-
UI 自动化测试中遇到的问题,希望可以获得大佬们的解答 at 2020年12月02日
他的意思应该是在 setup 中数据初始化,保证数据库是干净的。
-
selenium+python 如何请求接口和获取接口返回值? at 2020年12月01日
这个问题可以分为两个部分:
- 搜索请求接口的测试,测试接口请求返回的数据是否正确。 ----这个可以采用接口测试.
- UI 界面上对于给定的数据,是否显示正确。 -----这个可以用 UI 测试,后端要不使用造数据,要不就 Mock.
如果 1OK 了,那么 2 可以使用造数据或者 Mock.
如果 1 不 OK,那么 2 可以使用 Mock. -
UI 自动化测试中遇到的问题,希望可以获得大佬们的解答 at 2020年12月01日
文中不是讲的不让在生产库中操作么?
问题 1. 你需要知道自己的操作到底操作哪些数据,case 都固定的步骤,怎么会不知道操作了哪些数据了呢? 放在 TearDown 里面去清除数据,这个大家应该都是这么做的。框架都是提供给你让你这么玩的。
问题 2:提速可能会有个问题,如果多用户同时操作,那么对于用例之间的隔离很重要,多个用例同时操作这个系统,随时可能会造成对多用户对同一数据操作导致用例失败。
问题 3:其实可以想一下,在手动点点点的测试过程中,我们是如何判断测试通过与否呢(或者说系统更新成功与否呢)?然后用代码替代人为判断就可以了。 -
大家都用什么做接口自动化 at 2020年11月26日
我用的还是基于 2 版本的。 3 好像有大改,没有仔细研究。不知道能不能帮到你。 vx: 18694041815
-
MTSC 参会感受 at 2020年11月25日
造轮子的事情,留给大厂的大团队去实现吧。 现在的小厂小团队大多不会投入那么多人力来搞这些事情的。
-
大家都用什么做接口自动化 at 2020年11月25日
httprunnerManager 可以自己 fork 了之后做二次开发(好像后面作者又新出了 fastrunner?)。 但是如果自己想重新撸就是我说的自己写。
-
小白不懂就问:做接口测试产生的数据怎么清除 at 2020年11月25日
分享一下我们当前的做法:
- 我们现在的自动化测试(不管是 UI 还是接口)都是参考了单元测试的 3A 原则(具体可上网查),然后我们自己加了一个清理环境(主要是数据)的 4A.
- 所有用例要用到的业务数据,全部固化在 sql 里面,每个用例会先插入数据,运行完之后删除数据(直接操作数据库,我们内部要求测试人员必须清晰知道哪些数据库被改动了)(插入数据,运行用例,比较结果,删除数据,这 4 部作为一个用例的完整步骤)。
- 经过上述的两个规范,所有的用例不会相互干扰,同时也不会受顺序的影响。(当然如果同一个用例同时运行,可能会造成数据的影响)。
- 另外,在网上看到有人提出使用内存数据库 H2(其实我也忘记在哪个自动化框架中见识过),每个用例运行前都初始化数据库,然后运行完了直接干掉数据库。具体操作方式没有实践过。
以上,仅供参考。
-
[廊坊] 新奥新智招聘中级测试开发工程师 at 2020年11月19日
 你这讲的是对于结果而言。对于过程,也可以精益求精呀,同样是测试结果最终结果符合验收标准,普通方法要 3 天,改进的技术或者过程可以两天,甚至 1 天。 其实这个过程改进一部分就是体现了工匠精神。 个人理解。
你这讲的是对于结果而言。对于过程,也可以精益求精呀,同样是测试结果最终结果符合验收标准,普通方法要 3 天,改进的技术或者过程可以两天,甚至 1 天。 其实这个过程改进一部分就是体现了工匠精神。 个人理解。 -
[廊坊] 新奥新智招聘中级测试开发工程师 at 2020年11月19日
难得有个武汉的企业,支持一下!
-
[廊坊] 新奥新智招聘中级测试开发工程师 at 2020年11月19日

-
用 Httprunner3 做接口测试遇到了问题,求解~ at 2020年11月09日
我使用的老版本看的 demo,不知道最新版本是否支持这种做法。
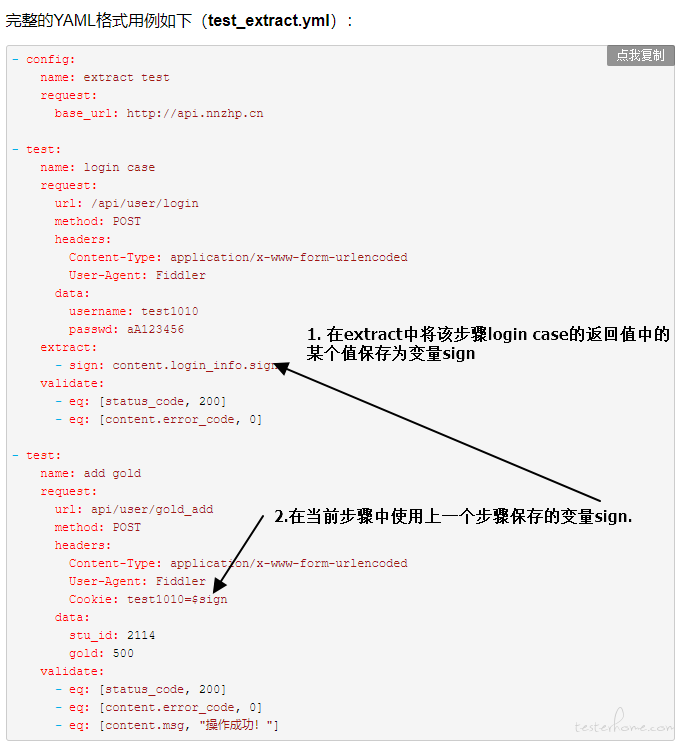
对于你这种情况:
步骤 1:直接保存 response 为某个变量 a。
步骤 2:在接下来的步骤中调用 debugtalk.py 中自定义的函数,参数就是步骤 1 中保存的变量 a. 函数返回值就是自己需要的值即可。 -
大家都用什么做接口自动化 at 2020年11月06日
httprunner 封装一下,做个类似 httprunnerManager 的 UI 界面,推广给内部测试人员使用。我们现在内部用的挺好的,开发人员都开始用了。 唯一缺点就是缺个前端,要是能把前端改的更好看一点就好了。
-
[南京] 深圳力维智联 招聘测试工程师 12-15K at 2020年11月06日
- 以前叫中兴力维? 2.话说大神杨现在转开发了么?
-
用 Httprunner3 做接口测试遇到了问题,求解~ at 2020年11月06日
把 response 保存起来作为变量(先不处理),在下一个 step 的变量定义中通过调用函数(当前步骤的调用函数操作放到这里)后返回值的值赋值给变量就可以使用了。
-
接口自动化全量字段校验 at 2020年09月07日
非常赞!
-
python 诡异问题求助各位大哥 at 2020年08月12日

-
🔥2019年 度问卷中奖名单来啦! at 2020年01月13日
超过半数的使用的还是 QQ 邮箱?
-
2019年 度中国测试行业问卷调研来啦! (有奖问卷) at 2020年01月08日
在哪里能收到报告?
-
python3 的 request.post () 方法中,传参 data 与 json 的区别 at 2019年12月27日
关于什么时候使用 json,什么时候使用 data,可以自己在电脑上敲一敲代码,领悟一下。
另外,提供一个不错的调试方法:
将 request 发送到http://httpbin.org/post,header 中的设置。然后查看其返回值,可以看到服务器接收到的数据格式以及
简单的调用方法如下:
r = requests.post("http://httpbin.org/post", data=payload)
print(r.text)详细的情况 requests 的官方文档中应该有。
-
大四学生毕业想往测试开发的方向走,想知道找工作前需要具备什么技能。 at 2019年12月23日
一般情况下,测试的要求是知识面的广度,而开发人员的要求是知识面的深度。 当前很多测试(太多测试的底子比较薄,没有信心去做开发,觉得测试门槛低,才进测试的)知识面的广度不够,某一方面的深度又不够,从而导致现在的局面。
-
接口自动化的一些疑问? at 2019年12月20日
- 开发是否有提供接口文档?根据接口文档来判断所测试接口应该返回哪些值?
- 根据具体的业务场景,判断这个接口的目的是啥?比如获取某个值,那么正确的返回中就应该有所期望的值。
- 判断无非就是期望值和输出值的比较而已,要确定你的期望值,然后从输出值中提取需要的值,和期望值比较。
另外:值判断返回值肯定是不可以的,有很多接口,即便是错误的,返回的状态码也是 200. 另外的 json 串中会提示错误信息。
-
Vue 等这种前端框架生成的前端页面的项目,如何做自动化测试? at 2019年12月06日
可以参考 Katalon 的定位准则和方式。
可以实际操作一下,如果不将它作为测试框架的话,但是可以参考它们定位元素的方法。或者将它作为辅助工具。
https://docs.katalon.com/katalon-studio/docs/xpath_katalon_studio_tips.html#xpath-basics -
代码质量评测初探 at 2019年11月28日
平台有开源么?
-
httpRunnerManager 图表失效问题解决办法 at 2019年11月26日
加一个静态资源可能无法访问的: extent.js 和 extent.css. 这两个无法访问会导致报告页面混乱。
-
[Jmeter+Ant+Jenkins 集成自动化实践] at 2019年11月26日
Jenkins 拼写错了。
