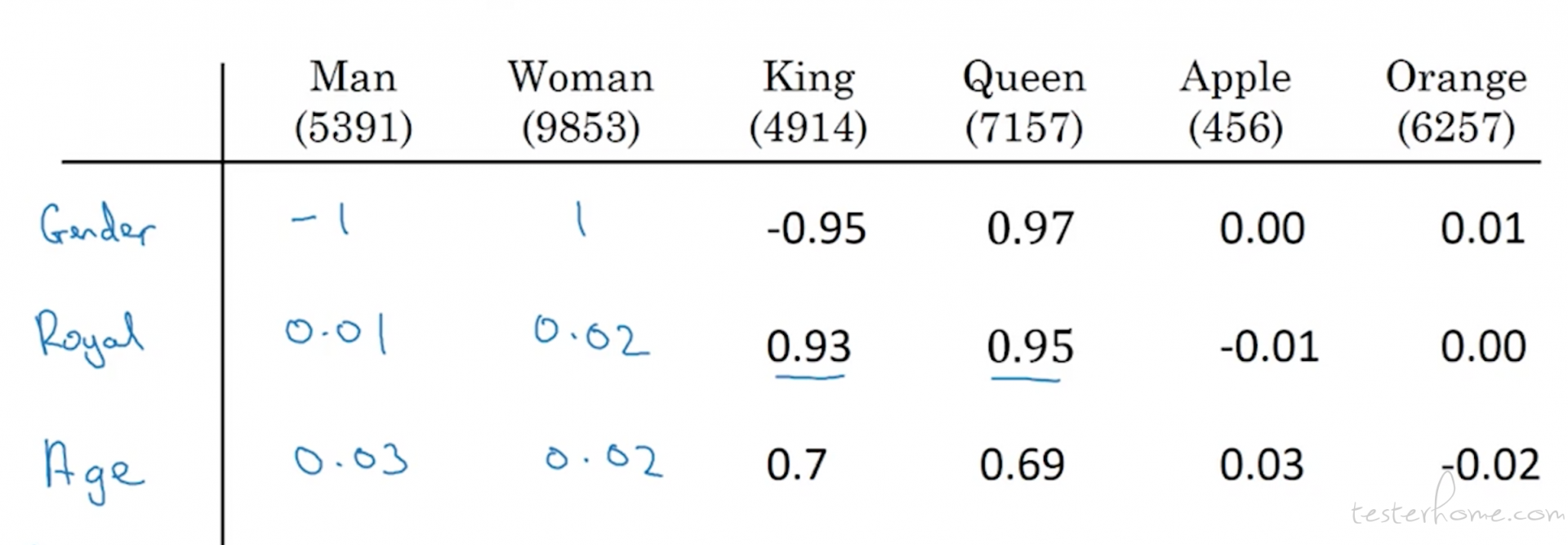
词嵌入有点像是为每一个词抽取出了特征。如上图中,我们抽取了一个 300 维的词向量。这就是词的 300 个特征。 比如一个词在性别上的关联性, 如 Men 何 woman 跟性别关联性很高。所以这两个词在这个维度上就接近 1. king 和 queen 也跟性别很相关所有他们的值也很高。 但是像 apple 这种完全没什么关系的在这个维度的取值就基本上是 0. 相反在食物这个维度上,apple 的取值就很高。其他的词接近 0. 我们通过这种方式组织起了 300 维的词向量辅助我们训练模型。 所以在 RNN 中多出了一个嵌入层, 让我们 one-hot 编码的词特征与词向量做做乘法。
