Appetizer Appetizer 报告高级分析:筛选问题,排序,合并
Appetizer 插桩后搜集数据出报告,判断问题的标准是普适的准则。为方便不同的业务团队按照自己的标准进行进一步的筛选和排序( https://testerhome.com/topics/11224 ),Appetizer 支持报告导出的功能,目前支持三种导出格式,HTML(人看),CSV(用 Excel 处理)和 JSON(用脚本进行进一步处理)。
问题筛选和优先顺序
首选,将一个报告为 CSV 格式,Appetizer 会通过浏览器下载一个 zip 文件,打开后包括了三个 csv 文件(如图)。

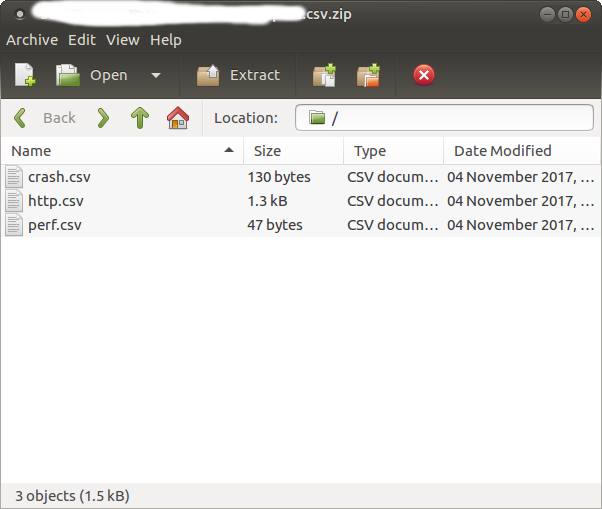
每个 csv 文件对应一类找到的问题:crash.csv是所有的崩溃和 ANR 问题;perf.csv是所有主线程卡顿以及 APP 启动切换性能问题;http.csv是所有网络请求问题。这边以http.csv为例子,双击后 excel(mac 上的 mac excel 也可以,linux 的 libreoffice 也可以)会自动打开,是一个表格的形式,每一行是一个问题,列是问题的字段。分别是:

- Problem 代表是什么问题,有 "high latency"是说首包时间太长, "slow transmission"表示资源下载速度慢
- URL 就是接口请求的 url,包括?后面的参数
- Method 是接口请求方法,常见的有 GET 和 POST
- latency (ms) 是以毫秒为单位的首包时间
- transmission time (ms) 是以毫秒为单位的资源下载时间
- API type 表示该请求使用的库函数,常见有 okhttp, urlconnection(java.net) 和 apache
- status code 为响应代码,2xx 表示成功, 3xx 表示重定向或者缓存,4xx 表示客户端问题,5xx 表示服务器端问题
- content type 是返回数据类型和编码,比如
application/json;charset=UTF-8表示以 utf-8 形式编码的 json 数据 - content length 是需要下载的资源大小
- cacheable 是是否可以在客户端进行缓存(通过 http 请求的 Cache-Control 字段计算所得)
详细这些字段的意思可以参考:https://testerhome.com/topics/9848
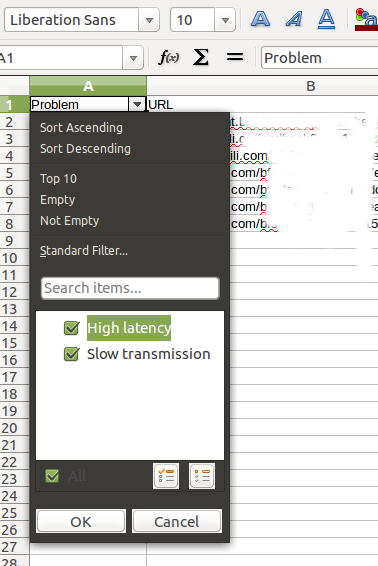
例如我们可以首先进行问题筛选,选出首包时间长的请求,选定问题字段,然后选择 "筛选 Filter",如图,选择要显示的问题类型
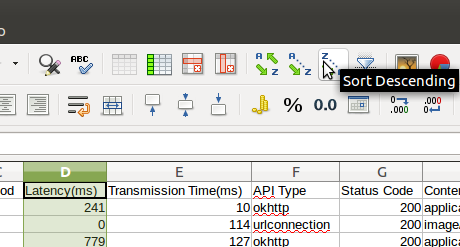
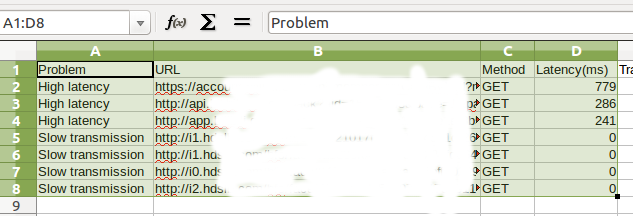
然后可以根据首包时间进行排序,选定首保时间字段,选择 “排序 Sort” 功能,并选择 “扩展到其他列”
合并多个报告
常见的使用方法是,跑一个测试(比如登录,点播,退出等等)即出一份报告,这样每个报告里的内容就是这次测试中的问题。然后有了导出功能后可以合并多个报告找到的问题,从而描述完整的一个或者几个业务流程。
合并的方法很简单,可以将多个报告通过 CSV 或者 JSON 形式导出,然后写一个脚本进行合并。
合并 csv 的时候,因为 csv 数据非常简单,一行就是一个问题,所以直接可以将同名字文件拼接,比如 cat report1/crash.csv report2/crash.csv > all_crash.csv,记得之后要删掉重复的标题栏
如果是 JSON 的话所有问题是放在一个 JSON 数组里面的,可以写一个 python 脚本读入多个 JSON 合并后重新输出
Appetizer 正在做的报告高级分析
目前报告可视化功能比较简单,没有内置的排序或者筛选功能,所以需要借由导出来二次分析,Appetizer 正在完善这部分的功能,也希望大家集思广益:
- 排序,筛选
- 合并多个报告为一个新报告,然后可视化打开