前言
最近准备给新人培训写一些机器学习尤其是深度学习相关的资料。毕竟我们的产品都已经开始涉及 NLP 和知识图谱了 (话说我的帖子更新的速度跟不上产品研发速度了 ,到现在只写到了 CNN 部分 ) 所以为了能让新人更好更快的熟悉我们的业务。所以整理了目前我所知道的机器学习所应用的各种场景。 这其中包括金融领域常见的反欺诈,互联网常见的推荐系统,实时预测,场景分类。当然也包括了图像识别,NLP,语音识别等等。 也会用尽量说人话的方式讲一下他们的原理。 尽量让人知其然知其所以然。里面有些内容可能之前的帖子讲到过,但还是请大家耐心看完。
,到现在只写到了 CNN 部分 ) 所以为了能让新人更好更快的熟悉我们的业务。所以整理了目前我所知道的机器学习所应用的各种场景。 这其中包括金融领域常见的反欺诈,互联网常见的推荐系统,实时预测,场景分类。当然也包括了图像识别,NLP,语音识别等等。 也会用尽量说人话的方式讲一下他们的原理。 尽量让人知其然知其所以然。里面有些内容可能之前的帖子讲到过,但还是请大家耐心看完。
什么是人工智能
我们先说说什么是人工智能,毕竟我们想要测试一个东西就要先理解它么。 不严谨的说,现阶段的人工智能是:大数据 + 机器学习。 那为什么是不严谨的说呢,因为人工智能的范畴还挺大的,机器学习是其中的一个子集, 现在大部分人把机器学习和人工智能划等号,因为我们目前在人工智能领域产生了价值的项目,主要是机器学习带来的。 我们又说这是现阶段对人工智能的定义, 因为人工智能还是在迅猛发展的,上个世纪 70 年代的时候人们对人工智能的定义还是专家系统呢, 所以人类的对人工智能的理解也是不停的在进步的,说不定过个几十年人工智能的实现方式就不是机器学习了。
我们举一个信用卡反欺诈的例子, 以前的时候在银行里有一群业务专家, 他们的工作就是根据自己的知识和经验向系统中输入一些规则。例如某一张卡在一个城市有了一笔交易,之后 1 小时内在另一个城市又有了一笔交易。这些专家根据以前的经验判断这种情况是有盗刷的风险的。他们在系统中输入了 1 千多条这样的规则,组成了一个专家系统。 这个专家系统是建立在人类对过往的数据所总结出的经验下建立的。 我们可以把它就看成一个大脑,我们业务是受这个大脑控制的。但这个大脑是有极限的,我们要知道这种规则从 0 条建立到 1 条是很容易的,但是从几千条扩展到几千零一条是很难的。 因为你要保证新的规则有效,要保证它不会跟之前所有的规则冲突,所以这很难,因为人的分析能力毕竟是有限的。 我听说过的最大的专家系统是百度凤巢的,好像是在 2010 年的时候吧,他们的广告系统里有 1W 条专家规则。但这是极限了,它们已经没办法往里再添加了。 所以说这是人脑的一个极限。 后来呢大家引入机器学习, 给机器学习算法中灌入大量的历史数据进行训练, 它跟人类行为很像的一点就是它可以从历史数据中找到规律,而且它的分析能力更强。 以前人类做分析的时候,可能说在反欺诈的例子里,一个小时之内的跨城市交易记录是一个规则,但如果机器学习来做的话,它可能划分的更细,例如 10 分钟之内有个权重,10 分钟到 20 分钟有个权重,1 小时 10 分钟也有个权重。 也就是说它把这些时间段拆的更细。 也可以跟其他的规则组合,例如虽然我是 1 小时内的交易记录跨越城市了,但是我再哪个城市发生了这类情况也有个权重,发生的时间也有个权重,交易数额也有权重。也就是说机器学习能帮助我们找个更多更细隐藏的更深的规则。 以前银行的专家系统有 1000 多条规则,引入了机器学习后我们生成了 8000W 条规则。 百度在引入机器学习后从 1w 条规则扩展到了几十亿还是几百亿条 (我记不清楚了)。 所以当时百度广告推荐的利润很轻易的提升了 4 倍。 我们可以把专家系统看成是一个比较小的大脑,而机器学习是更大的大脑。 所以说我们叫它机器学习,是因为它像人类一样可以从历史中库刻画出规律,只不过它比人类的分析能力更强。 所以在网上有个段子么,说机器学习就是学出来海量的 if else, 其实想想也有道理,套路都是 if 命中了这条规则,就怎么么样的,else if 命中了那个规则,就怎么怎么样的。 人类的分析能力有限么,专家系统里人类写 1 千,1w 个 if else 就到头了。 但是机器学习给你整出来几百个亿的 if else 出来。
什么是模型
那接下来我们就聊聊什么是模型了。 模型这个词大家肯定都听过,但它到底是个什么东西相信很多人都是懵的,因为它太抽象了,好像很多领域里都有这个词, 我刚入职的时候一直都在问模型是什么。 都说机器学习算法训练出来的是模型,我们要针对这个模型做测试,但这玩意到底是个什么东西。 我们继续不严谨的说,模型就是个数据库,里面存储的就是我们之前说到的规则和这些规则对应的权重。 我们应用模型的时候怎么做? 其实就是拿着新数据到模型这个数据库里找规则,把匹配的所有规则和他们的权重做乘法并累加在一起,就是我们最后得到的预测值。 我们外围调用的系统都是根据这个预测值展开的。假如说我要给客户做定价,那把客户的数据传过来,看看这个数据符合哪些规则,然后根据规则的权重算出一个预测的价格回来。
监督学习与无监督学习
我们上面举例的都是监督学习,同时监督学习现在是最能产生商业价值的学习方式。 那什么是监督学习,什么是无监督学习呢? 区别就在于 label(也叫目标值或者预测值)。 什么是 label 呢? label 是我们的样本数据中的一个字段。 比如我们在反欺诈场景中,数据有很多的字段,比如用户的资产,年龄,职业,收入,性别,学历,交易发生的时间,金额等等,但最后一个字段表明了这份数据是否是欺诈行为,取值只有两个,true 或者 false。 我们在机器学习中使用的数据都是历史数据, 是在过去已经发生过的事件。我们说机器学习是一个从历史中学习规律的事情,你必须告诉算法这份数据的答案,它才能学习到其中的规律。 所以我们喂给机器学习算法的历史数据是已经知道了答案也就是知道了这个数据是否发生了欺诈行为的数据。我们有一个 label 值来指导和监督算法来学习这个规律,所以我们说他是监督学习。 那什么是无监督学习呢,就是数据里没有 label 的。比如 k-means 算法。它的目的就是给数据学习出 label 来。主要用于我们事先不知道有多少分类的场景下。我们这里主要说监督学习,非监督学习的东西暂不涉及了。
逻辑回顾与预测场景
刚才讲的东西偏业务,主要让大家知道机器学习是在做什么,接下来我讲讲更偏原理的东西,以帮助我们理解以后的测试场景, 大家不用懂担心听不懂, 我还是尽量说人话。 我们讲讲逻辑回顾的原理 ,为什么讲逻辑回归呢,因为它是最简单但也是最常用最重要的机器学习算法。 从逻辑回归可以扩展出很多的应用,使用不同的激活函数它既可以做分类问题,也可以做回归问题, 现在非常火的深度学习是什么? 其实就是个多隐藏层的神经网络, 那神经网络呢?神经网络中的隐藏层每一个神经元都是一个逻辑回归,所以我们说逻辑回归是最重要的一个算法。接下来我们看看它的函数。
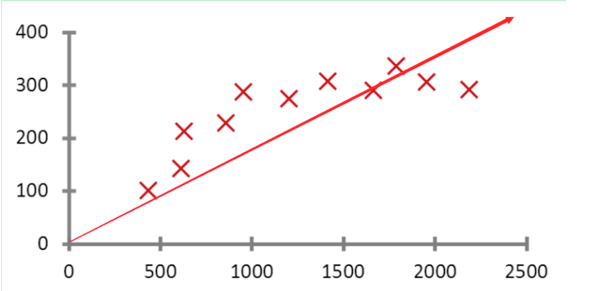
假如我们有一个预测房价的场景,为了简化说明假设我们只有面积这一个特征,上面这个函数的坐标图。 公式是:y=wx+b, 其中 y 是预测值,x 是特征 (也就是我们的规则),w 是特征的权重,b 是偏差项。我们说要预测房价该怎么做呢? 其实它就是求一条直线,让我们根据这条直线算出的预测值跟所有真实的这些点的误差最小。所以我们说它在学习什么? 学习的主要就是 w 和 b 的值。我们要求一个 w 和 b,让预测值跟真实值的误差最小。 所以在模型训练的过程中,我们会根据某种规则不停的改变 w 和 b 的值。 我们训练多少轮,就会改变多少次 w 和 b 的值。直到找到最合适的 w 和 b 的值,让预测值和真实值误差最小。这就是它整个的训练过程。上面说我们只有一个特征,如果有 n 个特征呢? 公式就变成了 y= w1*x1+w2*x2+w3*x3......wn*x* +b, 只要你的规则,也即是特征 X 足够多,你就有越多的依据来进行预测。 所以我们说机器学习是基于大数据的,数据量越大,特征越多,我们的模型效果就越好。 我们刚才说模型是个数据库,里面存储的是所有的特征和他们的权重,在这里大家就知道了存放的就是 x 和对应的 w, 当有新数据来做预测的时候就是用这个公式来计算预测值的. 当然这是一个线性回归的例子,我们把做这种预测某一个值的算法叫做回归算法,它的应用场景有很多比如外卖或者网约车场景下预测抵达时间等。 当然了之前网上特别火的一个事件 -- 大数据杀熟。也是我们典型的例子, 差异化定价在机器学习领域并不罕见。 就是根据用户的信息预测出一个用户可以承受的最高价位,以达到利益最大化的目的。
分类问题
那我们如何做分类问题呢,假如说人脸识别,要判断我和一张照片是不是一个人,它应该告诉我两个值,0 或者 1. 来告诉我这条数据是正例,还是负例。 所以我们引入了一个叫 sigmod 的激活函数,大家不用知道它的原理,只需要知道它能把我们的预测值转换成 0~1 中的数值。 假如说把我和照片的信息输入到模型中,它返回一个数值是 0.8. 意思是这个人有 80% 的概率跟照片是同一个人。 所以通过这个激活函数我们就把预测值转换了一个概率值。 我们外围系统调用的时候会根据这个概率值做一些处理。 比如说我们设置一个阈值是 0.9。 但凡是预测值大于 0.9 的我们判断为正例,小于 0.9 的我们判断为负例。 这样我们把一个回归问题变成了一个二分类的问题。 这个线性回归模型,也就变成了逻辑回归。 所以说我面试的时候,比较喜欢问候选人逻辑回归为什么是分类算法而不是回归算法。 原因就在这里了, 它基于线性回归,但加入了 sigmod 激活函数后就变成了做 2 分类问题的逻辑回归。 如果你再换个激活函数 softmax,它就变成一个多分类算法了。 那么多分类的图大概是下面这个样子的。
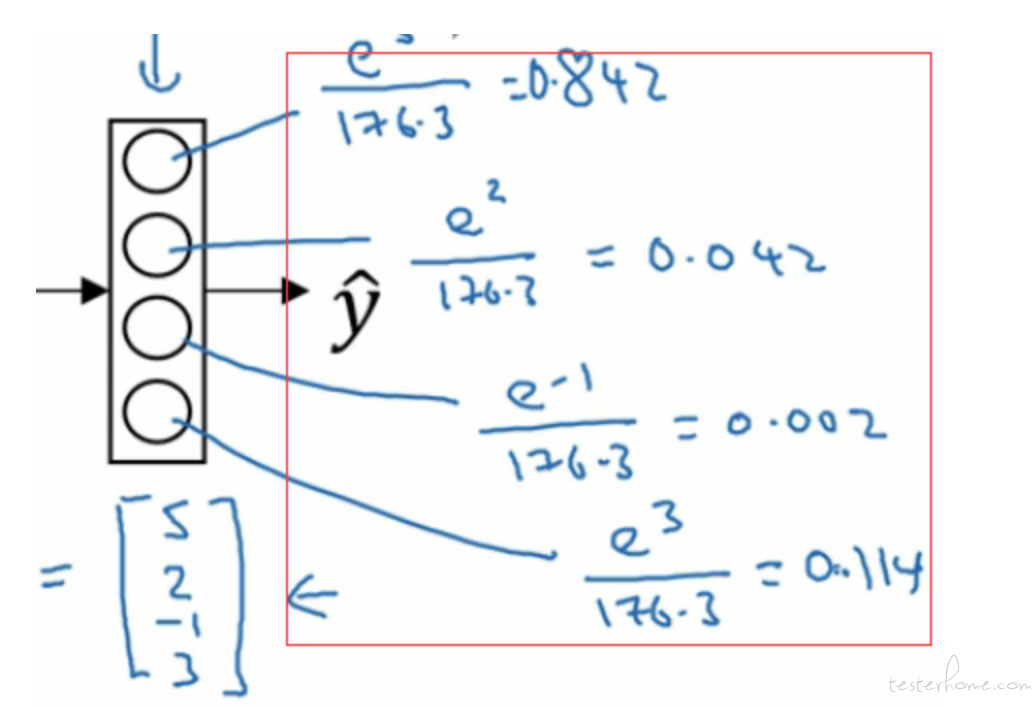
2 分类场景下,我们的算法是输出一个 0~1 的值,代表着属于正例的概率。 那么多分类下,算法输出的是多个值,比如 4 分类场景,算法输出的是样本属于 4 个类别的概率。 比如我们的 4 分类场景是识别:猫,狗,兔子,乌龟。 那么一个样本输入到算中,输出的就是类似: 猫--20%,狗--20%, 兔子--20%, 乌龟--40% 这样的概率。
分类问题的业务场景
我再最开始的时候讲过反欺诈这种很典型的分类业务场景。 现在来讲一讲由 2 分类场景衍生的一个很常见的业务场景 ---- 推荐系统。比如视频推荐,我们一般在浏览视频网站的时候,推荐系统都会根据用户信息推荐一些用户比较感兴趣的视频。大家可能会觉得比较奇怪,这怎么会是一个 2 分类场景呢? 2 分类模型要怎么处理推荐问题呢?我们在训练模型的时候,使用用户是否点击了视频作为指导我们训练模型的目标值,预测结果只有两种,要么点击了,要么没有点击。那么 2 分类模型输出的就是用户点击某个视频的概率,这样我们就可以根据这个特点来完成推荐系统的场景。举个例子,假如我们有一个用户, 同时我们也有 2000 个视频候选集,我们分别用这些视频和用户分别用模型算出 2000 个概率,意思是每个视频用户会点击的概率。然后从高到低排序。把排行前面的视频推荐给用户。 所以我们就把一个推荐系统的问题转换为一个分类问题。只不过这里我们不设置阈值了而已。当然某些情况下也会有阈值,比如如果所有视频的点击率都太低了,我们认为用户就不可能会点击任何视频。那这时候就不要发送任何视频去影响用户体验了。
当然分类问题跟我们的生活息息相关,比如贷款时的信贷分析,比如各种安全 app 的拦截欺诈短信和电话等等。各种机器学习的应用已经无声的侵入到了我们生活的方方面面中。