本帖已被设为精华帖!
这本书是 17 年初印刷的,其中内容至少是 16 年写的了,是基于 5.6 版本的(现在 MySQL 已经出 5.7 了,声称性能又大幅提高)。
我本身是 17 年中买的书,第一次 17 年精读了近 2 个月(423 页),第二次今年 3 月读了近 2 个礼拜。
一般来说,业务测试,自动化测试,测试开发是基本不会怎么接触数据库的,但性能测试不这样。
水平有限难免有错误,如看到错误还望告知
本文目标
提高测试在参与技术讨论时的地位,为碾压开发做技术储备。
现在网上对于 MySQL 的文章很多很多,大家也都能看个大概,我这里只说书上的关键知识点。
这里不解释那么详细,详细还是直接买书来读。
MySQL 架构图
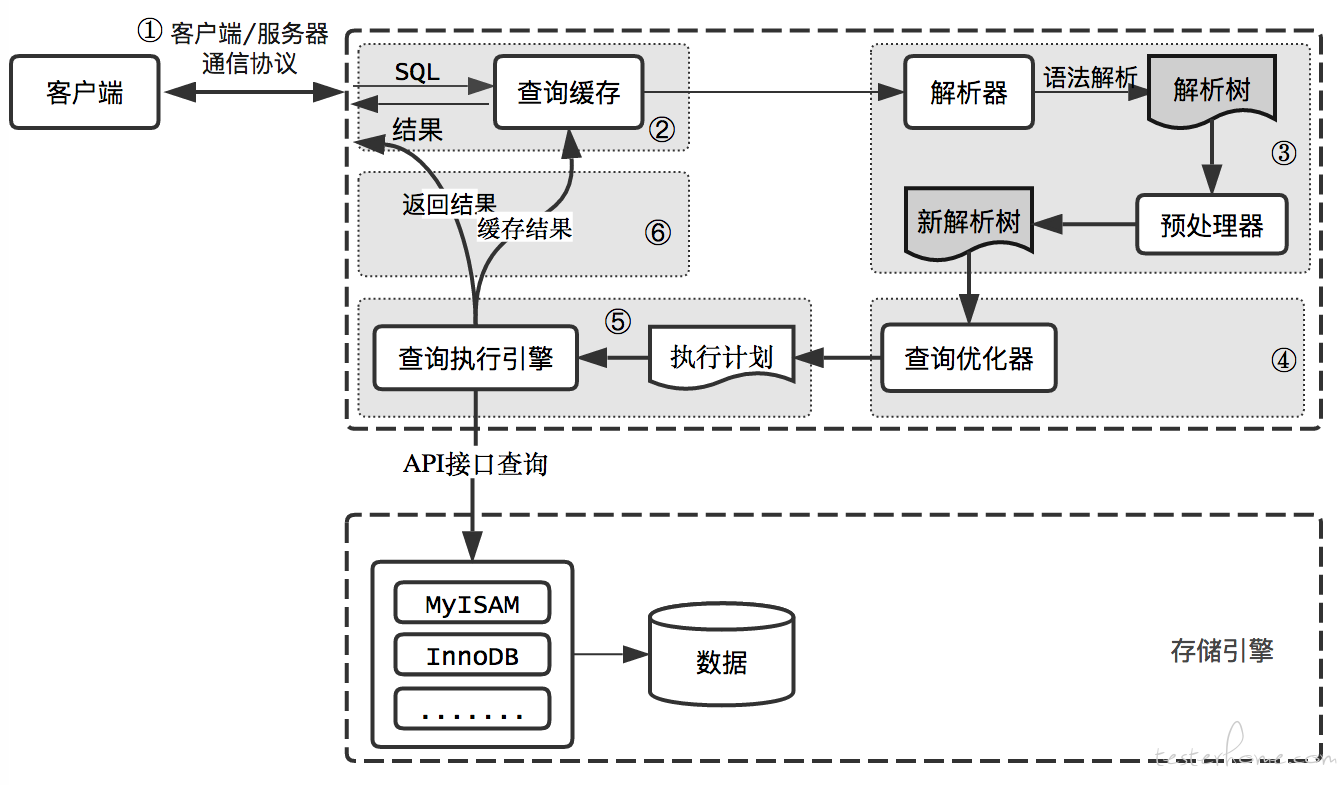
这图是个大概的意思,我们要知道:
- InnoDB 是 MySQL 的默认搜索引擎,所以图中的一些功能是两者都涉及的,并不是像图中划分的这么清晰的,比如缓存部分,解释器部分。
- MySQL 框架相当于规定了接口,InnoDB 提供了实现。
- 存储引擎主要工作就是管理磁盘上保存的数据,主要包括什么格式怎么组织的保存,怎么样才能读写的更快(磁盘和内存),数据安全。
- 对应到 InnoDB,就是内存都存了啥,索引的原理作用,各种配置,redo/undo 日志,锁,事务,和硬件的适配等。
关键名词
共享表空间和独立表空间(tablespace)
- 共享表空间: Innodb 的所有数据保存在一个单独的表空间里面,而这个表空间可以由很多个文件组成,一个表可以跨多个文件存在,所以其大小限制不再是文件大小的限制,而是其自身的限制。从 Innodb 的官方文档中可以看到,其表空间的最大限制为 64TB,也就是说,Innodb 的单表限制基本上也在 64TB 左右了,当然这个大小是包括这个表的所有索引等其他相关数据。
- 独立表空间:每个表一个空间
- 如果开启了独立表空间,其中存的也只是数据,索引和插入缓存 Bitmap 页(标记辅助索引页所用的空间),其它数据,如回滚(undo)信息,插入缓存索引页,系统事务信息,二次写缓冲等还是放在共享表空间中。
- 表空间又由段(segment),区(extent),页(page),行(ROW)组成。
- 区一个为 1MB,默认页是 16KB,每页最多存放 7992 行记录,存在行溢出(即数据太大一行装不下)。
脏页
内存页中的数据是最新的,还没来得及刷新到磁盘上。
聚集索引,非聚集索引(辅助索引,覆盖索引),联合索引,平衡二叉树,B+ 树
略
Cardinality 值
- 表示索引中不重复记录数量的预估值。
- 是存储引擎层统计的。
- 随机取 8 个叶子节点进行分析。
- 是一个预估值,Cardinality/n_row_in_table 应该尽可能的接近 1.
- INSERT 和 UPDATE 会更新它。
索引提示(INDEX HIT)
略
binlog
- 记录了 MySQL 数据库执行更改的所有操作,不包括 select,show 等这类操作,因为没有修改数据。
- 主从备份使用的就是 binlog
- 默认不是开启的。开启性能下降 1%。
- 有三种格式,STATEMENT,ROW 和 MIXED,主备使用 ROW。
- ROW 格式文件很大,STATEMENT 保存的是逻辑语句。
触发器与约束(外键约束)
- 最多为一个表建立 6 个触发器(INSERT,UPDATE,DELETE 的 BEFORE 和 AFTER 各定义一个)
- 外键建立时自动为改列建立一个索引。
- 互联网公司(如 58 到家)提到的 DBA 军规 (https://mp.weixin.qq.com/s/YfCORbcCX1hymXBCrZbAZg) 中,是禁止使用触发器,视图,外键的。
视图(物化视图)
MySQL 不直接支持物化视图,Oracle 支持,SQL Server 叫索引视图。
分区表
- 5.7 开始支持全局分区,即不再是分区中既存放了数据又存放了索引。
- 分区可能会给某些 SQL 语句带来性能提高,但主要是数据库高可用性的管理。
全文检索(倒排索引)
- 为提高并行性能,有 6 张 Auxiliary Table(辅助表),目前每张表根据 word 的 Latin 编码进行分区。
- FTS Index Cache(全文检索索引缓存),用来提高性能,使用红黑树结构。
- 文档的 DML 操作实际并不删除索引中的数据(缓存和磁盘都是),想反还会在对应的 DELETED 表中插入记录。但是允许手工彻底删除,命令是 OPTIMIZE TABLE。
锁,死锁
- 两种标准行级锁共享 S Lock 和 排他 X Lock,只有 S S 兼容。
- InnoDB 对行的查询都是采用了 Next-Key Lock 算法,锁定一个范围,并且锁定记录本身。仅在查询的列是唯一索引的时候,Next-Key Lock 算法会降级成 Record Lock 即单个记录行上的锁。
- Next-Key Locking 机制避免了 Phantom Problem(幻象问题),即 MySQL 是事务的第三高的默认级别,就达到了 Oracle Serializable 级别才能避免的幻象问题。
- 事务由低到高 4 个级别:Read uncommitted(脏读/读不提交),Read committed(读提交/不可重复读,读已经提交的数据,Oracle,SQL Server 默认级别),Read Repeatable(MySQL 默认级别但是其能达到序列化的层次。丢失更新,就是一个事务的更新操作会被另一个事务的更新操作覆盖),Serializable(序列化/阻塞)。
- 死锁会马上回滚一个事务,所以如果接到 1213 错误,其实并不需要对其进行回滚(死锁自动就回滚了)。
- 隔离级别越低,事务请求的锁越少保持锁的时间就越短。
多版本并发控制(Muliti Version Concurrency Control,MVCC)
略
事务
- ACID(Atomicity 原子性,Consistency 一致性,Isolation 隔离性,Durability 持久性)。
- 事务可以有保存点,即部分回滚事务。
- 嵌套事务,链事务,分布式事务
- 提供了 XA 事务的支持,另外在使用分布式事务时,必须设置隔离级别是 SERIALIZABLE。
- 分布式事务使用两端提交方式:1.所有参与全局事务的节点都开始准备。2.事务管理器告诉资源管理器是回滚还是提交。如果任何一个节点不能提交,则所有的节点都被告知要回滚。
- 通常来说,都是通过编程语言来实现分布式事务的操作的。
关键技术
插入缓冲(Insert Buffer)
- 针对辅助索引的。
- 数据由于主键是递增的,是顺序的,但是辅助索引就不是顺序的了。辅助索引先插入缓存中,再刷新到磁盘上避免磁盘随机读。
- 是仅一棵 B+ 树(不是索引的,是 Insert Buffer 的 B+ 树)。
- 插入数据时,更新索引,数据的地方很多的,索引在内存中也有好几处地方保存,上述仅对插入缓存的解释。
两次写(doublewrite)
- 提高可靠性,有效避免正在将 MySQL 进程内存数据刷新到磁盘时的进程宕机导致的数据丢失问题。
- 写数据时,不仅写到 MySQL 进程的内存中,还写到进程外的内存中,同时分两次一次一 MB 写到共享表空间的磁盘上。
自适应哈希索引(AHI)
- 索引一般很大, 内存中也保存不下,所以 AHI 是优化查询的有效手段。
- B+ 树索引是文件,是保存在磁盘上的,在查询数据时,会先读表所在的索引根节点(根节点是常驻内存中的), 接着再根据二分查找法依次查找索引,并将索引保存在指定内存空间中,直到找到目标索引,目标数据为止。
- AHI 和上面的 B+ 树索引保存在内存中的过程是两码事。
- InnoDB 会自动监控各索引页的查询,如果认为可以带来速度提升,则自动为某些热点页建立哈希索引。
- AHI 带来的额外消耗就是查询时,要先去查 AHI 看有没有,再查索引内存,磁盘等。
- AHI 是默认开启状态,是能禁用的。
异步 IO(AIO)
- InnoDB 引擎用其来处理磁盘操作。
- 书中提到,Mac OSX 系统没有提供 AIO,有待确认。
- 官方说法,速度提高 75%
- 磁盘写入全部是 AIO 完成,read ahead 方式读取是 AIO 完成。
刷新邻接页
- 当刷新一个脏页时,会检测其所在区的所有页,如果是脏页,则一起刷新。
- 通过 AIO 可以将多个 IO 写入操作合并成一个 IO 操作。
- 固态硬盘推荐关闭此特性。
Online DDL
- 5.6 开始支持,允许辅助索引创建的同时,还允许同时进行其他如 INSERT,UPDATE,DELETE 这类 DML 操作。
- 原理是执行创建或者删除操作的同时,将 INSERT,UPDATE,DELETE 这类 DML 操作日志写入到一个缓存中。
Multi-Range Read(MRR)
- 使数据访问变得较为顺序,在查询辅助索引时,首先根据得到的查询结果,按照主键进行排序,并按照主键排序的顺序进行书签查找。
- 减少缓冲池中页被替换的次数。
- 批量处理对键值的查询操作。
- 性能提高 400%。
Index Condition Pushdown(ICP)
- 在索引取出时,就会进行 WHERE 条件的过滤,然后再去获取记录。
- 性能提高 23%
redo(重做日志)
- 用来实现事务的持久性。
- 当事务提交时,必须先将事务的所有日志写入到重做日志文件进行持久化,待事务 COMMIT 操作完成才算完成。
- 因为其是物理日志,所以回复的速度比逻辑日志如 binlog 要快很多。(应该是针对 STATEMENT 格式的 binlog)。
undo(回滚日志)
- redo 存在重做日志文件中,但是 undo 存放在数据库内部的一个特殊段(segment)中,这个段成为 undo 段,存在共享表空间中。
- undo 是逻辑日志,所以在数据结构和页本身在回滚之后可能会大不相同。
- undo log 也会产生 redo log,undo log 也需要持久性的保护。
书中金句
- B+ 树索引本身并不能找到具体的一条记录,能找到只是该记录所在的页,数据库把页载入到内存,然后通过 Page Directory 再进行一次二叉查找。
- 向 NOT NULL 字段插入一个 NULL 值,会将其更改为 0 再进行插入。
- 索引太多,性能会受到影响。
- 聚集索引不是代表数据的物理顺序,是数据的逻辑顺序。
- explain 中,Using index 就是代表了优化器进行了覆盖索引的操作。
- 人们总认为行级锁总会增加开销,实际上,只有当实现本身会增加开销时,行级锁才会增加开销。InnoDB 引擎不需要锁升级,因为一个锁和多个锁的开销是相同的。
- MyISAM 是表锁设计,自增长不用考虑并发插入的问题。InnoDB 自增长列必须是索引,同时必须是索引的第一个列。
- redo log 基本上都是顺序写的,undo log 是需要进行随机读写的。
- fsync 的效率取决于磁盘的性能,因此磁盘的性能决定了事务提交的性能,也就是数据库的性能。
- 1.重做日志是在 InnoDB 存储引擎层产生,而 binlog 是在 MySQL 数据库的上层产生的。2.binlog 是一种逻辑日志,其对应的是 SQL 语句,而 redolog 是物理格式日志,记录的是每个页的修改。3.binlog 只是在事务提交完成后进行一次写入,而 redolog 在事务进行中不断的被写入。
- 有人错误的认为只要将 binlog 的日志格式设置成 ROW,那么 binlog 也是幂等的,这是错误的。INSERT 操作在 binlog 中就不是幂等的,重复执行可能会插入多条重复的记录,而 redolog 是幂等的。
- TRUNCATE TABLE 是 DDL,但是和整张表 DELETE 不同,它是不能回滚的(这和 SQL Server 不同)。
- 大部分用户质疑 SERIALIZABLE 有性能问题,但是有书介绍,SERIALIZABLE 开销几乎一样,甚至更优!
- 事务提交时,先写二进制日志,在写 InnoDB 的存储引擎重做日志(redolog)。
- 当前的 MySQL 版本中,一条 SQL 查询只能在一个 CPU 中工作,并不支持多 CPU 处理。
- Windows 操作系统下表名不区分大小写,Linux 操作系统是大小写敏感的。
- 存储引擎是基于表的,不是数据库。
- 如果没有显式的在表定义时指定主键,InnoDB 会为每一行自动生成一个 6 字节的 ROWID 作为主键。
- MyISAM 的缓冲池只缓存索引文件,不缓存数据文件。
「原创声明:保留所有权利,禁止转载」