关于自动化接口测试平台的想法和实现
本来加入论坛已经过 1 年了,在看了接口测试的很多优质文章并且总结以后,设计了一套自己心目的中的接口测试平台。在此和大家分享一下。
流程
接口测试的根源就是从接口文档开始的,接口文档中的参数贯穿了整个接口测试测生命周期。
现在大多数公司的接口文档管理,开发 debug 接口,测试编写执行接口测试用例都是各自独立出来的。
比如:
接口文档管理:jira,wiki,swagger 等
开发 debug:postman 等
接口测试用例:各种自制框架
在这种架构下,各个环节都是分开孤立的。有的时候会出现很多问题
比如开发的接口文档完成后,由于各种原因,开发把参数修改了一下,忘记了修改文档,那么测试拿着错误的文档怎么测试都是错误。
既然我刚才说了接口文档中的参数是贯穿了整个接口测试生命周期,并且如果有改动,需要在尽可能快的情况下和使用参数的使用方进行同步。那么该如何实现呢?
答案很简单:不管研发开发时候 debug 用的,还是测试在测试用的这些参数全部从开发文档上获取就可以了。
方案
既然有了答案,那就来设计方案吧。
接口文档管理:如果对现有的接口文档管理系统很满意的同学,可以从接口文档管理系统的数据库里直接拿到接口的参数,如果是 swagger 的话,只要拿到 swagger-json,解析一下也可以拿到接口的参数。比如我,我觉得公司的接口文档管理很差,我自己设计一个简单的页面专门用来做接口文档管理。
接口 debug 页面:所有的参数都是从文档来的,如果文档写错了,就不能调试接口。
测试用例页面:所有的参数都是从文档来的,测试主要精力就是在 case 的设计上。
平台
平台必定成为一个趋势,而且如果把接口文档管理,接口 debug 页面,测试用例页面放在一个平台上,使用起来是高效的。在推动落地上,平台也更加容易被大家接收。
工具
我用了以下的工具
web 框架:django(为什么不选 flash,因为我懒,很多功能都是做好的)
web 页面:bootstrap3
python 库:requsets 等等
测试框架:pytest
报告框架:allure
持续集成:jenkins
现实
代码就不贴了,由于基本上都是一边 google 一边写的,属于非常不优美的实现。
接口文档管理页面和 debug 页面
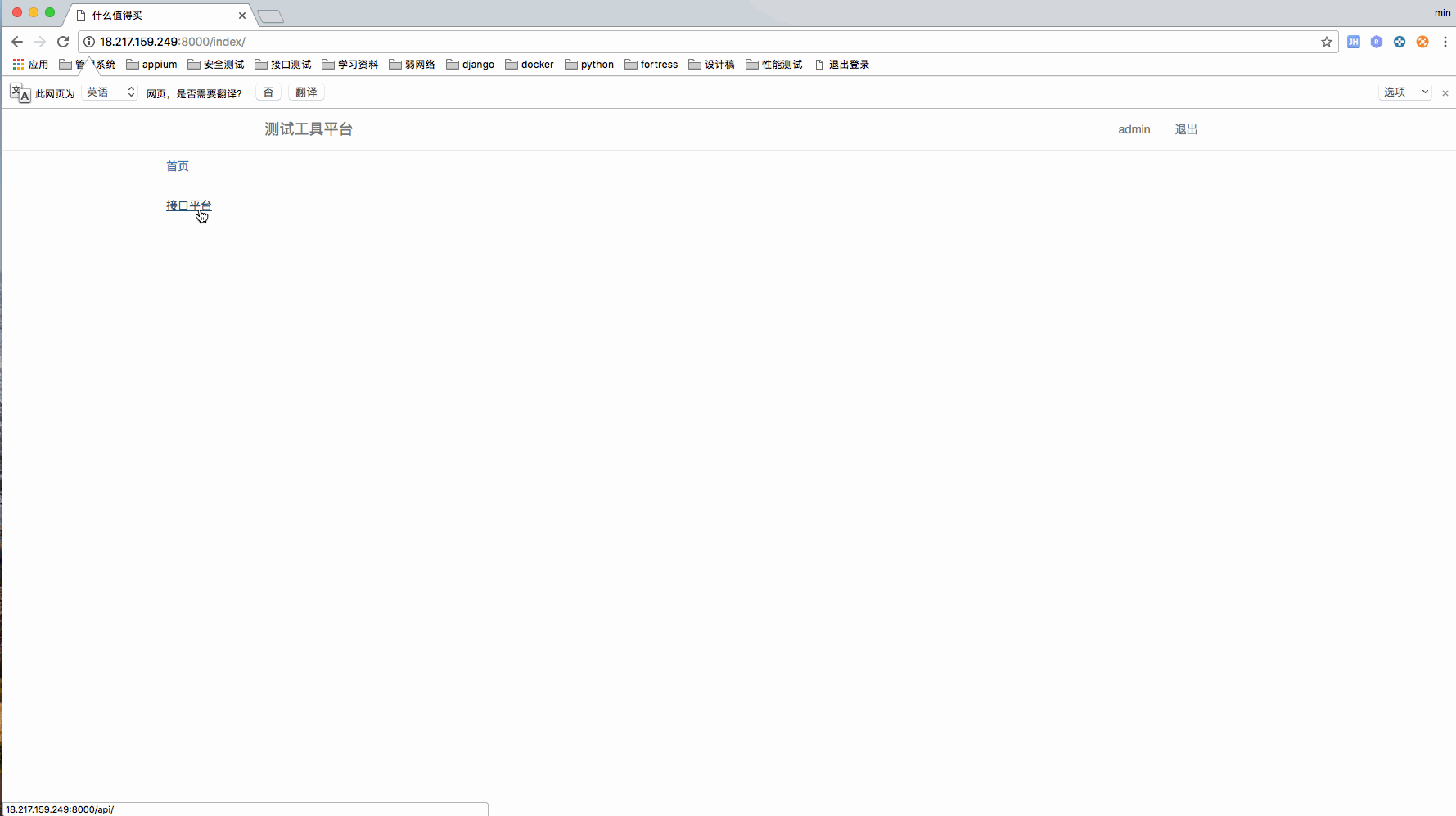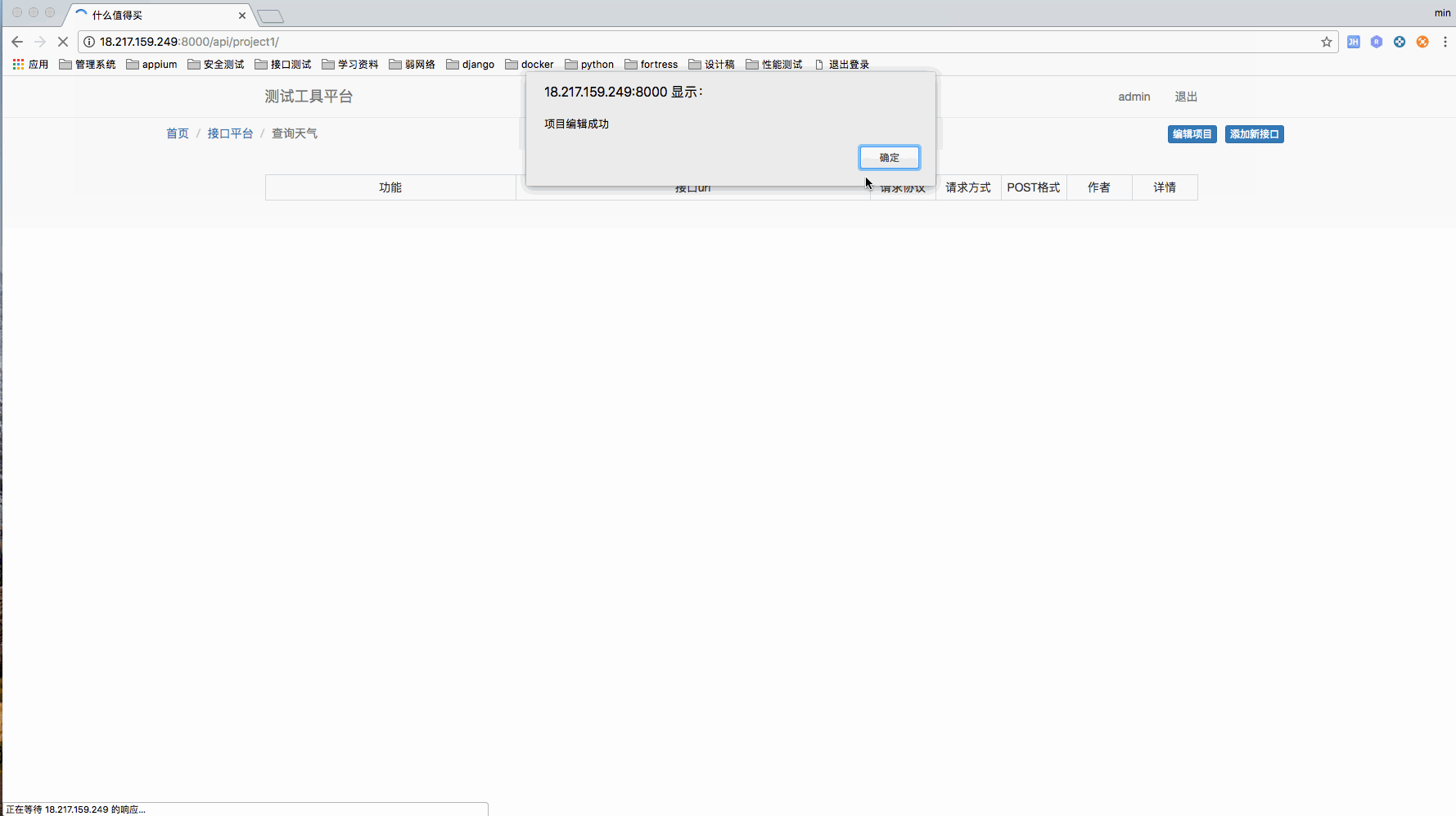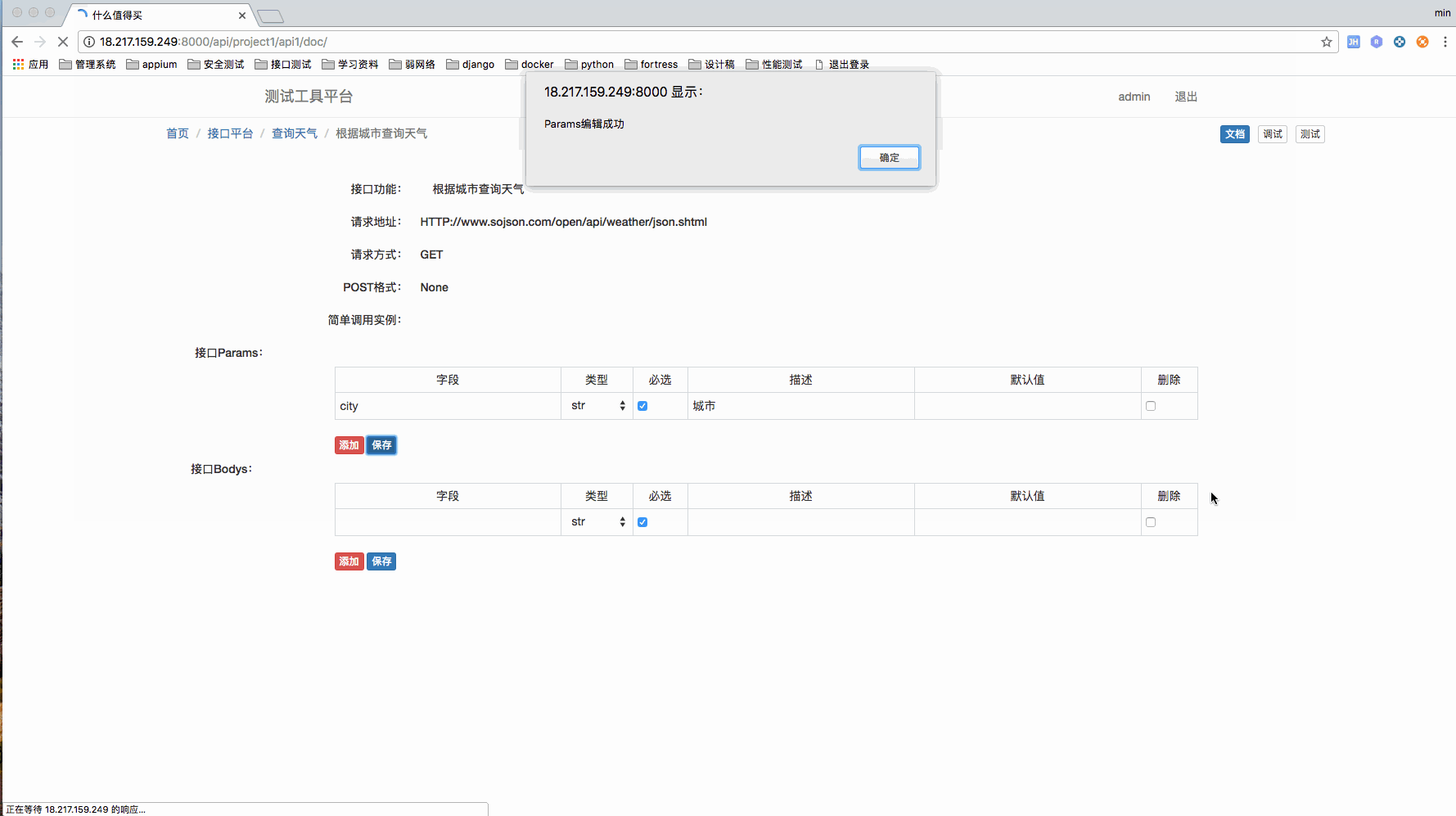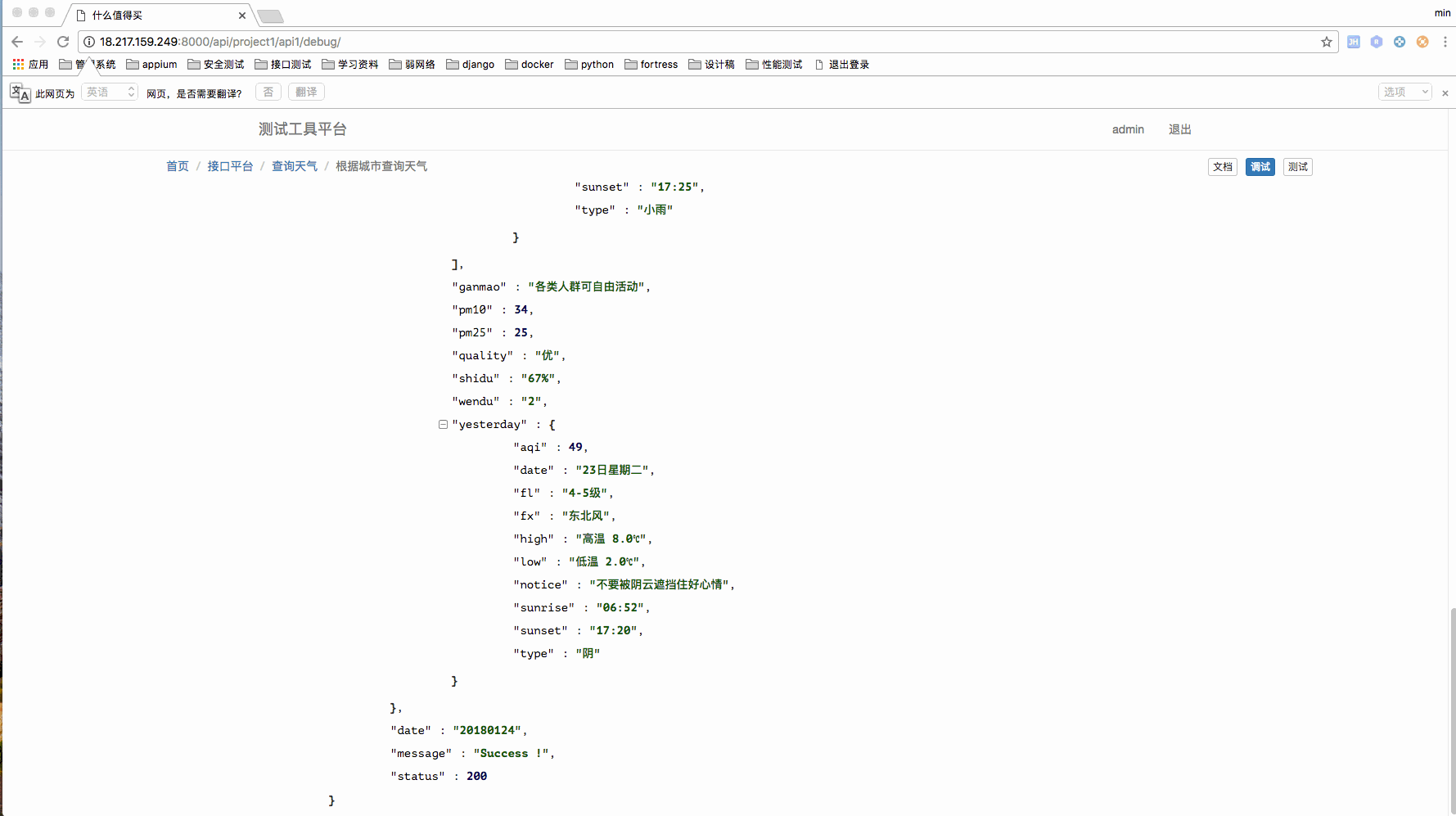
这个是一个完整的文档管理流程,最后还用 debug 页面调试了下。
现在考虑用 tree 的形式来管理文档也许更加方便,等有空会考虑优化。
debug 页面,我是倾向做的和 postman 尽量一致,这样开发可以很容易的过度到在这个页面上进行调试。
为什么希望开发在页面上调试?
很多文档写的内容,测试就算开了文档以后也不容易立刻了解,有的时候还是需要和开发去沟通的。
当测试看到了开发调试的内容后,有些问题就不需要去问开发了,一看就懂了。
也可以把开发调试的历史数据保存到数据库里,以后要调试的时候,直接把历史拿出来点一下就可以了。
测试用例管理页面
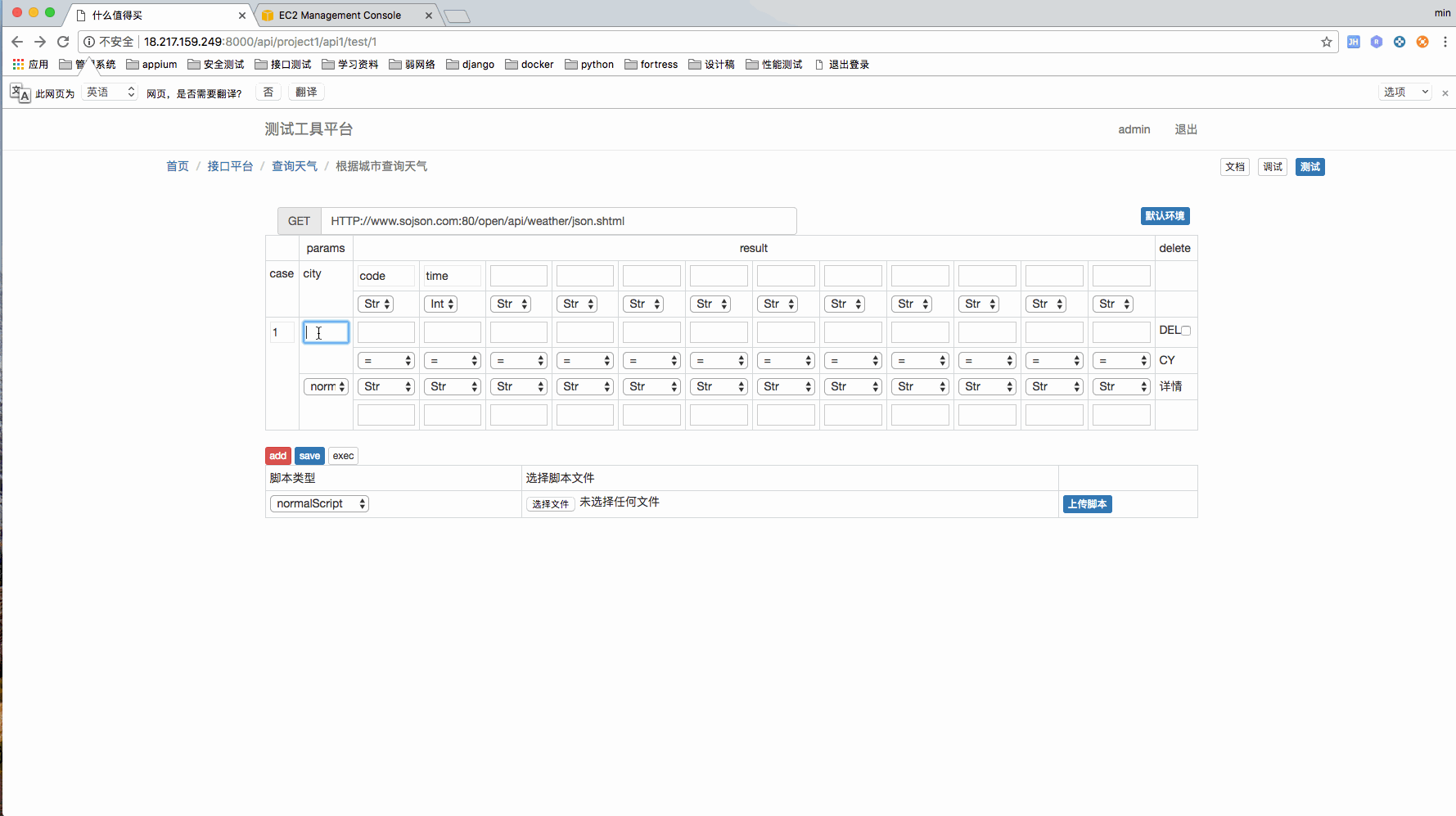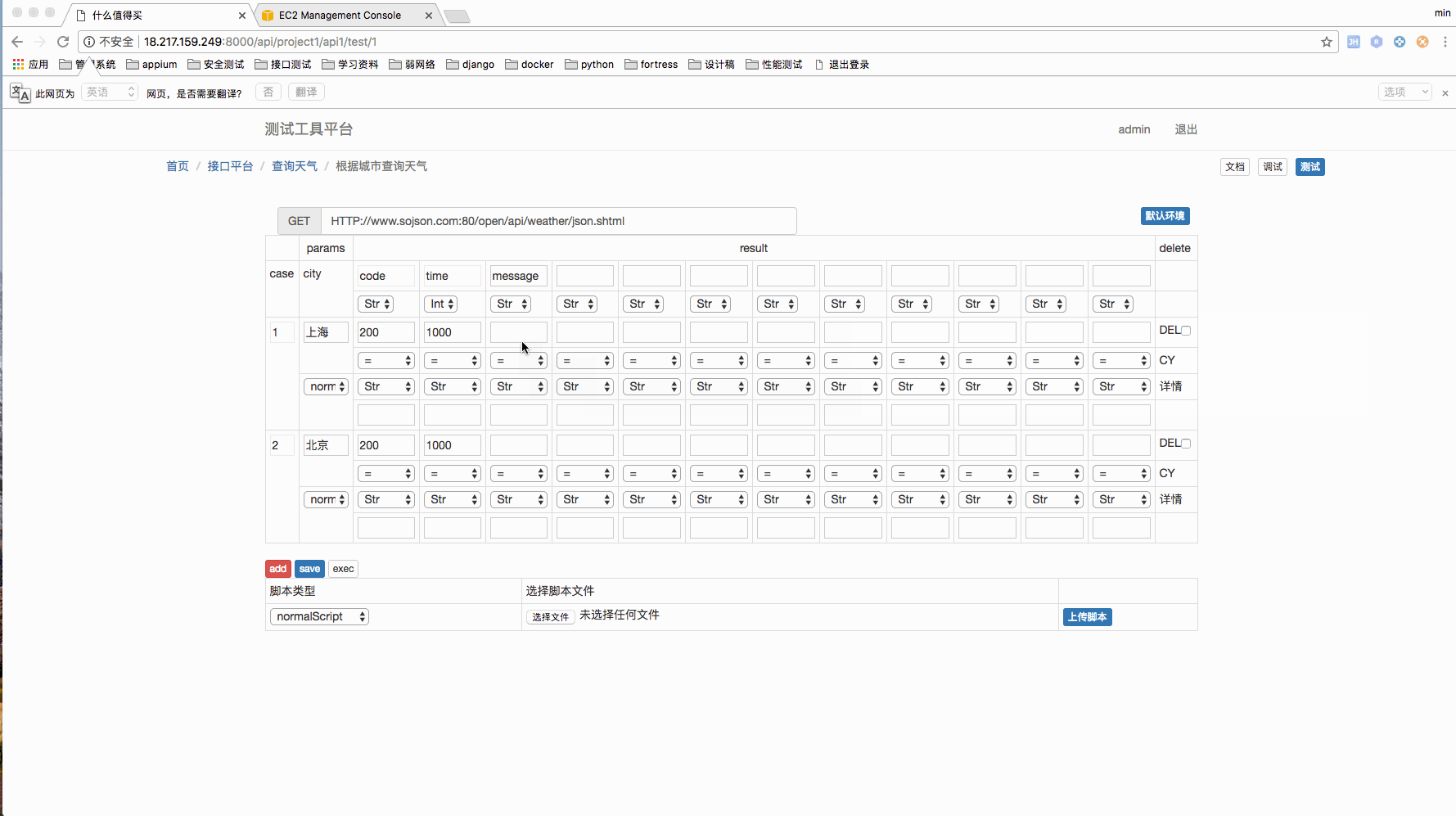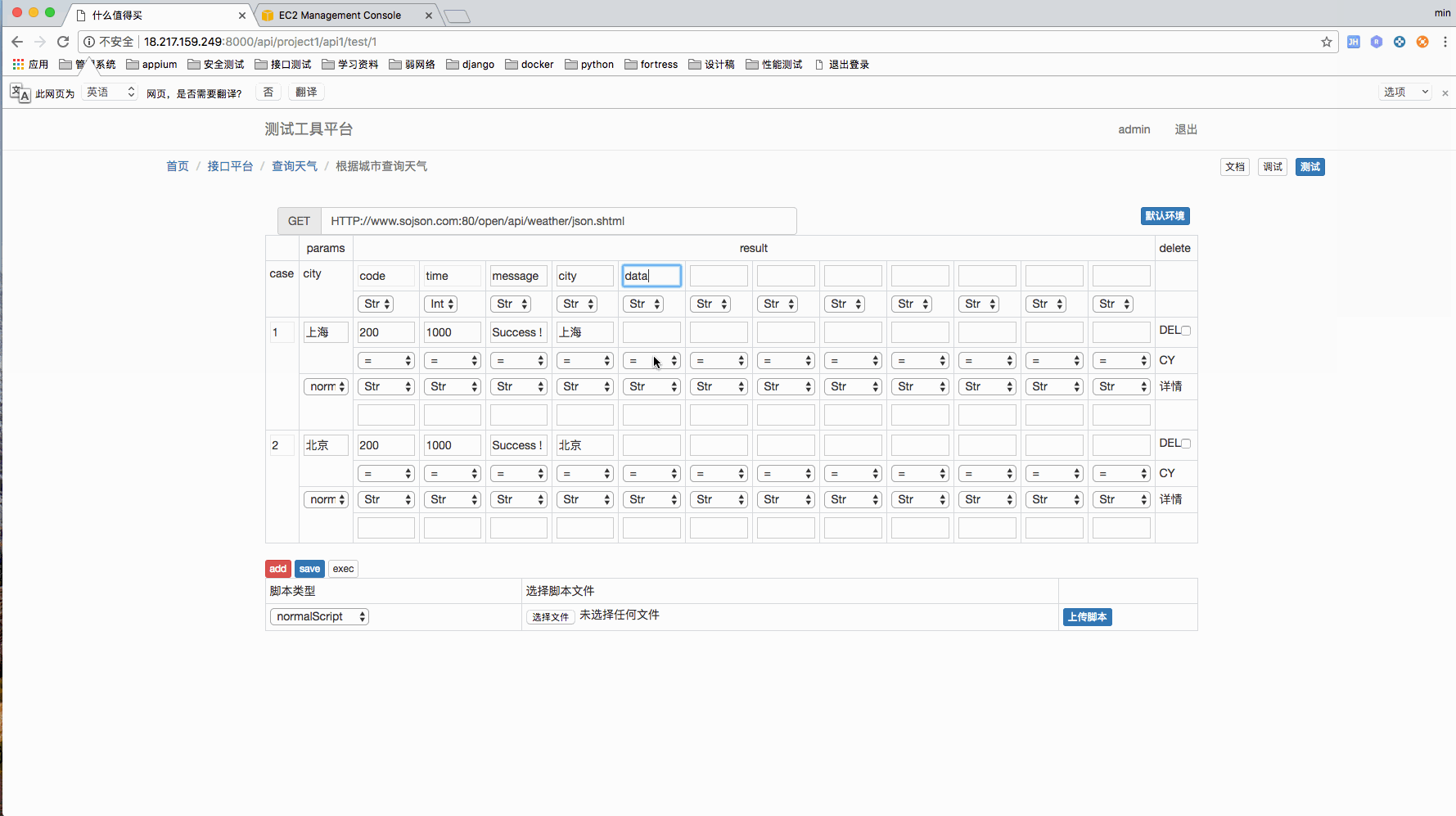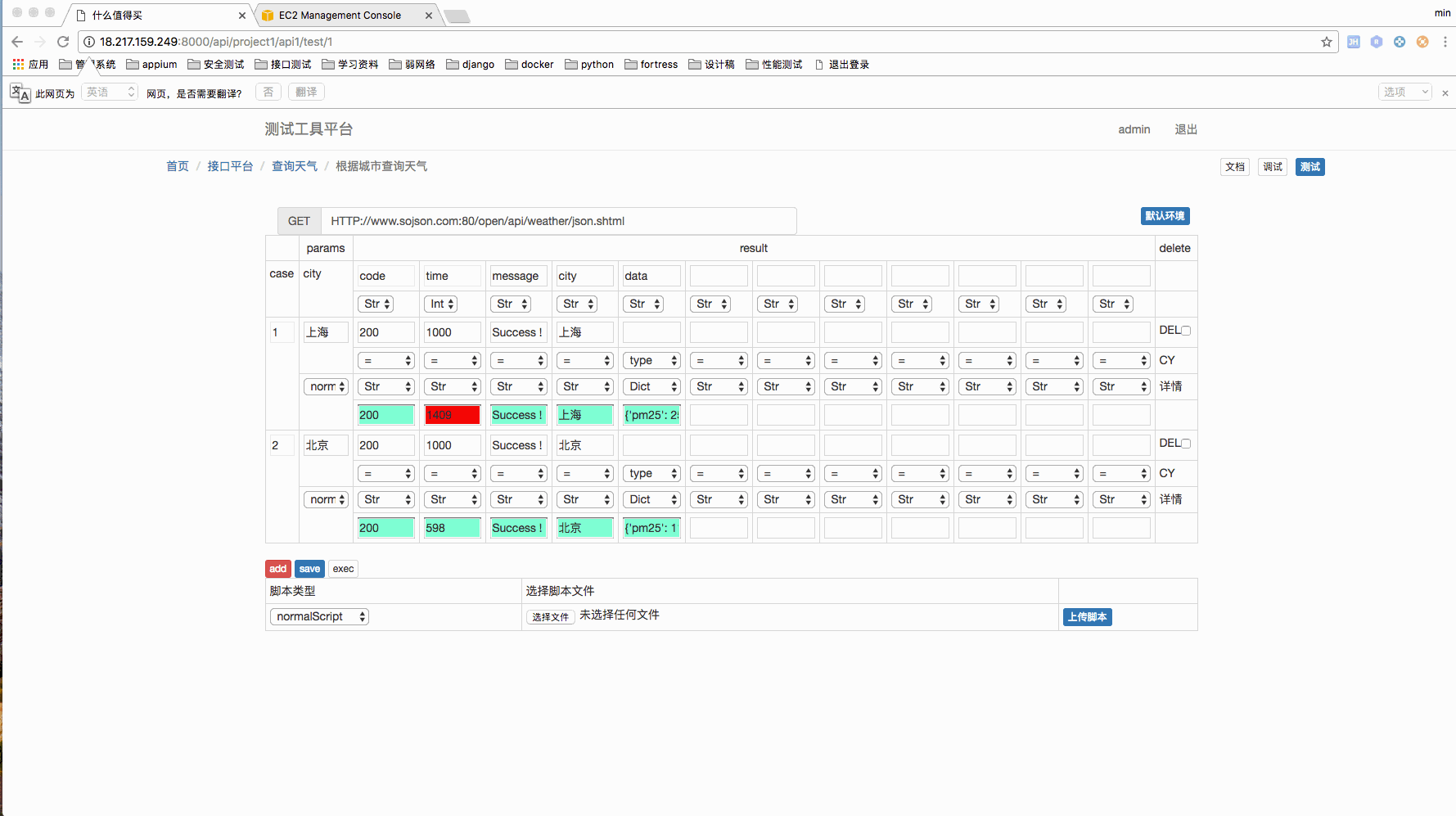
我个人比较喜欢这种 case 的管理方式,相对来说比较直观。
现在可以上传 4 中脚本,分别是 setup,teawdown,header,normal。
原理很简单:
setup_script = importlib.import_module(script_name)
request_dict = setup_script.run(params=eval(self.test_obj.TestParams), bodys=eval(self.test_obj.TestBodys))
self.request_dict = case_request.update_case_request_dict(request_dict)
根据 script 的名字导入脚本,然后执行脚本,执行脚本的参数就是 case 里我们已经输入好的 Params 或者 Bodys。
然后来看我写的一个 setup 脚本:
import time
def run(**kwargs):
time.sleep(4)
print("kwargs %s" % kwargs)
return {"city1": "北京", "city2": "天津"}
case 运行的时候都是运行脚本中的 run 函数,比如我这个 setup 函数,在执行的时候,先执行 sleep4 秒,然后把 city1:北京 这对 key-value,city2:天津这对 key-value 放到运行 case 的时候全局字典 params 中,那么在其他需要调用全局字典的时候,把参数的类型设置成 params,然后把 key 写上,那么 case 执行的时候就可以使用 key 对应的 value。
那么这种用法最常用的场景就是根据参数获取 token。我们可以拿到参数的值,那么脚本只要把这些参数的值拿去做处理,然后返回一队 key-value: token:计算出来的 token。 然后在设定的时候设置下就可以了。
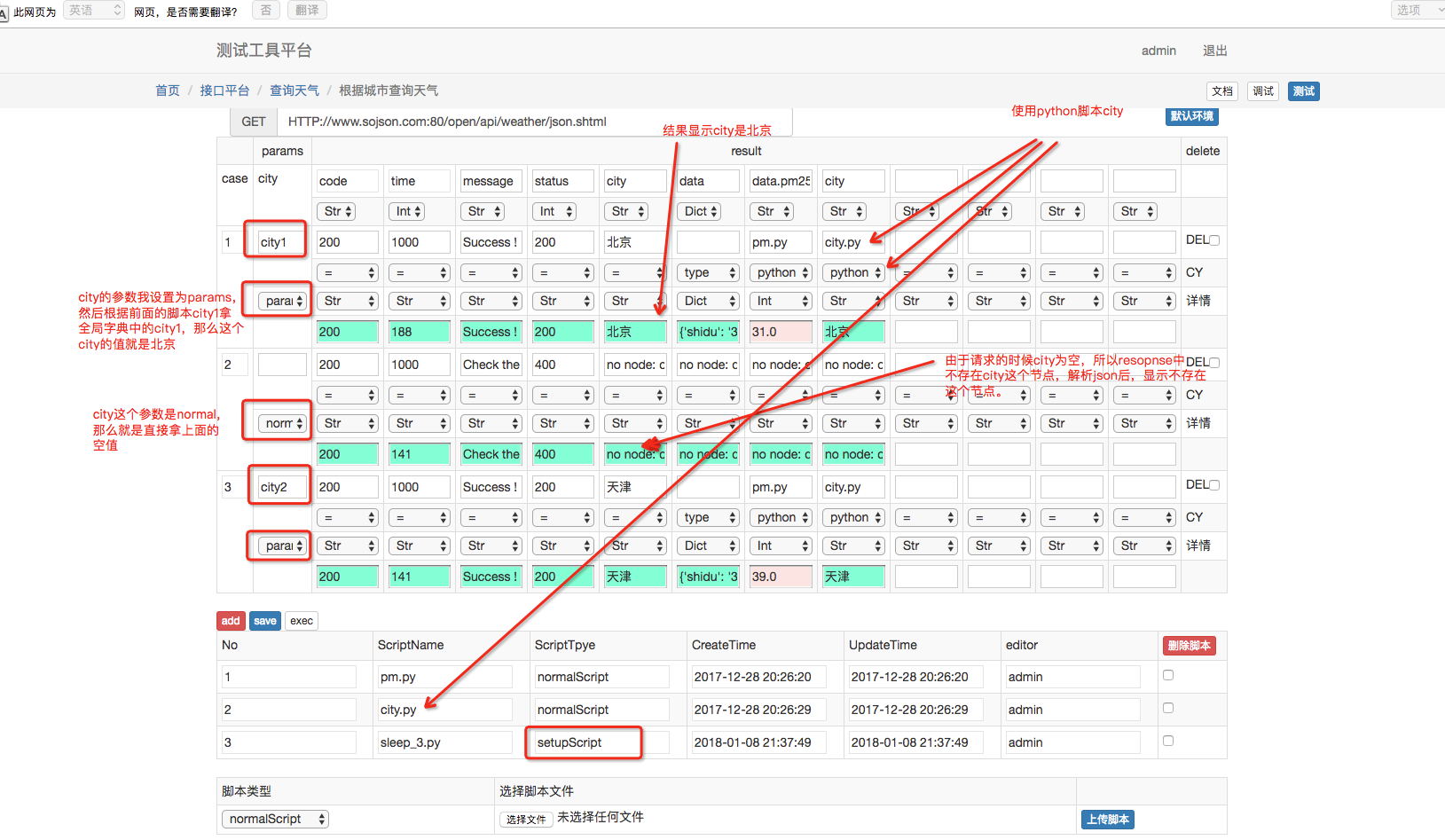
以前有一段时间我觉得 no code 编写 case 是很好的事情,这样能让更多的测试人员参加到 case 的编写中。
但是 no code 还是很难解决 case 的强壮性 。所以要写出好的自动化测试用例,必须是有一定 code 基础的。
这个框架中,可以做到 no code 写 case,可以根据需要添加 python 脚本,让 case 更加灵活。
如果需要添加新的判断方法,只要在 judge 函数中添加需要的方法就可以了,会 python 的同学会觉得很简单。
报告
allure2 是我的最爱,主要就是用起来简单,和 jenkins 无缝结合。这个 testerhome 里介绍相关文章太多了,我就不介绍了。
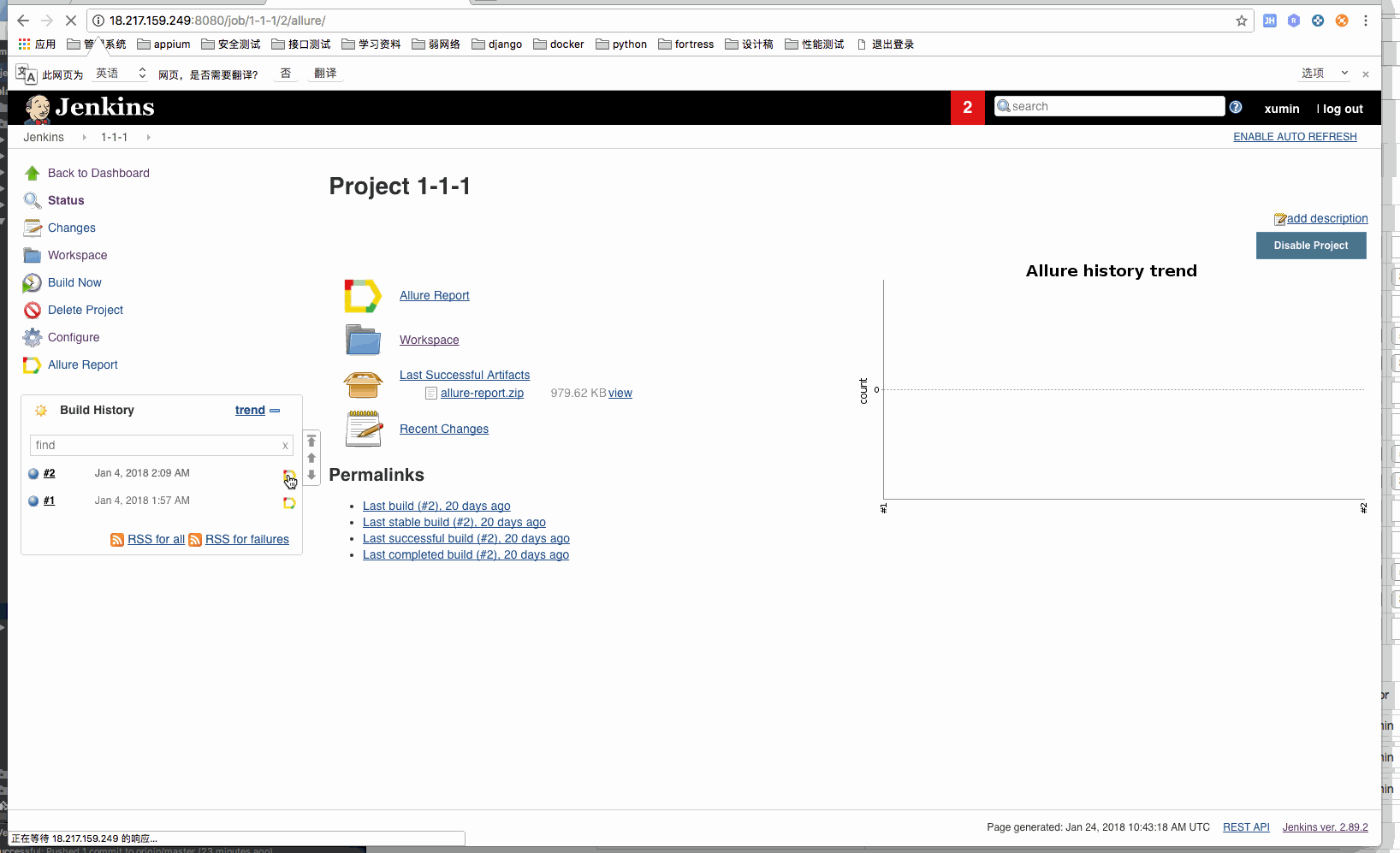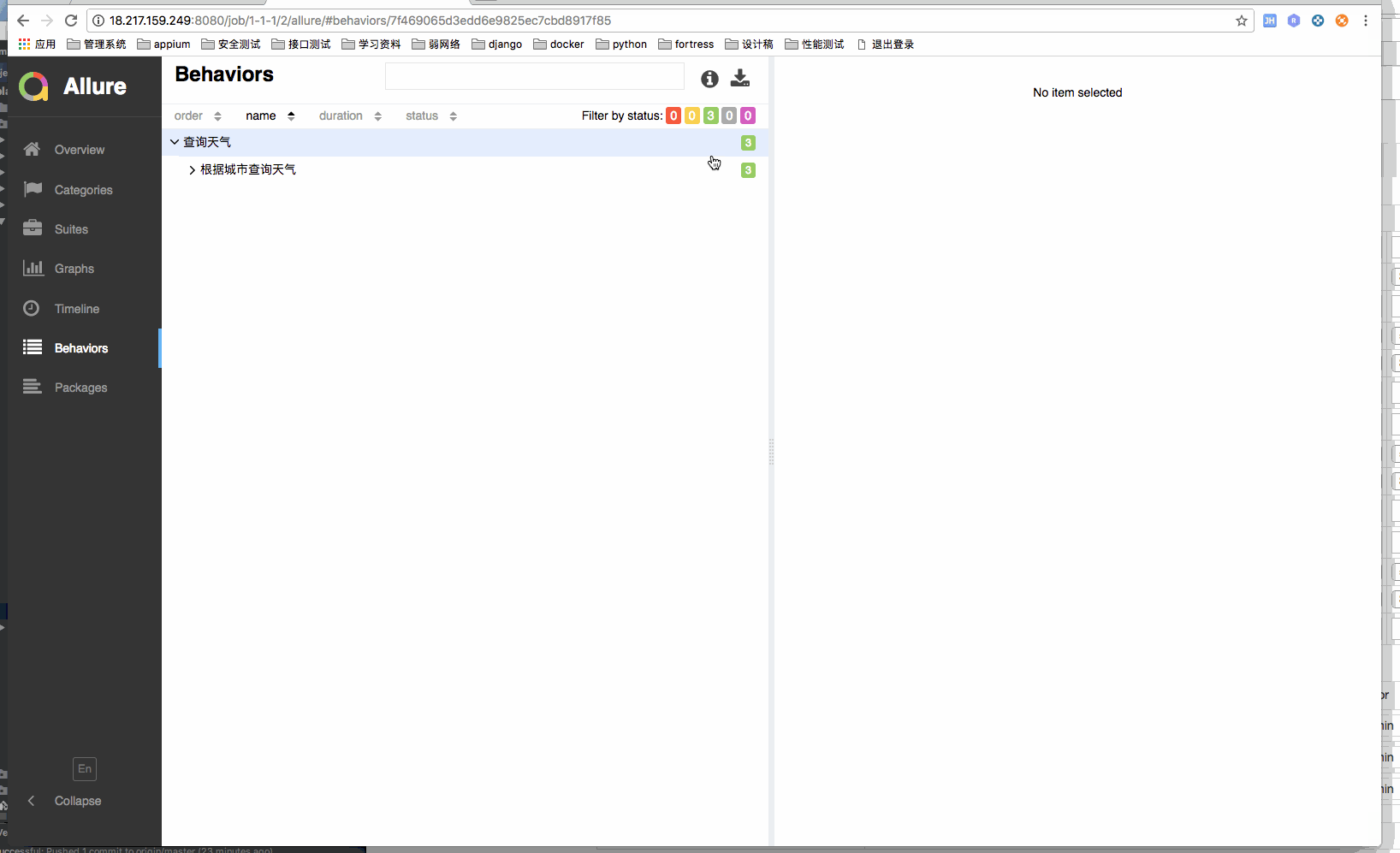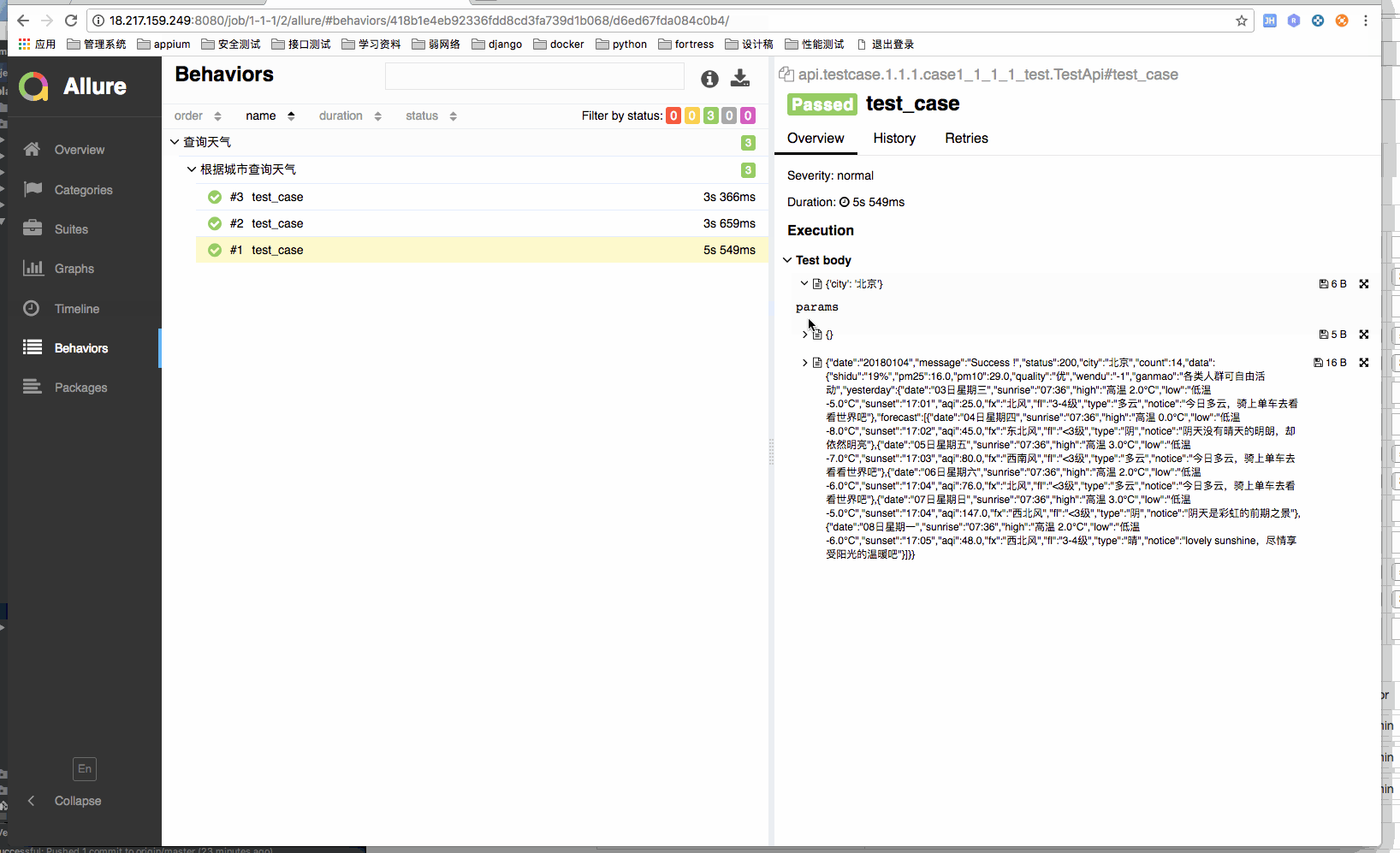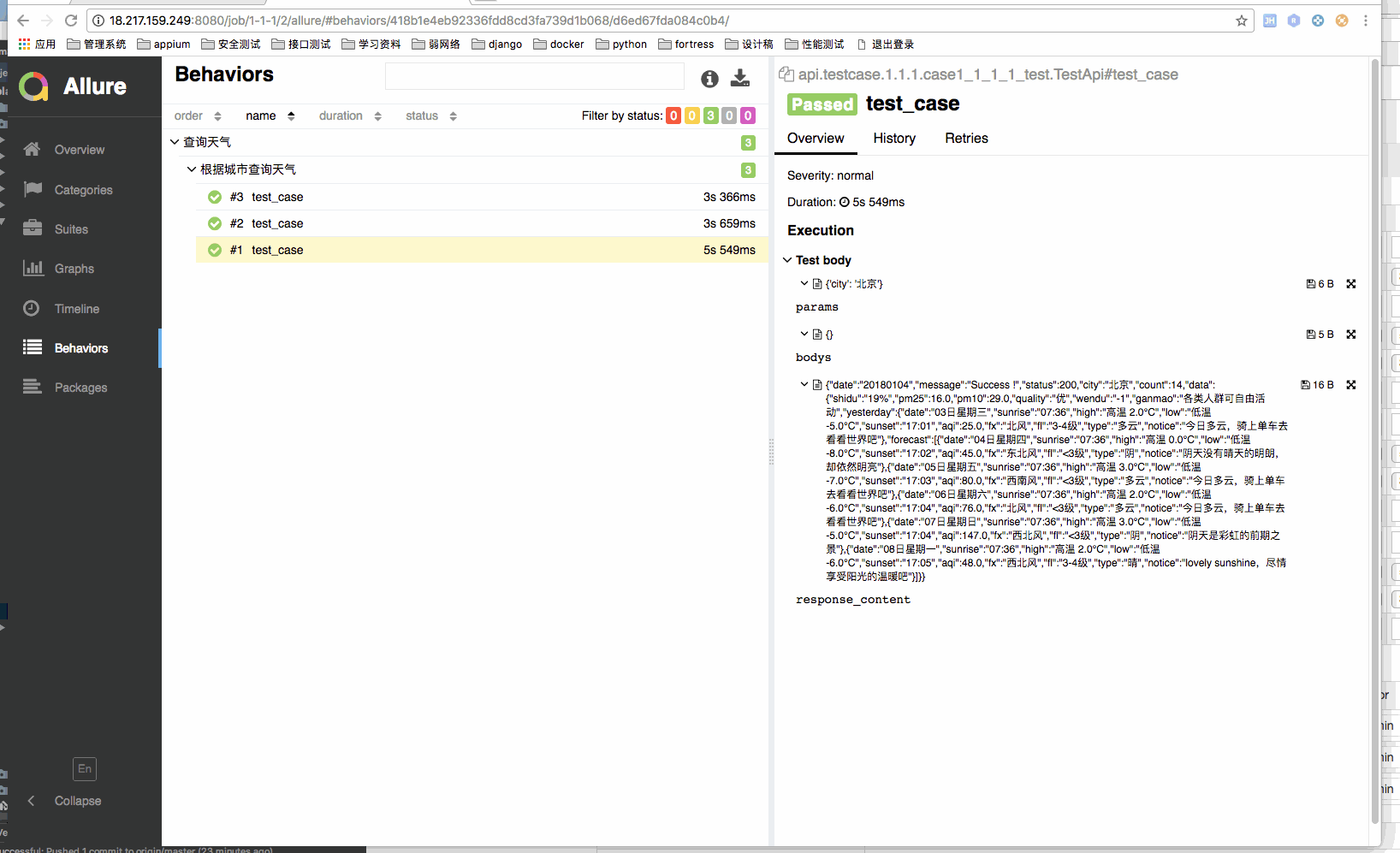
case 的具体生成,我用的是把 sample.py 放到相对的 case 目录下,然后根据 case 名中的参数拿到数据中对应 case 的参数,然后执行。
只要修改 sample.py 中的内容,就可以跟踪你想要得到的所有数据。
感受
以上这些是我做的 demo。
其实可以做的事情还有太多太多,根据实际的工作情况去做才是最有效的。要做一个泛用的框架真的需要很多精力,还是尽力做一个能用就好的。工作有了效率,才有可能拿到更多资源去学习和构建更多的好的工具。
接口测试还是需要好的思路,很多方面,比如测试数据的部署,测试用例的强壮。
