-
券商测试开发 offer 选择,请大佬们给点意见。 at 2021年01月25日
我在长沙 如果是靠谱的测开的话 11 已经算比较低了哦
-
请教,UI 自动化执行,并发用例执行解决方案 at 2020年12月28日
分析下日志 看看为什么增加了并行数 速度没有增加
-
请教,UI 自动化执行,并发用例执行解决方案 at 2020年12月26日
并行级别是什么 运行时确定是 20 个线程在跑吗
-
selenium 搜索不到页面最底部的按钮 at 2020年12月15日
有这种情况 对这种情况特殊的元素 可以点击后 再判断下状态 如果没点上 多点几次

-
selenium 搜索不到页面最底部的按钮 at 2020年12月15日
1、直接用 JS 的 click 不管是否可见 都能响应点击事件,不过这样也可能带来一些负面影响。总体来说还是可控的
2、运行时查看浏览器的操作,确定你需要操作的元素是否滚动到可见了, action 的 click 是可以穿透遮罩层的。driver 的 click 方法不行
3、参考 7 楼的方法,用无界面模式 可以自定义分辨率 -
接口自动化,测试管理系统查询一类的功能时,有什么好的方法吗 at 2020年12月08日
{
"message": "操作成功",
"status": 200,
"count": 2,
"data": [
{
"page": 1,
"rows": 10,
"id": 23,
"question": "商品期权权利方平仓凭证中,作为贷方的科目有 ()(0.5 分)",
"options": "A、 差价收入 B、 交易费用 C、 证券清算款 D、 其他衍生工具_商品期权",
"answer": "标准答案:A",
"questiontype": "单选题"
},
{
"page": 1,
"rows": 10,
"id": 2004,
"question": "商品期权中,义务方认购行权实际理解为 ()(0.5 分)",
"options": "A、 期权增加,期货空头增加 B、 期权减少,期货空头增加 C、 期权减少,期货多头增加 D、 期权增加,期货多头增加",
"answer": "标准答案:B",
"questiontype": "单选题"
}
]
}假如接口返回数据是这样,可以把 data 提取出来,去除不用比对的字段后保存为一个列表。
期望值也做成一个列表,比较两个列表的差集 -
接口自动化,测试管理系统查询一类的功能时,有什么好的方法吗 at 2020年12月08日
可以用列表差集方式比对
-
selenium 的显示等待只看元素存不存在不看元素可不可交互的吗? at 2020年12月08日
定位和操作 是不同的概念 寻找元素是只要元素存在于 dom 中就能找到,不论是否可见可操作的。
显式等待可以自定义等待条件,selenium 本身也预置了很多常用的等待条件。基本上够用了 -
如何选择元素定位方式 at 2020年12月05日
全 xpath 省事
-
selenium 搜索不到页面最底部的按钮 at 2020年12月03日
这个问题很常见
-
selenium 搜索不到页面最底部的按钮 at 2020年12月03日
要明确一点 是定位不到还是无法操作 按理来说应该是可以定位得到的
只是由于不可见 所以无法执行 selenium 自带的 click 方法
可以尝试用 JS 的 click 方法来点击 -
试着使用 jmeter 实现接口自动化测试 at 2020年12月03日
插件好像叫 publish html reporter
-
UI 自动化测试中遇到的问题,希望可以获得大佬们的解答 at 2020年12月03日
不是事前建 而是事前删
不清楚你的具体情况,各个用例之间的数据会有依赖吗,
设计用例时 最好是每个用例都能单独跑 这是一个原则 -
selenium 谁遇到过点击了按钮但实际却没有点上的情况? at 2020年12月03日
这个得看你们公司的需求,一般来说 UI 只是用来做页面的冒烟测试,保证不出低级问题就行。没必要做到这么细致
不过,我这里确实是做了的,包括标签文本校验、表单元素默认值、列表关联项动态加载、元素状态控制、表单元素布局、数据列表校验
因为产品本身是属于需要长期维护更新的企业应用。自动化也跟着做了好几年了 -
UI 自动化测试中遇到的问题,希望可以获得大佬们的解答 at 2020年12月02日
1 和 3 都遇到过
1、回收数据如果无法使用 SQL,在事后处理确实容易受到用例本身运行情况的影响,可以考虑把回收工作做到测试的事前处理。这样的好处一是稳定,不受测试用例本身的影响。二是如果测试失败,还留有测试数据更容易复现问题。
3、对于异步处理,如果页面直接反馈的信息不准确,可以直接根据后端数据的变化来进行断言。设置一个比正常处理时间稍长的阀值,对结果数据做轮询。前提是在前端能查到用来做标志位的数据。 -
试着使用 jmeter 实现接口自动化测试 at 2020年12月02日
中小型项目的接口自动化选 jmeter 够用了。至于测试报告可以考虑使用 jenkins 的插件来实现
-
selenium 谁遇到过点击了按钮但实际却没有点上的情况? at 2020年12月02日
很正常,按钮点击要有动作必须要其对应的 JS 方法加载完毕。而显式等待一般也只是判断按钮元素本身是否加载完成或者显示。
这之间还是会有一定的时间差。 所以建议所有的动作之间都加上 0.5 到 1 秒的延时。可以避免很多类似的问题 -
如何实现 mysql 导出数据,验证页面正确性? at 2020年12月01日
实际是两个步骤
第一个步骤 是输入 你需要核对的 列头的文本列表 获取 各自对应的 index 保存下来
第二个步骤 是根据上一步获取的 index 获取列表元素对象,再去逐一比对期望值
能理解吗 -
如何实现 mysql 导出数据,验证页面正确性? at 2020年12月01日
这个要结合 header 和 cloumn 一起看
不管你的元素具体的 class 里数字是多少
只要 列头和列表元素的数字是有规律能对应起来的就行了
比如 列头的 class 里 数字是 2 那列表元素的 class 里也是 2 或者是固定的偏移量 都可以 -
如何实现 mysql 导出数据,验证页面正确性? at 2020年12月01日
不知道你具体是怎么设计的 我直接说一下我的方案好了 希望给你一些参考 ,能否实现 也和前端框架有关系的
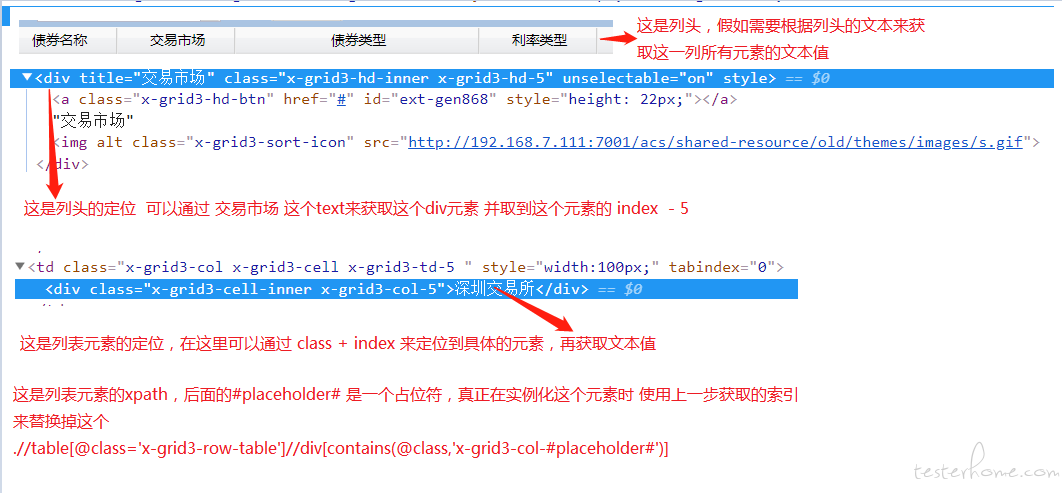
-
如何实现 mysql 导出数据,验证页面正确性? at 2020年11月30日
列表数据的校验是一个难点,我的方式是通过列头的文本值来通过 xpath 相对定位获取这一列所有元素 再逐个与期望值校验
-
请各位大佬帮忙看看我的 Page Object 模式用的对不对 at 2020年11月30日
其实也是参考 RF 的设计,把元素和动作分开,页面不带任何动作 需要操作时把元素和动作组合起来使用就行了
-
请各位大佬帮忙看看我的 Page Object 模式用的对不对 at 2020年11月28日
把元素定位和动作分开封装,PO 只维护对象,动作可以抽象出来和元素进行任意组合,一般的 WEB 页面也就是几十种动作类型
-
讨论一下用例解藕的必要性 at 2020年11月11日
根据公司项目的业务特点和 UI 自动化的职能目标而定
如果 UI 只是用来做页面的 CURD,各用例之间有依赖是可以接受的。每个用例都做前置后置数据维护工作量会更大
如果需要做流程,用例最好能做到独立运行。一般还是推荐用接口做流程回归,受客观因素影响比较小
另外还可以加入重试机制,能很大程度降低外部因素引起的测试失败
我这里 UI 只用来做功能冒烟 约 500 个页面 用例数 2500~3000 之间 通过率平均 93~95% 左右 -
大家都用什么做接口自动化 at 2020年11月09日
嗯 使用哪种方案还是根据项目具体情况而定
jmeter 资料丰富 上手快 对人员要求也低 用来做一些短期项目的接口自动化还是挺不错的