
前言
老实讲分布式存储领域我并不是很专业, 我学习它是因为在工作中会有一些场景需要用到这些知识,比如:
- 在学习 K8S 的存储相关内容时,需要了解不同的存储系统对接 K8S 时的特性。
- 在高可用测试中,针对产品使用的不同的存储系统,设计对应的测试场景。
- 在大数据产品的测试中,需要了解不同的存储系统的特性以做出相关的测试设计,以及需要知道如何操作这些存储系统来完成测试。
所以对于我来说它更多的是作为延伸学习的内容。所以在这个系列的帖子中如果有描述的不正确的地方,也欢迎大家指正。
硬盘与文件系统的关系
本人比较懒惰,实在是不想从磁盘构造和文件系统原理开始记录了(磁头,磁道,扇区,inode,vfs,page cache 这些),相信大家也可以很容易的在社区中搜到这部分内容,所以我想精简一下,直接记录一些我认为比较重要的东西。
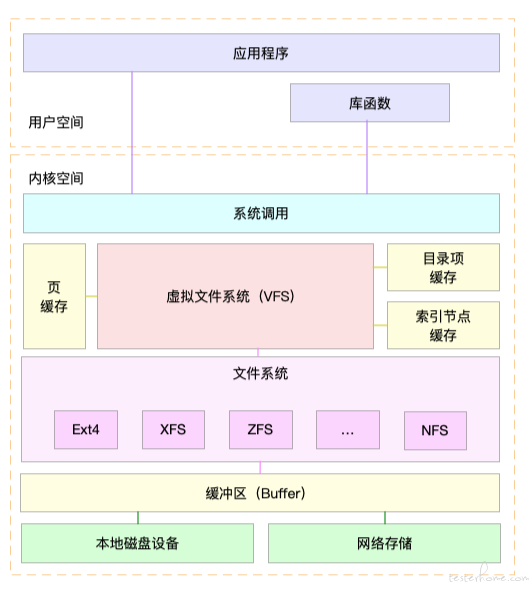
简单来说硬盘可以作为块设备直接挂载到操作系统中,此时它可以作为一个块设备供用户(后续再讲块存储,文件存储和对象存储的区别)使用,但块设备无法帮助用户组织数据的结构,需要用户自己针对数据块进行位置的记录,对齐,管理等等,这导致人类无法通过块设备来达到管理数据的目的。所以才需要文件系统针对数据进行管理,于是就有了文件和目录的概念,文件系统会记录每一个文件的数据,记录其中每一个数据块的位置(inode)和对应的目录结构。这样人类才能比较方便的针对数据进行管理。 而很多厂商都提供了不同的文件系统实现,为了统一接口 linux 又抽象出了 VFS(虚拟文件系统),操作系统直接操作 VFS,而各种文件系统都需要实现 VFS 声明的接口,这样就可以让操作系统很方便的对接所有的文件系统。 同事文件系统也拥有其他功能来提升用户的体验,比如通过 page cache(页缓存)来提升 IO 性能。
块存储
根据上面讲到的, 块存储主要是将裸磁盘空间整个映射给主机使用的,用户可以通过划分逻辑硬盘(Raid,LVM)等方式把多个物理硬盘划分为 1 个或者多个逻辑硬盘。比如 Raid(磁盘阵列,不同的 raid 等级有不同的效果,有的提升性能,有的提升数据安全性,也可以两者兼顾)可以把多个硬盘整和为一个或者多个逻辑盘,虽然此时可能磁盘空间并没有变化甚至变得更少了(Raid 中的镜像复制,为了数据安全考虑,需要一些空间把数据复制到另一个地方),但它的意义已经完全不一样了。
块存储的优点
- 通过 Raid 与 LVM 等手段将多块硬盘组合起来,成为一个大容量的逻辑盘对外提供服务,提高了容量,同时也提供了数据的保护。避免了硬盘损坏后数据就会丢失的风险。
- 写入数据的时候,由于是多块磁盘组合出来的逻辑盘,所以几块磁盘可以并行写入的,提升了读写效率。而且很多时候块存储采用 SAN 网络架构,由于其网络传输速率以及协议的原因,使得 IO 性能进一步提升。
块存储的缺点
- 最大的缺点是无法在服务器之间共享数据,块设备是排他性质的,只能作为本地磁盘供服务器使用。
- 和文件存储相比,没有文件和目录树的概念,使用块设备的软件需要自己记录一个文件都有哪些数据块,这些数据块保存在硬盘的什么位置,文件之间有什么关系,如何利用缓存优化 IO 性能等。 这也导致人类根本无法直接使用块设备,所以很多时候块设备都需要针对某个文件系统进行格式化才能使用,当然这就变成了文件存储。所以块设备的用户通常是文件系统或者告诉存储软件(比如 ceph 的 RBD 是面向块存储的接口)
文件存储
文件存储是构建在块设备之上的,用户通过文件系统来管理块设备中的数据。文件系统带来了文件与目录树的概念,使得用户更容易管理硬盘中的数据。同时文件系统并不是只针对独立的服务器的, 用户可以通过架设 FTP 或者 NFS 在网络中共享数据。
文件存储的优点
- 造价低,随便一台服务器就可以架设 NFS 或者 FTP 用来作为网络存储的方案,并且也不需要架设 SAN 网络。
- 便与数据共享,并且也符合人类管理数据的习惯 。
文件存储的缺点
- 性能差, 通过文件系统来检索文件会有不少的损耗(文件存储需要管理维护其庞大复杂的文件目录树)。有些文件系统比如 fat32,会将文件打算成多个数据块,然后在每个数据块的最后记录下一个数据块的位置,这样要找到一份数据需要对文件进行遍历。
对象存储
块存储速度快但不利于数据共享,文件存储擅长数据共享但 IO 性能差。 那有没有什么方案能兼顾性能和数据共享呢,这就是对象存储。 一般来说一个文件包含了它的数据和属性(也叫元数据-metadata,比如文件的大小,路径,修改时间等),而对象存储会专门把文件的 metadata 独立保存在元数据服务器中。比如 ceph 是非常流行的分布式存储系统,它整体都基于对象存储的设计思路。在它的 meta server 中会记录对象的数据被打散存放到了哪几台分布式服务器中的信息,在 ceph 中文件会被打散成 N 多个 object(可以理解为很小的数据块,默认我记得一个 object 是 4M 大小),而其他负责存储数据的服务叫 OSD,主要负责存储文件的数据部分。客户端的读写请求会先访问 meta server 来查询文件中的数据块都保存在哪些服务器中,然后会并发的从这些服务器中的 OSD 服务中进行数据交互。 因为是并发的读写机制,所以当 OSD 服务器数量越多,这种读写速度的提升就越大,当然每一个 OSD 在本地也会有大量的 IO 优化。
在用户视角中,对象存储往往是一个 key,value 形式的数据存储服务(因为对象存储不维护目录结构,需要通过 key 来查找对应的数据)。主要接口有 PUT/GET/DELETE 等。 所以对象存储适合处理离散的数据单元,不需要复杂的目录结构来组织数据,我觉得这是对象存储和文件存储最本质的区别。在刚接触分布式存储时,到底什么是对象存储,它与文件存储有什么区别是最困扰我的。不知道他们的区别就不了解为什么产品在这种场景下使用的是对象存储,而另一种场景下使用的是文件存储,而不了解目的就无法在测试中根据场景设计有效的测试用例。
结尾
总的来说:
- 直接使用块存储的性能是最高的,但由于快设备不具备数据管理的能力,并且无法在服务器你之间共享。所以导致大部分用户无法使用, 只有一些特殊的系统会直接针对块设备进行读写。而文件存储和对象存储是都构建在块存储之上的存储系统,它们各自封装了不同的能力让用户可以很方便的操作数据并且可以在互联网中进行数据的共享。
- 文件系统的性能是最差的(因为要维护文件和目录树),但它是最符合人类的管理习惯,并且造价低,适合对性能要求没那么苛刻的场景。
- 对象存储的性能介于块存储和文件存储之间,不会维护目录结构,适合离散数据的存储且对性能要求很高的场景。比如在 AI 平台中存储图片,视频和音频等等。
