
前言
这两天用过 curosr 也用过腾讯的 codebuddy 来完成代码编写和用例生成等工作。个人感受上很好,保守估计提高了将近 10 倍的效率。 很多时候我都是在开着多个 Agent 并行帮我做事。这也是为什么我能在如此高的工作强度下还能维护知识星球,甚至去尝试自己写小说的爱好。
我认为 AI 能帮我做很多事情,但有些还没接触过的同学始终无法理解,或者已经接触的同学在使用的时候仍然不得要领。 所以我把今天我写的一个小工具的过程展示出来,帮助大家快速体会一下。
需求说明
我在工作中遇到了一个需要到客户场地运行的压测任务,并且工具代码还要提供给用户自己运行。 这就使得我们无法把现有工具提供出去(现有工具是一个很大的项目,里面集成的一些东西不能给客户)。 而且客户有一些定制化东西也是现有工具不兼容的。 所以我需要短时间内开发一个可用的工具。
第一个提示词:初始化对话方法
现在我有一个测试大模型的性能的需求,因为要到客户环境内进行测试,所以无法使用现有测试工具。我希望你先帮我写一个与大模型对话的脚本, 要求:
1. 参考 chat_sse_runner.py
进行对话。
2. 目前的配置是从配置文件或者从远端获取的。 并且do_comb_chat_sse_by_env方法中根据不同的account name去获取不同的鉴权信息, 这样的方式不利于把脚本复制到客户环境执行。 所以我希望你编写一个独立的脚本, 这个脚本不依赖其他文件。也就是需要把对话功能都封装在这个脚本中。 参数在脚本的开头声明。
3. 在脚本中统计几个指标:
a. TTFT: 发送请求后到大模型的首个token的返回的延时。
b. tokens_per_second:抛除首个token后,每秒返回给用户的token数量。
c. input_tokens: 大模型输入的token数量。
d. output_tokens: 大模型输出的token数量。
e. all_time:本次请求的总耗时。
大模型对话的初版代码生成的基本没有问题,调试成功。于是开始第二个提示词。
第二个提示词:添加日志功能
刚才的功能测试没有问题,现在我希望能为这个脚本的对话加入一些日志功能。 要求:
1. 所有日志都记录到一个独立的日志文件中(每次对话都是一个新的日志)
2. 检查脚本中可能出现错误的地方,任何错误信息都要记录在日志中。
3. 整个对话的输入和输出要记录在日志中。
4. 统计的指标要记录在日志中。
5. 日志保存在与脚本同路径下的一个log目录中。
完成以上事情后,再帮我编写一个从日志中分析错误信息的脚本。读取所有日志文件,找出有错误的那个并告诉我路径。
测试一下日志内容:
2026-03-04 11:26:47,931 - INFO - 日志文件路径: /mnt/cloud/automation_project/adp-qta-proj/tool/pef_test/log/chat_20260304_112647_bfc615ec.log
2026-03-04 11:26:47,931 - INFO - 运行参数: APP_ID=2020711113026945536, CHAT_LOCATION=send, CHAT_VERSION=v2, ACCOUNT_NAME=Default, TEST_ENV=test, LANE_NAME=toe-base, CONTENT=你好,请做个自我介绍
2026-03-04 11:26:47,931 - INFO - 使用 inline 配置源加载环境配置
2026-03-04 11:26:47,932 - INFO - 对话URL: https://testwss.testsite.woa.com/adp/v2/chat
2026-03-04 11:26:47,932 - INFO - 开始获取AppKey, app_id=2020711113026945536, account_name=Default
2026-03-04 11:26:48,147 - INFO - 获取AppKey成功
2026-03-04 11:26:48,148 - INFO - 对话输入参数: {"AppKey": "***", "VisitorBizId": "2020711113026945536_0", "RequestId": "596a831b-8b2c-4ba5-9bae-a24bb4e17453", "ConversationId": "401d5ef2-fb68-4341-9d99-06199df6f6e9", "Contents": [{"Type": "text", "Text": "你好,请做个自我介绍"}]}
2026-03-04 11:26:53,428 - INFO - 对话输出 answer=你好!我是高飞-341,一个智能助手,随时为你提供帮助。我可以协助完成各种任务,比如信息查询、行程规划等。如果有任何需要,请随时告诉我!
2026-03-04 11:26:53,428 - INFO - 统计指标 metrics={"TTFT": 3.563931, "tokens_per_second": 44.899566, "input_tokens": 3440, "output_tokens": 78, "all_time": 5.27887}
2026-03-04 11:26:53,428 - INFO - 完整结果: {"status": "success", "chat_version": "v2", "chat_location": "send", "app_id": "2020711113026945536", "request_id": "596a831b-8b2c-4ba5-9bae-a24bb4e17453", "session_id": "401d5ef2-fb68-4341-9d99-06199df6f6e9", "visitor_biz_id": "2020711113026945536_0", "metrics": {"TTFT": 3.563931, "tokens_per_second": 44.899566, "input_tokens": 3440, "output_tokens": 78, "all_time": 5.27887}, "answer": "你好!我是高飞-341,一个智能助手,随时为你提供帮助。我可以协助完成各种任务,比如信息查询、行程规划等。如果有任何需要,请随时告诉我!", "stat_info": {"InputTokens": 3440, "OutputTokens": 78, "TotalTokens": 3518, "TotalCost": "5104"}}
目前为止单个对话的功能就没有问题了, 接下来要开始编写压测脚本。
第三个提示词:编写压测脚本
根据当前的实现,我希望你封装一个locust脚本,用来压测大模型。 所以需要你做以下的事情:
1. 改造现有脚本,可以让locust进行调用。
2. 需要使用locust的events.request.fire定义新的指标,统计:
a. TTFT: 发送请求后到大模型的首个token的返回的延时。
b. tokens_per_second:抛除首个token后,每秒返回给用户的token数量。
c. input_tokens: 大模型输入的token数量。
d. output_tokens: 大模型输出的token数量。
e. all_time:本次请求的总耗时。
这些数据可以从对话脚本中拿到
第四个提示词:编写 nohup 脚本,后台执行。
根据当前实现,帮我编写一个nohup shell脚本,用来在后台执行。 要求:
1. 默认1并发执行。
2. 测试结果输出到execel文件中。
nohup 的执行日志:
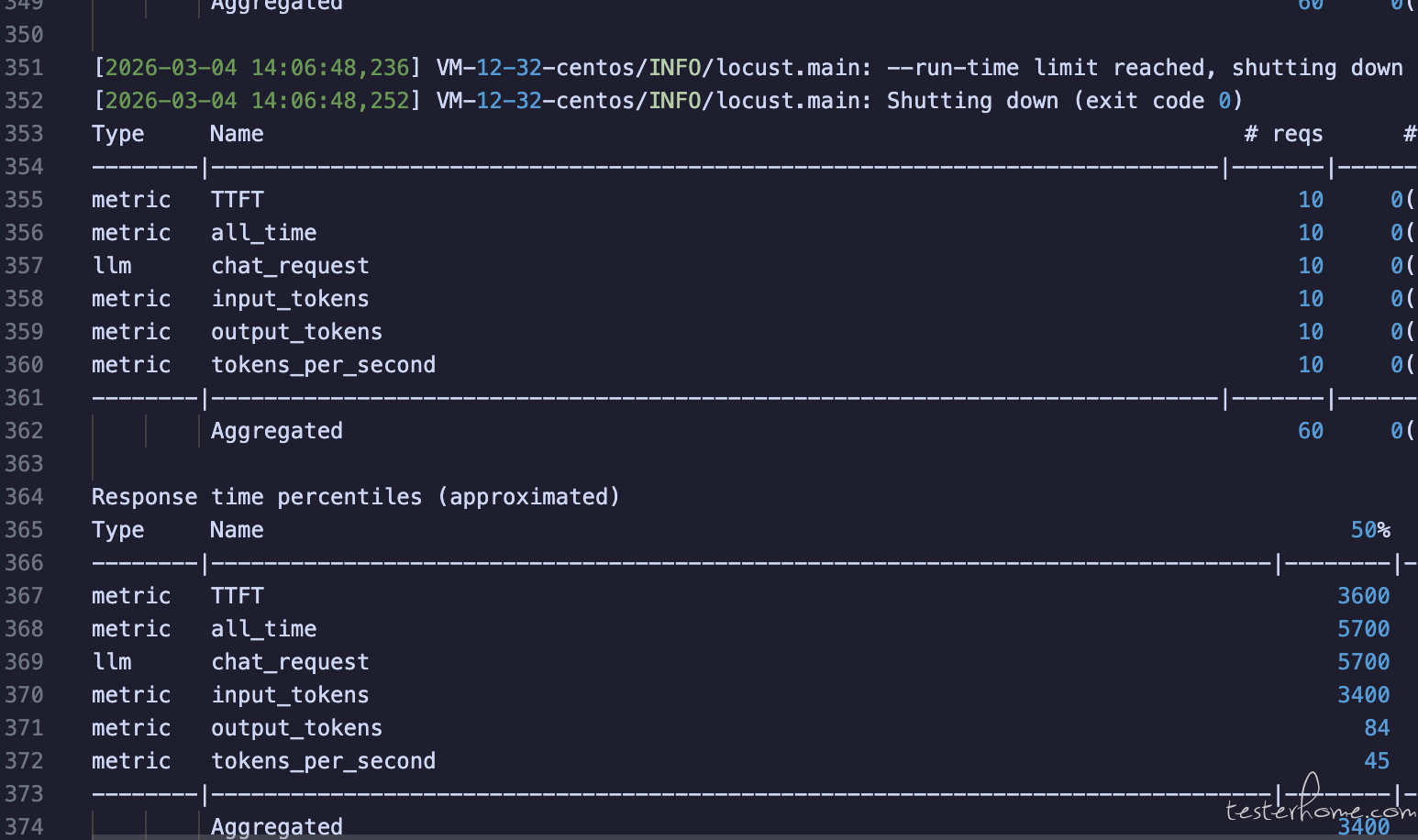
总结
以上就是这个工具的主要流程,基本上四次对话就完成了,后续根据一些场景再进行修改即可。我大概花费了 10 几分钟的时候,就把以前基本上需要几个小时的工作量完成了。
最后再宣传下我的星球,我会定期更新 AI 和测试相关内容。

转载文章时务必注明原作者及原始链接,并注明「发表于 TesterHome 」,并不得对作品进行修改。
如果觉得我的文章对您有用,请随意打赏。您的支持将鼓励我继续创作!
暫無回覆。