新手
luusky (守望@天空~)
第 16524 位会员 / 2017-04-07
4 篇帖子 • 96 条回帖
-
腾讯的一道面试题,谁来试一下? at 2019年01月25日
写了个,感觉应该能满足
#-*- coding: utf-8 -*- # @Time : 2019/1/25 12:27 # @File : jsondemo.py # @Author : 守望@天空~ from collections import OrderedDict import json jsonstr = """ {"item":{"data":{"text":"123"},"children":[{"data":{"text":"234"},"children":[]},{"data":{"text":"345"},"children":[{"data":{"text":"456"},"children":[]},{"data":{"text":"plid"},"children":[{"data":{"text":"567"},"children":[]},{"data":{"text":"678"},"children":[]}]}]}]}} """ def dig_path(jsonstr,prepath=[],paths=[]): if not prepath: prepath=[] t=jsonstr if isinstance(t,(dict,OrderedDict)): if t: for key,value in t.items(): prepath_tmp=prepath[:] prepath_tmp.append(key) dig_path(value,prepath_tmp[:],paths) else: paths.append(prepath) elif isinstance(t,list): if t: for index,value in enumerate(t): prepath_tmp=prepath[:] prepath_tmp.append(index) dig_path(value,prepath_tmp[:],paths) else: paths.append(prepath) else: paths.append(prepath) if __name__=="__main__": paths = [] ttt = json.loads(jsonstr, object_pairs_hook=OrderedDict) dig_path(ttt,paths=paths) print("deep","\t","path") for i in paths: print(len(i),"\t",".".join([str(t) for t in i ]))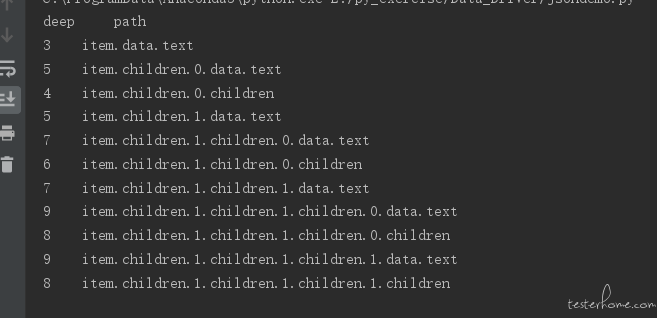
-
测试开发第八期_shell 必备技能实战_20190120 at 2019年01月20日
netstat|grep ":ssh"|awk '{print $5}'|uniq -c|wc -l -
测试开发第八期_shell 必备技能实战_20190120 at 2019年01月20日
作业 4
awk '{print $7}' /tmp/nginx.log |sed "s#[1-9]#*#g"|sort |uniq -c |sort -nr|head -5 -
测试开发第八期_shell 必备技能实战_20190120 at 2019年01月20日
cat /tmp/nginx.log |grep -E "404|500"|head -5 -
求教 selenium 截图为什么是黑色的?,急急急 at 2019年01月03日
貌似 IE 控件的内容不归浏览器,所以截不到
-
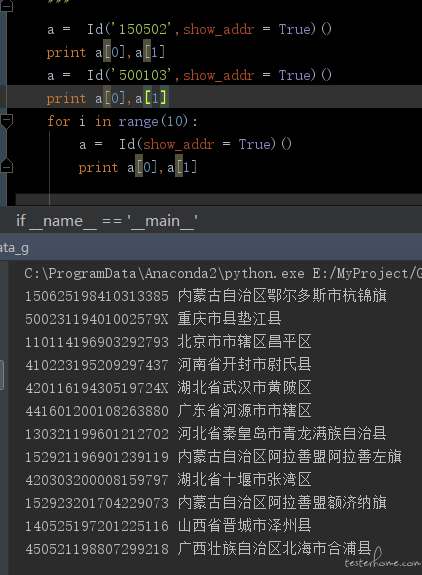
python 随机生成身份证号码 at 2018年12月14日
这个轮子我也造过

-
HtmlTestRunner_cn 1.1,支持截图,失败重试,兼容 py2&py3 at 2018年11月12日
好好看一下 demo
 你打开方式不对啊
你打开方式不对啊

-
[IT] 软件自动化解决方案『免费开源』基于 JavaFx 的自动化测试系统,已更新至 V1.1.3 最新版 at 2018年10月10日
界面看的中二病犯了
-
IOS12 点击文中的链接会有惊喜 at 2018年09月19日
昨天好几个公众号说这个呢,IOS、MacOS 系统 css 攻击,啧啧
-
HTMLTestRunner_Chart 包含历史结果的测试报告 at 2018年09月17日
666
果然引用现成的 UI 库比自己造轮子好看~~ -
求一款轻量级的性能监控工具 at 2018年09月11日
nmon :小巧,命令行操作,可定时,可用 excel 进行可视化
netdata :部署简单,界面高大上
zabbix :企业级监控,部署麻烦些,可定制内容更丰富 -
python uiautomator2 截图转为 base64 加入 HTMLTestRunner 报告中 at 2018年09月07日
我当时是为了发邮件方便才用 base64 存图片在单文件里的,如果有其他展现平台,像其他人说的存数据库,不转也行~~
-
某司面试题,输入任意一个数字 n,产生九宫格 n 位手势密码,例如输入 4,则产生的 (1,2,3,6)、(1,4,7,8) 都可以。九宫格规则是:数字只能连相邻的数字,且不能出现重复。请问使用 python 如何实现,谢谢。 at 2018年09月04日
玩一下~~
from random import choice def nine_demo(n): if not 2<=n<=9 or not isinstance(n,int): return " Invalid code" d = list(range(1,10)) checker = [1,3,7,9] result =[] # 生成随机密码 for i in range(n): code=choice(d) result.append(code) d.remove(code) # 邻值越界检查 if i>=1 and code in checker and result[i-1] in checker: result = [] return nine_demo(n) return result if __name__=='__main__': for i in range(0,11): print nine_demo(i) -
HtmlTestRunner_cn 1.1,支持截图,失败重试,兼容 py2&py3 at 2018年08月31日
跳过的用例不会执行的,没计入统计啊
-
微信上传图像测试用例? at 2018年08月03日
上传图像是否含有淫秽色情的、反动的内容
-
[上海] 育碧游戏-招聘中高级游戏测试员 at 2018年07月05日
666
-
如何判断期望结果和实际结果是否一致 at 2018年06月19日
解析成 dict 简单遍历一下就行了啊
-
python 爬虫的两种方法 at 2018年06月19日
xpath 和 beautfulsoup 比正则友好多了,都用 requests 了为何不了解一下 requests-html

-
HtmlTestRunner_cn 1.1,支持截图,失败重试,兼容 py2&py3 at 2018年06月05日
我是在封装时候直接加了一个截图函数

-
HtmlTestRunner_cn 1.1,支持截图,失败重试,兼容 py2&py3 at 2018年05月03日
case 注释用的 unittest.TestCase 的 shortDescription 方法,此方法只取注释的第一行 ,把 shortDescription() 改成._testMethodDoc or '' 就全显示了~
-
[分享] HtmlTestRunner 汉化版,支持截图,兼容 py2&py3 at 2018年05月03日
setUpClass 这步异常了,就没法接着进行后面的测试了,不是兼容性的问题,有异常测试本身就没法继续了
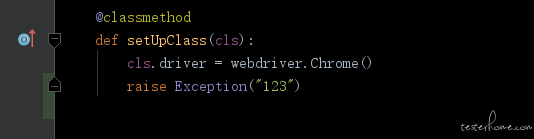
针对这种异常的处理

结果变这样

-
HtmlTestRunner_cn 1.1,支持截图,失败重试,兼容 py2&py3 at 2018年04月28日
支持~
-
[分享] HtmlTestRunner 汉化版,支持截图,兼容 py2&py3 at 2018年04月28日
这个是初始化 driver 时候就失败了
-
# 每日一道面试题 # 如何判断一个字符串是回文字符串,并对你的写出的方法进行测试 at 2018年04月26日
def checker(text): if not isinstance(text,(str,bytes)): # raise Exception("输入不是字符串") return False if len(text)<2: return False half_len = len(text)//2 if text[:half_len]==text[half_len+len(text)%2:][-1::-1]: return True else: return False if __name__=='__main__': print(checker('aabb')) print(checker('aa')) print(checker('abba')) print(checker('ababa')) print(checker('-bab-')) print(checker('o(∩_∩)o')) print(checker('a')) print(checker('')) print(checker(233)) -
HtmlTestRunner_cn 1.1,支持截图,失败重试,兼容 py2&py3 at 2018年04月24日
试了下,是可以的,就是样式得改一下
