意图识别概述
什么是意图识别
意图识别(Intent Recognition)是智能体中最重要任务之一,也是一切的开始,目的在于通过用户输入的问题,理解用户输入文本背后的真实意图。这样才能决策应该由哪一个子系统或模块来处理用户的请求。
我之前曾经发过一张对话机器人的流程图:
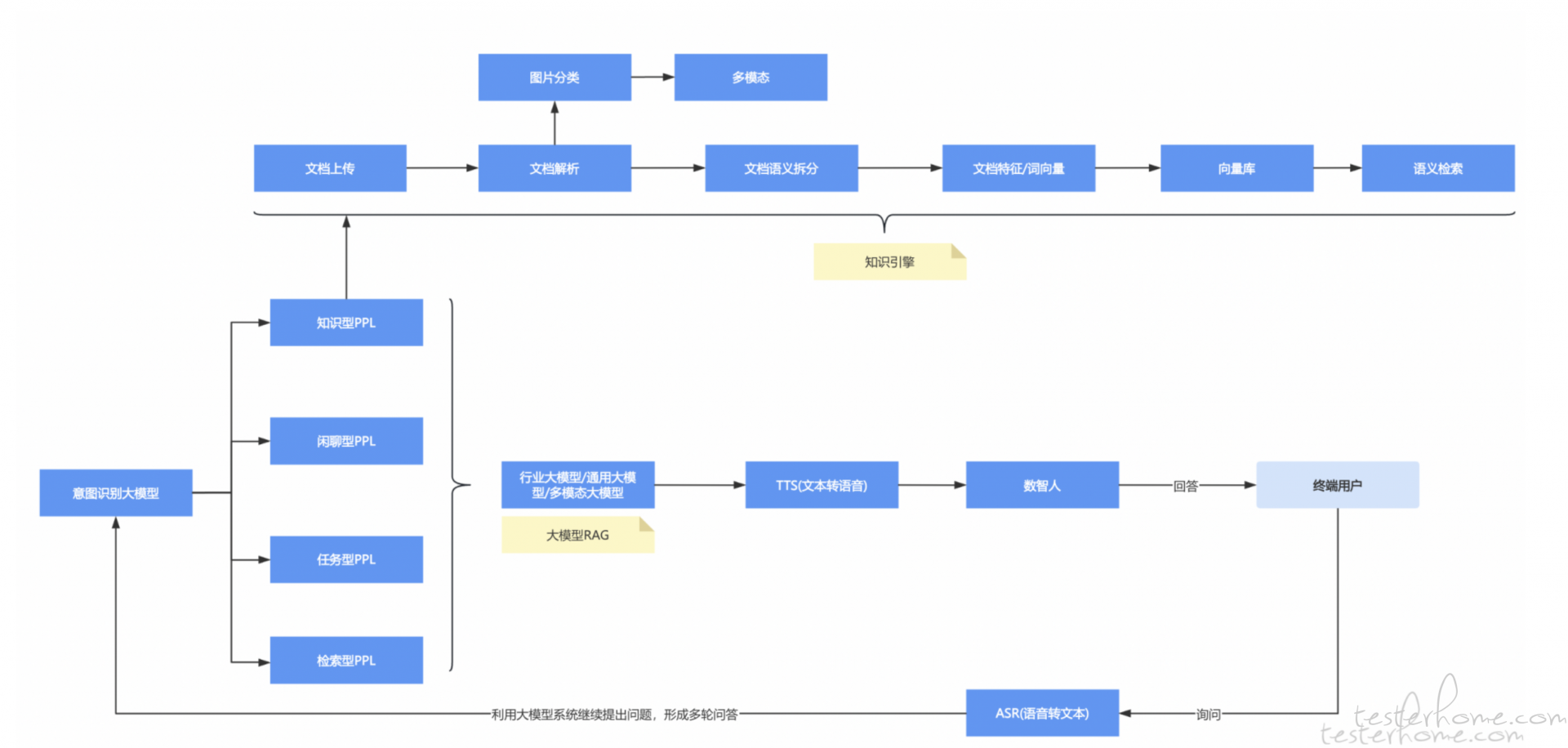
在智能体系统中,意图识别是对话路由的关键环节。
意图识别的核心作用:
用户输入 → 意图识别 → 路由到对应模块
"帮我查天气" → 天气查询意图 → 天气服务模块
"讲个笑话" → 娱乐意图 → 娱乐服务模块
"什么是AI" → 知识问答意图 → 知识库模块
意图识别的应用场景
| 场景 | 说明 | 示例意图 |
|---|---|---|
| 智能客服 | 将用户问题分类到不同业务模块 | 订单查询、退款申请、技术支持 |
| 智能助手 | 理解用户指令并执行相应操作 | 设置提醒、发送消息、播放音乐 |
| 内容推荐 | 根据用户意图推荐相关内容 | 学习、娱乐、购物、新闻 |
| 对话系统 | 维护多轮对话的上下文理解 | 继续对话、澄清问题、切换话题 |
意图识别的技术挑战
1. 语言多样性
# 同一个意图,不同的表达方式
意图:天气查询
表达1: "今天天气怎么样?"
表达2: "明天会下雨吗?"
表达3: "北京现在多少度?"
表达4: "帮我看看天气预报"
2. 上下文依赖
# 需要结合上下文才能理解意图
用户: "我想买手机"
助手: "您想买什么品牌的手机?"
用户: "苹果的" # 这里的意图是"品牌选择",不是"购买手机"
3. 多意图混合
# 一句话包含多个意图
"帮我查一下明天的天气,然后提醒我带伞"
# 包含:天气查询 + 设置提醒
4. 意图边界模糊
# 意图边界不清晰
"我想了解一下Python" # 是"学习咨询"还是"技术问答"?
意图识别实现方法
基于提示词的意图识别
在实际的智能体系统中,意图识别通常通过动态组装提示词来实现。这种方法的核心思想是:
1. 系统工具描述作为意图来源
# 系统工具定义示例
system_tools = {
"weather_query": {
"name": "天气查询",
"description": "查询指定城市的天气信息",
"parameters": ["city_name"]
},
"order_query": {
"name": "订单查询",
"description": "查询用户的订单状态和详情",
"parameters": ["order_id"]
},
"knowledge_qa": {
"name": "知识问答",
"description": "回答用户的知识性问题",
"parameters": ["question"]
}
}
2. 动态组装提示词
现在我们模拟智能体系统中意图识别的方法。实际上,意图识别就是提示词工程。 如上面的代码中,系统会定义好当前能够使用的工具或者模块的信息与描述。再把这些
描述拼装到提示词中,意思是告诉大模型现在系统中有这些工具,请大模型结合用户的问题来判断应该由哪个工具来完成用户的需求。
def build_intent_recognition_prompt(user_input, system_tools):
"""构建意图识别提示词"""
# 基础提示词模板
base_prompt = """你是一个智能助手,需要识别用户的意图。
用户输入:{user_input}
请从以下意图中选择最匹配的一个:
{intent_options}
请只返回意图名称,不要返回其他内容。"""
# 从系统工具生成意图选项
intent_options = []
for tool_id, tool_info in system_tools.items():
intent_options.append(f"- {tool_id}: {tool_info['description']}")
# 添加系统内置意图
system_intents = [
"- greeting: 用户进行问候或打招呼",
"- self_cognition: 用户询问助手自身信息",
"- instruction_following: 用户给出指令或要求",
"- small_talk: 用户进行闲聊",
"- unknown: 无法识别的意图"
]
intent_options.extend(system_intents)
# 组装完整提示词
prompt = base_prompt.format(
user_input=user_input,
intent_options="\n".join(intent_options)
)
return prompt
3. 意图识别流程
def recognize_intent(user_input, system_tools, llm_model):
"""识别用户意图"""
# 1. 构建提示词
prompt = build_intent_recognition_prompt(user_input, system_tools)
# 2. 调用大模型
response = llm_model.generate(prompt)
# 3. 解析意图
intent = parse_intent_from_response(response)
return intent
def parse_intent_from_response(response):
"""从模型响应中解析意图"""
# 简单的意图解析逻辑
response = response.strip().lower()
# 匹配意图ID
intent_patterns = {
"weather_query": ["天气", "weather"],
"order_query": ["订单", "order"],
"knowledge_qa": ["问题", "知识", "question"],
"greeting": ["你好", "hello", "hi"],
"self_cognition": ["你是谁", "what are you"],
"instruction_following": ["帮我", "请", "help"],
"small_talk": ["聊天", "聊", "talk"]
}
for intent, patterns in intent_patterns.items():
if any(pattern in response for pattern in patterns):
return intent
return "unknown"
意图识别的优势
1. 动态性
- 可以根据系统工具变化动态调整意图选项
- 无需重新训练模型,只需更新提示词
2. 可解释性
- 意图来源清晰,来自系统工具描述
- 便于调试和优化
3. 扩展性
- 新增工具时自动增加对应意图
- 支持自定义系统意图
4. 一致性
- 意图定义与工具描述保持一致
- 减少意图与功能不匹配的问题
提示词优化策略
1. 意图描述优化
# 优化前
"weather_query: 查询天气"
# 优化后
"weather_query: 查询指定城市的天气信息,包括温度、湿度、风力等"
2. 示例优化
def build_enhanced_prompt(user_input, system_tools):
"""构建增强版提示词"""
prompt = """你是一个智能助手,需要识别用户的意图。
用户输入:{user_input}
请从以下意图中选择最匹配的一个:
{intent_options}
示例:
- 用户说"今天北京天气怎么样" → weather_query
- 用户说"你好" → greeting
- 用户说"帮我查订单12345" → order_query
- 用户说"什么是人工智能" → knowledge_qa
请只返回意图名称,不要返回其他内容。"""
return prompt
3. 上下文优化
def build_context_aware_prompt(user_input, system_tools, conversation_history):
"""构建上下文感知的提示词"""
context = ""
if conversation_history:
context = f"\n对话历史:\n{conversation_history}\n"
prompt = f"""你是一个智能助手,需要识别用户的意图。
{context}用户输入:{user_input}
请从以下意图中选择最匹配的一个:
{intent_options}
请只返回意图名称,不要返回其他内容。"""
return prompt
意图识别评测方法
评测维度
1. 准确性(Accuracy)
- 整体分类准确率
- 各类别准确率
- 混淆矩阵分析
2. 鲁棒性(Robustness)
- 对同义词的识别能力
- 对语法变化的适应性
- 对噪声的抵抗能力
3. 泛化性(Generalization)
- 对未见过的表达方式的处理
- 跨领域迁移能力
- 新意图的学习能力
4. 实时性(Real-time)
- 响应延迟
- 吞吐量
- 资源消耗
评测指标详解
1. 基础指标
# 准确率(Accuracy)
accuracy = (TP + TN) / (TP + TN + FP + FN)
# 精确率(Precision)
precision = TP / (TP + FP)
# 召回率(Recall)
recall = TP / (TP + FN)
# F1分数
f1 = 2 * (precision * recall) / (precision + recall)
通过上面我们知道意图识别本质上还是一个多分类场景,所以混淆矩阵,精准/召回/F1 这些指标依然是有效的。 当然使用简单的准确率也是可以的。 至于二分类/多分类的概念和相关指标可以看我之前的文章。
测试脚本
既然知道意图识别就是一个多分类场景, 那么其实测试工具编写起来就容易了, 为了方便测试,我们可以 mock 一个意图识别大模型:
# -*- coding: utf-8 -*-
"""
意图识别评测实战代码
支持多种意图识别模型的评测和对比
"""
import json
import time
import random
import numpy as np
import pandas as pd
from typing import List, Dict, Any, Optional, Tuple
from datetime import datetime
from sklearn.metrics import (
accuracy_score, precision_score, recall_score, f1_score,
confusion_matrix, classification_report
)
from sklearn.model_selection import train_test_split
class MockIntentModel:
"""Mock意图识别模型"""
def __init__(self, intent_list=None, random_seed=42):
"""
初始化Mock模型
Args:
intent_list: 意图列表
random_seed: 随机种子
"""
import random
random.seed(random_seed)
self.intent_list = intent_list or [
"greeting", "weather_query", "order_query", "knowledge_qa",
"self_cognition", "instruction_following", "small_talk", "unknown"
]
# 设置不同意图的权重(模拟真实模型的倾向性)
self.intent_weights = {
"greeting": 0.15,
"weather_query": 0.20,
"order_query": 0.15,
"knowledge_qa": 0.20,
"self_cognition": 0.10,
"instruction_following": 0.10,
"small_talk": 0.05,
"unknown": 0.05
}
def predict(self, texts):
"""
预测意图
Args:
texts: 输入文本列表
Returns:
预测的意图列表
"""
predictions = []
for text in texts:
# 基于关键词的简单规则预测
intent = self._rule_based_predict(text)
# 添加随机性模拟真实模型的不确定性
if random.random() < 0.1: # 10%概率随机选择
intent = random.choices(
list(self.intent_weights.keys()),
weights=list(self.intent_weights.values())
)[0]
predictions.append(intent)
return predictions
def _rule_based_predict(self, text):
"""基于规则的预测"""
text_lower = text.lower()
# 关键词匹配规则
if any(word in text_lower for word in ["你好", "您好", "hi", "hello", "早上好", "下午好"]):
return "greeting"
elif any(word in text_lower for word in ["天气", "weather", "下雨", "晴天", "温度"]):
return "weather_query"
elif any(word in text_lower for word in ["订单", "order", "购买", "支付", "发货"]):
return "order_query"
elif any(word in text_lower for word in ["问题", "知识", "question", "什么是", "如何"]):
return "knowledge_qa"
elif any(word in text_lower for word in ["你是谁", "what are you", "介绍", "功能"]):
return "self_cognition"
elif any(word in text_lower for word in ["帮我", "请", "help", "指令", "要求"]):
return "instruction_following"
elif any(word in text_lower for word in ["聊天", "聊", "talk", "闲聊"]):
return "small_talk"
else:
return "unknown"
class IntentEvaluationFramework:
"""意图识别评测框架"""
def __init__(self, model=None, test_data=None):
"""
初始化评测框架
Args:
model: 意图识别模型
test_data: 测试数据
"""
self.model = model
self.test_data = test_data
self.results = {}
self.predictions = []
self.true_labels = []
def load_test_data(self, data_file: str):
"""加载测试数据"""
with open(data_file, 'r', encoding='utf-8') as f:
self.test_data = [json.loads(line) for line in f]
print(f"✅ 测试数据加载完成: {len(self.test_data)} 条")
return self.test_data
def evaluate_accuracy(self) -> Dict[str, float]:
"""评测准确率"""
if not self.model or not self.test_data:
raise ValueError("模型或测试数据未加载")
predictions = []
true_labels = []
print("开始意图识别评测...")
for i, item in enumerate(self.test_data):
# 获取预测结果
if hasattr(self.model, 'predict'):
pred = self.model.predict([item['text']])[0]
else:
# 使用SDK进行预测
pred = self._predict_with_sdk(item['text'])
predictions.append(pred)
true_labels.append(item['intent'])
# 显示进度
if (i + 1) % 50 == 0:
print(f"已处理: {i + 1}/{len(self.test_data)}")
# 计算准确率
accuracy = accuracy_score(true_labels, predictions)
# 计算各类别指标
precision = precision_score(true_labels, predictions, average='weighted')
recall = recall_score(true_labels, predictions, average='weighted')
f1 = f1_score(true_labels, predictions, average='weighted')
# 计算宏平均和微平均
precision_macro = precision_score(true_labels, predictions, average='macro')
recall_macro = recall_score(true_labels, predictions, average='macro')
f1_macro = f1_score(true_labels, predictions, average='macro')
self.predictions = predictions
self.true_labels = true_labels
results = {
'accuracy': accuracy,
'precision_weighted': precision,
'recall_weighted': recall,
'f1_weighted': f1,
'precision_macro': precision_macro,
'recall_macro': recall_macro,
'f1_macro': f1_macro
}
self.results['accuracy'] = results
return results
def evaluate_robustness(self) -> Dict[str, Any]:
"""评测鲁棒性"""
if not self.test_data:
raise ValueError("测试数据未加载")
robustness_tests = {
'typo_test': self._test_typos(),
'synonym_test': self._test_synonyms(),
'case_test': self._test_case_variations(),
'punctuation_test': self._test_punctuation()
}
self.results['robustness'] = robustness_tests
return robustness_tests
def evaluate_performance(self) -> Dict[str, float]:
"""评测性能"""
if not self.model or not self.test_data:
raise ValueError("模型或测试数据未加载")
# 测试响应时间
response_times = []
for item in self.test_data[:100]: # 测试前100条
start_time = time.time()
if hasattr(self.model, 'predict'):
self.model.predict([item['text']])
else:
self._predict_with_sdk(item['text'])
end_time = time.time()
response_times.append(end_time - start_time)
# 计算性能指标
avg_response_time = np.mean(response_times)
p95_response_time = np.percentile(response_times, 95)
p99_response_time = np.percentile(response_times, 99)
# 测试吞吐量
throughput = self._test_throughput()
results = {
'avg_response_time': avg_response_time,
'p95_response_time': p95_response_time,
'p99_response_time': p99_response_time,
'throughput': throughput
}
self.results['performance'] = results
return results
def generate_confusion_matrix(self, save_path: str = None):
"""生成并打印混淆矩阵(文本表格形式)"""
if not self.predictions or not self.true_labels:
raise ValueError("需要先运行准确率评测")
# 获取所有类别
all_labels = sorted(list(set(self.true_labels + self.predictions)))
# 计算混淆矩阵
cm = confusion_matrix(self.true_labels, self.predictions, labels=all_labels)
# 在控制台打印混淆矩阵
print("\n混淆矩阵:")
print("=" * 80)
# 打印表头
header = "真实\\预测"
print(f"{header:>20s}", end='')
for label in all_labels:
print(f"{label:>15s}", end='')
print()
print("-" * 80)
# 打印每一行
for i, true_label in enumerate(all_labels):
print(f"{true_label:>20s}", end='')
for j, pred_label in enumerate(all_labels):
print(f"{cm[i][j]:>15d}", end='')
print()
print("=" * 80)
return cm
def generate_classification_report(self) -> str:
"""生成分类报告"""
if not self.predictions or not self.true_labels:
raise ValueError("需要先运行准确率评测")
report = classification_report(
self.true_labels, self.predictions,
output_dict=True
)
# 打印报告
print("\n" + "="*60)
print("意图识别分类报告")
print("="*60)
print(classification_report(self.true_labels, self.predictions))
return report
def compare_models(self, models: Dict[str, Any]) -> Dict[str, Any]:
"""对比多个模型"""
comparison_results = {}
for model_name, model in models.items():
print(f"\n评测模型: {model_name}")
# 临时设置模型
original_model = self.model
self.model = model
# 运行评测
accuracy_results = self.evaluate_accuracy()
performance_results = self.evaluate_performance()
comparison_results[model_name] = {
'accuracy': accuracy_results,
'performance': performance_results
}
# 恢复原模型
self.model = original_model
# 生成对比报告
self._generate_comparison_report(comparison_results)
return comparison_results
def generate_report(self, output_file: str = None) -> Dict[str, Any]:
"""生成完整评测报告"""
report = {
'evaluation_time': datetime.now().isoformat(),
'dataset_size': len(self.test_data) if self.test_data else 0,
'model_info': self._get_model_info(),
'results': self.results
}
# 打印摘要
print("\n" + "="*60)
print("意图识别评测报告")
print("="*60)
if 'accuracy' in self.results:
acc_results = self.results['accuracy']
print(f"准确率: {acc_results['accuracy']:.4f}")
print(f"精确率: {acc_results['precision']:.4f}")
print(f"召回率: {acc_results['recall']:.4f}")
print(f"F1分数: {acc_results['f1_score']:.4f}")
if 'performance' in self.results:
perf_results = self.results['performance']
print(f"\n平均响应时间: {perf_results['avg_response_time']:.4f}s")
print(f"P95响应时间: {perf_results['p95_response_time']:.4f}s")
print(f"吞吐量: {perf_results['throughput']:.2f} QPS")
print("="*60)
# 保存报告
if output_file:
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(report, f, ensure_ascii=False, indent=2)
print(f"\n报告已保存到: {output_file}")
return report
def _predict_with_sdk(self, text: str) -> str:
"""使用SDK进行预测"""
# 这里需要根据实际的SDK接口进行实现
# 示例代码,实际使用时需要替换为真实的API调用
try:
# 假设使用腾讯云智能体SDK
if hasattr(self, 'sdk'):
response = self.sdk.simple_chat(f"请识别以下文本的意图: {text}")
# 从响应中提取意图(这里需要根据实际API响应格式调整)
return self._extract_intent_from_response(response)
else:
# 模拟预测结果
return "unknown"
except Exception as e:
print(f"预测失败: {e}")
return "error"
def _extract_intent_from_response(self, response: str) -> str:
"""从响应中提取意图"""
# 这里需要根据实际的API响应格式进行实现
# 示例代码,实际使用时需要替换为真实的解析逻辑
intent_mapping = {
"问候": "greeting",
"天气": "weather",
"订单": "order",
"帮助": "support"
}
for keyword, intent in intent_mapping.items():
if keyword in response:
return intent
return "unknown"
def _test_typos(self) -> Dict[str, float]:
"""测试拼写错误鲁棒性"""
# 简单的拼写错误测试
typo_tests = [
("你好", "你号"), # 同音字错误
("天气", "天汽"), # 形近字错误
("订单", "定单"), # 同音字错误
]
results = {}
for original, typo in typo_tests:
# 测试原始文本和错误文本的预测结果
if hasattr(self.model, 'predict'):
orig_pred = self.model.predict([original])[0]
typo_pred = self.model.predict([typo])[0]
else:
orig_pred = self._predict_with_sdk(original)
typo_pred = self._predict_with_sdk(typo)
# 计算一致性
consistency = 1.0 if orig_pred == typo_pred else 0.0
results[f"{original}_vs_{typo}"] = consistency
return results
def _test_synonyms(self) -> Dict[str, float]:
"""测试同义词鲁棒性"""
synonym_tests = [
("你好", "您好"),
("天气", "气候"),
("订单", "定单"),
]
results = {}
for word1, word2 in synonym_tests:
if hasattr(self.model, 'predict'):
pred1 = self.model.predict([word1])[0]
pred2 = self.model.predict([word2])[0]
else:
pred1 = self._predict_with_sdk(word1)
pred2 = self._predict_with_sdk(word2)
consistency = 1.0 if pred1 == pred2 else 0.0
results[f"{word1}_vs_{word2}"] = consistency
return results
def _test_case_variations(self) -> Dict[str, float]:
"""测试大小写变化鲁棒性"""
case_tests = [
("你好", "你好"),
("你好", "HELLO"),
("天气", "天气"),
]
results = {}
for original, variation in case_tests:
if hasattr(self.model, 'predict'):
orig_pred = self.model.predict([original])[0]
var_pred = self.model.predict([variation])[0]
else:
orig_pred = self._predict_with_sdk(original)
var_pred = self._predict_with_sdk(variation)
consistency = 1.0 if orig_pred == var_pred else 0.0
results[f"{original}_vs_{variation}"] = consistency
return results
def _test_punctuation(self) -> Dict[str, float]:
"""测试标点符号鲁棒性"""
punctuation_tests = [
("你好", "你好!"),
("天气", "天气?"),
("订单", "订单。"),
]
results = {}
for original, with_punct in punctuation_tests:
if hasattr(self.model, 'predict'):
orig_pred = self.model.predict([original])[0]
punct_pred = self.model.predict([with_punct])[0]
else:
orig_pred = self._predict_with_sdk(original)
punct_pred = self._predict_with_sdk(with_punct)
consistency = 1.0 if orig_pred == punct_pred else 0.0
results[f"{original}_vs_{with_punct}"] = consistency
return results
def _test_throughput(self) -> float:
"""测试吞吐量"""
if not self.model or not self.test_data:
return 0.0
# 测试批量处理
batch_size = 10
test_samples = self.test_data[:50] # 使用前50个样本
start_time = time.time()
for i in range(0, len(test_samples), batch_size):
batch = test_samples[i:i+batch_size]
batch_texts = [item['text'] for item in batch]
if hasattr(self.model, 'predict'):
self.model.predict(batch_texts)
else:
for text in batch_texts:
self._predict_with_sdk(text)
end_time = time.time()
total_time = end_time - start_time
# 计算QPS
qps = len(test_samples) / total_time
return qps
def _get_model_info(self) -> Dict[str, Any]:
"""获取模型信息"""
if not self.model:
return {"type": "unknown", "name": "unknown"}
model_info = {
"type": type(self.model).__name__,
"name": getattr(self.model, 'name', 'unknown')
}
# 添加更多模型信息
if hasattr(self.model, 'get_params'):
model_info["parameters"] = self.model.get_params()
return model_info
def _generate_comparison_report(self, comparison_results: Dict[str, Any]):
"""生成对比报告"""
print("\n" + "="*80)
print("模型对比报告")
print("="*80)
# 创建对比表格
comparison_data = []
for model_name, results in comparison_results.items():
row = {
'模型': model_name,
'准确率': results['accuracy']['accuracy'],
'F1分数': results['accuracy']['f1_score'],
'平均响应时间': results['performance']['avg_response_time'],
'吞吐量': results['performance']['throughput']
}
comparison_data.append(row)
# 转换为DataFrame并打印
df = pd.DataFrame(comparison_data)
print(df.to_string(index=False, float_format='%.4f'))
# 找出最佳模型
best_accuracy_model = max(comparison_results.keys(),
key=lambda x: comparison_results[x]['accuracy']['accuracy'])
best_performance_model = max(comparison_results.keys(),
key=lambda x: comparison_results[x]['performance']['throughput'])
print(f"\n最佳准确率模型: {best_accuracy_model}")
print(f"最佳性能模型: {best_performance_model}")
print("="*80)
class IntentTestDataGenerator:
"""意图识别测试数据生成器"""
def __init__(self):
self.intent_templates = {
"greeting": [
"你好", "您好", "早上好", "下午好", "晚上好",
"hi", "hello", "hey", "嗨"
],
"weather": [
"今天天气怎么样", "明天会下雨吗", "北京现在多少度",
"天气预报", "气温如何", "会下雪吗"
],
"order": [
"我的订单状态", "查询订单", "订单什么时候发货",
"取消订单", "修改订单", "订单详情"
],
"support": [
"需要帮助", "有问题", "故障", "咨询",
"技术支持", "客服", "人工服务"
],
"product": [
"这个商品怎么样", "有货吗", "价格多少",
"商品详情", "规格参数", "用户评价"
]
}
def generate_test_data(self, samples_per_intent: int = 100) -> List[Dict[str, Any]]:
"""生成测试数据"""
test_data = []
for intent, templates in self.intent_templates.items():
for i in range(samples_per_intent):
# 随机选择一个模板
template = np.random.choice(templates)
# 添加一些变化
text = self._add_variations(template)
test_data.append({
"text": text,
"intent": intent,
"confidence": np.random.uniform(0.8, 1.0)
})
return test_data
def _add_variations(self, text: str) -> str:
"""添加文本变化"""
variations = [
lambda x: x + "?",
lambda x: x + "!",
lambda x: "请问" + x,
lambda x: x + "谢谢",
lambda x: "我想" + x,
]
# 随机应用变化
if np.random.random() < 0.3: # 30%概率添加变化
variation = np.random.choice(variations)
text = variation(text)
return text
def save_test_data(self, test_data: List[Dict[str, Any]], file_path: str):
"""保存测试数据"""
with open(file_path, 'w', encoding='utf-8') as f:
for item in test_data:
f.write(json.dumps(item, ensure_ascii=False) + '\n')
print(f"✅ 测试数据已保存到: {file_path}")
然后我们编写一个测试脚本:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
意图识别测试演示脚本
使用Mock模型进行意图识别评测,统计混淆矩阵、精确率和召回率
"""
import json
from sklearn.metrics import (
accuracy_score, precision_score, recall_score, f1_score,
confusion_matrix, classification_report
)
from intent_evaluation import MockIntentModel, IntentTestDataGenerator
def create_test_dataset():
"""创建测试数据集"""
test_data = [
# 问候类
{"text": "你好", "intent": "greeting"},
{"text": "您好", "intent": "greeting"},
{"text": "早上好", "intent": "greeting"},
{"text": "hi", "intent": "greeting"},
{"text": "hello", "intent": "greeting"},
# 天气查询类
{"text": "今天天气怎么样", "intent": "weather_query"},
{"text": "北京天气如何", "intent": "weather_query"},
{"text": "明天会下雨吗", "intent": "weather_query"},
{"text": "上海现在多少度", "intent": "weather_query"},
{"text": "weather forecast", "intent": "weather_query"},
# 订单查询类
{"text": "我的订单状态", "intent": "order_query"},
{"text": "查询订单12345", "intent": "order_query"},
{"text": "订单什么时候发货", "intent": "order_query"},
{"text": "order status", "intent": "order_query"},
{"text": "购买记录", "intent": "order_query"},
# 知识问答类
{"text": "什么是人工智能", "intent": "knowledge_qa"},
{"text": "如何学习Python", "intent": "knowledge_qa"},
{"text": "Python是什么", "intent": "knowledge_qa"},
{"text": "机器学习原理", "intent": "knowledge_qa"},
{"text": "what is AI", "intent": "knowledge_qa"},
# 自我认知类
{"text": "你是谁", "intent": "self_cognition"},
{"text": "介绍一下自己", "intent": "self_cognition"},
{"text": "你有什么功能", "intent": "self_cognition"},
{"text": "what are you", "intent": "self_cognition"},
{"text": "你能做什么", "intent": "self_cognition"},
# 指令遵循类
{"text": "帮我查一下", "intent": "instruction_following"},
{"text": "请帮我", "intent": "instruction_following"},
{"text": "帮我做", "intent": "instruction_following"},
{"text": "请执行", "intent": "instruction_following"},
{"text": "help me", "intent": "instruction_following"},
# 闲聊类
{"text": "聊聊天", "intent": "small_talk"},
{"text": "随便聊聊", "intent": "small_talk"},
{"text": "聊一聊", "intent": "small_talk"},
{"text": "let's chat", "intent": "small_talk"},
{"text": "闲聊", "intent": "small_talk"},
# 未知类
{"text": "随机文本", "intent": "unknown"},
{"text": "asdfgh", "intent": "unknown"},
{"text": "123456", "intent": "unknown"},
{"text": "!@#$%", "intent": "unknown"},
{"text": "无意义内容", "intent": "unknown"},
]
return test_data
def run_intent_evaluation():
"""运行意图识别评测"""
print("="*60)
print("意图识别评测演示")
print("="*60)
# 1. 创建测试数据
print("\n1. 创建测试数据...")
test_data = create_test_dataset()
print(f"✅ 测试数据创建完成,共 {len(test_data)} 条")
# 2. 创建Mock模型
print("\n2. 创建Mock意图识别模型...")
mock_model = MockIntentModel()
print("✅ Mock模型创建完成")
# 3. 运行预测
print("\n3. 运行意图识别...")
texts = [item['text'] for item in test_data]
true_labels = [item['intent'] for item in test_data]
predictions = mock_model.predict(texts)
print("✅ 意图识别完成")
# 4. 计算评测指标
print("\n4. 计算评测指标...")
# 基础指标
accuracy = accuracy_score(true_labels, predictions)
precision_weighted = precision_score(true_labels, predictions, average='weighted')
recall_weighted = recall_score(true_labels, predictions, average='weighted')
f1_weighted = f1_score(true_labels, predictions, average='weighted')
precision_macro = precision_score(true_labels, predictions, average='macro')
recall_macro = recall_score(true_labels, predictions, average='macro')
f1_macro = f1_score(true_labels, predictions, average='macro')
# 5. 打印结果
print("\n" + "="*60)
print("评测结果")
print("="*60)
print(f"准确率 (Accuracy): {accuracy:.4f}")
print(f"加权精确率 (Precision Weighted): {precision_weighted:.4f}")
print(f"加权召回率 (Recall Weighted): {recall_weighted:.4f}")
print(f"加权F1分数 (F1 Weighted): {f1_weighted:.4f}")
print(f"宏平均精确率 (Precision Macro): {precision_macro:.4f}")
print(f"宏平均召回率 (Recall Macro): {recall_macro:.4f}")
print(f"宏平均F1分数 (F1 Macro): {f1_macro:.4f}")
# 6. 生成混淆矩阵
print("\n5. 生成混淆矩阵...")
create_confusion_matrix(true_labels, predictions)
# 7. 生成分类报告
print("\n6. 生成分类报告...")
generate_classification_report(true_labels, predictions)
# 8. 分析错误案例
print("\n7. 分析错误案例...")
analyze_error_cases(test_data, true_labels, predictions)
# 9. 保存结果
print("\n8. 保存结果...")
save_results(test_data, true_labels, predictions, {
'accuracy': accuracy,
'precision_weighted': precision_weighted,
'recall_weighted': recall_weighted,
'f1_weighted': f1_weighted,
'precision_macro': precision_macro,
'recall_macro': recall_macro,
'f1_macro': f1_macro
})
print("\n" + "="*60)
print("评测完成!")
print("="*60)
def create_confusion_matrix(true_labels, predictions):
"""创建并打印混淆矩阵"""
# 获取所有类别
all_labels = sorted(list(set(true_labels + predictions)))
# 计算混淆矩阵
cm = confusion_matrix(true_labels, predictions, labels=all_labels)
# 在控制台打印混淆矩阵
print("\n混淆矩阵:")
print("=" * 80)
# 打印表头
header = "真实\\预测"
print(f"{header:>20s}", end='')
for label in all_labels:
print(f"{label:>15s}", end='')
print()
print("-" * 80)
# 打印每一行
for i, true_label in enumerate(all_labels):
print(f"{true_label:>20s}", end='')
for j, pred_label in enumerate(all_labels):
print(f"{cm[i][j]:>15d}", end='')
print()
print("=" * 80)
print("✅ 混淆矩阵已生成")
def generate_classification_report(true_labels, predictions):
"""生成分类报告"""
print("\n" + "="*60)
print("详细分类报告")
print("="*60)
report = classification_report(true_labels, predictions, output_dict=True)
# 打印详细报告
print(classification_report(true_labels, predictions))
# 分析各类别表现
print("\n各类别详细分析:")
print("-" * 60)
for label, metrics in report.items():
if isinstance(metrics, dict) and 'precision' in metrics:
print(f"{label:20s}: 精确率={metrics['precision']:.3f}, "
f"召回率={metrics['recall']:.3f}, F1={metrics['f1-score']:.3f}, "
f"支持数={metrics['support']}")
def analyze_error_cases(test_data, true_labels, predictions):
"""分析错误案例"""
print("\n错误案例分析:")
print("-" * 60)
error_cases = []
for i, (true_label, pred_label) in enumerate(zip(true_labels, predictions)):
if true_label != pred_label:
error_cases.append({
'text': test_data[i]['text'],
'true_label': true_label,
'predicted_label': pred_label
})
print(f"总错误数: {len(error_cases)}")
print(f"错误率: {len(error_cases)/len(test_data)*100:.2f}%")
if error_cases:
print("\n前10个错误案例:")
for i, case in enumerate(error_cases[:10]):
print(f"{i+1:2d}. 文本: '{case['text']}'")
print(f" 真实: {case['true_label']} -> 预测: {case['predicted_label']}")
# 分析错误类型
error_types = {}
for case in error_cases:
error_key = f"{case['true_label']} -> {case['predicted_label']}"
error_types[error_key] = error_types.get(error_key, 0) + 1
print(f"\n错误类型分布:")
for error_type, count in sorted(error_types.items(), key=lambda x: x[1], reverse=True):
print(f" {error_type}: {count} 次")
def save_results(test_data, true_labels, predictions, metrics):
"""打印评测结果摘要"""
print("\n" + "="*60)
print("评测结果摘要")
print("="*60)
print(f"\n总样本数: {len(test_data)}")
print(f"正确预测数: {sum(1 for t, p in zip(true_labels, predictions) if t == p)}")
print(f"错误预测数: {sum(1 for t, p in zip(true_labels, predictions) if t != p)}")
# 统计各意图的预测情况
print("\n各意图预测统计:")
print("-" * 60)
intent_stats = {}
for true_label in set(true_labels):
correct = sum(1 for t, p in zip(true_labels, predictions) if t == true_label and t == p)
total = sum(1 for t in true_labels if t == true_label)
intent_stats[true_label] = {'correct': correct, 'total': total}
accuracy = correct / total if total > 0 else 0
print(f"{true_label:20s}: {correct:2d}/{total:2d} 正确 (准确率: {accuracy:.2%})")
print("\n✅ 评测结果统计完成")
def create_performance_analysis():
"""打印性能分析对比"""
print("\n9. 性能分析对比...")
# 模拟不同模型的表现数据
models = ['Mock模型', '规则模型', '机器学习模型', '深度学习模型']
accuracies = [0.75, 0.65, 0.80, 0.85]
f1_scores = [0.72, 0.62, 0.78, 0.83]
print("\n" + "="*60)
print("不同模型性能对比")
print("="*60)
print(f"\n{'模型名称':^20s} {'准确率':^15s} {'F1分数':^15s}")
print("-" * 60)
for model, acc, f1 in zip(models, accuracies, f1_scores):
print(f"{model:^20s} {acc:^15.3f} {f1:^15.3f}")
print("="*60)
# 找出最佳模型
best_acc_idx = accuracies.index(max(accuracies))
best_f1_idx = f1_scores.index(max(f1_scores))
print(f"\n最佳准确率: {models[best_acc_idx]} ({accuracies[best_acc_idx]:.3f})")
print(f"最佳F1分数: {models[best_f1_idx]} ({f1_scores[best_f1_idx]:.3f})")
print("\n✅ 性能对比分析完成")
if __name__ == "__main__":
# 运行意图识别评测
run_intent_evaluation()
# 创建性能分析
create_performance_analysis()
print("\n" + "="*60)
print("🎉 所有评测任务完成!")
print("="*60)
总结
AI 产品的测试向来都是工具易写,数据难找。本篇介绍的意图识别的测试方法说白了并没有很难。了解多分类评测的从业人员都可以针对性的进行测试。 关键还是能采集到用户真实的使用场景和相关数据。
更多内容可以加入我的星球,除了文字教程,我也会不定期直播教学。