

──混沌工程的落地不仅仅是工具方法的落地也是一种文化和设计的落地
本文旨在通过基本介绍和分享声网的部分经验,帮助大家了解混沌工程,提高业务服务可靠性。
00 前言
“什么是混沌工程?听起来很牛的样子。”
“混沌工程与我们故障演练有什么区别?”
“是不是我们通过了混沌测试就不会出问题?”
“这个场景我们不太会遇到,因为客户没有这么操作的。”
上面的话是在我们推进混沌工程的工作时,大家会说到的几个普遍问题。所以在讨论混沌工程 (Chaos Engineering) 之前,我们需要知道什么是 “混沌工程”,要解决什么样的问题,如何保障服务的稳定性。
近些年来,我们软件系统的规模及复杂度一直不断的增长,传统的大单体形式已经无法适应现在的迭代及部署,所以现在的软件系统更加倾向于发展分布式的系统。分布式系统解决了我们单体架构时期迭代速度慢、技术债高、部署麻烦等问题,但同时也带来了新的挑战。根据 Google 2021 的 Devops 调研报告 [1],我们可以看到越来越多的团队进行了上云的实践,而且也愈发注重软件交付运营的体验(software delivery and operational performance)。如何在分布式系统的快速迭代下,保障系统的稳定高可用,已经是近年来的热点与难点。
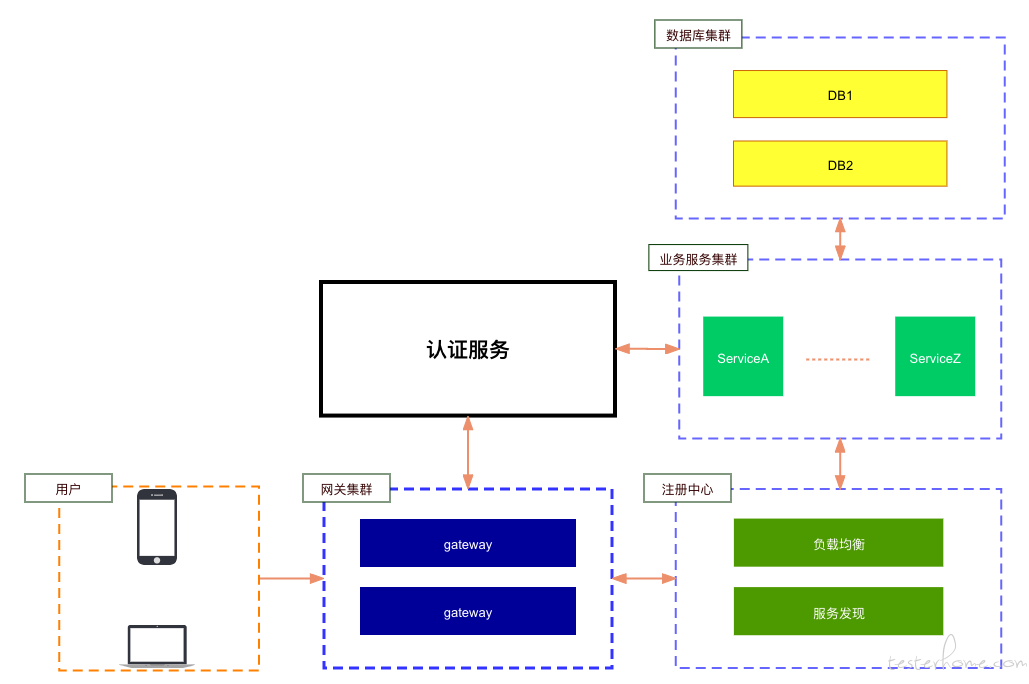
如上图,我们可以看到一个典型的微服务系统,一个具有服务边界、松耦合的服务结构。传统的测试方法确实可以在一定程度上确保服务间的可用性。例如契约测试可以尽早发现更多的问题,在频繁迭代的系统下保障服务间的可用性,但这本质上也是服务调用方与提供方的一致性校验,只是在业务逻辑上做了更好的测试保障。对于微服务系统的特性,例如高可用、服务依赖、分布式一致性等还是缺乏覆盖。现有的测试手段很难去识别服务间的强弱依赖,也很难去验证高可用策略的完备性,而混沌工程的出现,给了我们解决问题的思路以及方法。
01 概述
那什么是混沌工程呢?
混沌工程是在分布式系统上进行实验的学科,目的是建立对系统抵御生产环境中失控条件的能力以及信心。混沌工程不是一项测试,有着明确的输入输出、是一个实践性的学科,用来观察系统的薄弱点以进行改进。
我们为什么需要混沌工程呢?
在现实世界中,故障无处不在。我们在内部也对一部分应用服务进行了回顾与统计,发现结果与混沌工程实验室《2021 年中国混沌工程调查报告》[5] 相似,这里引用混沌工程实验室的结果:
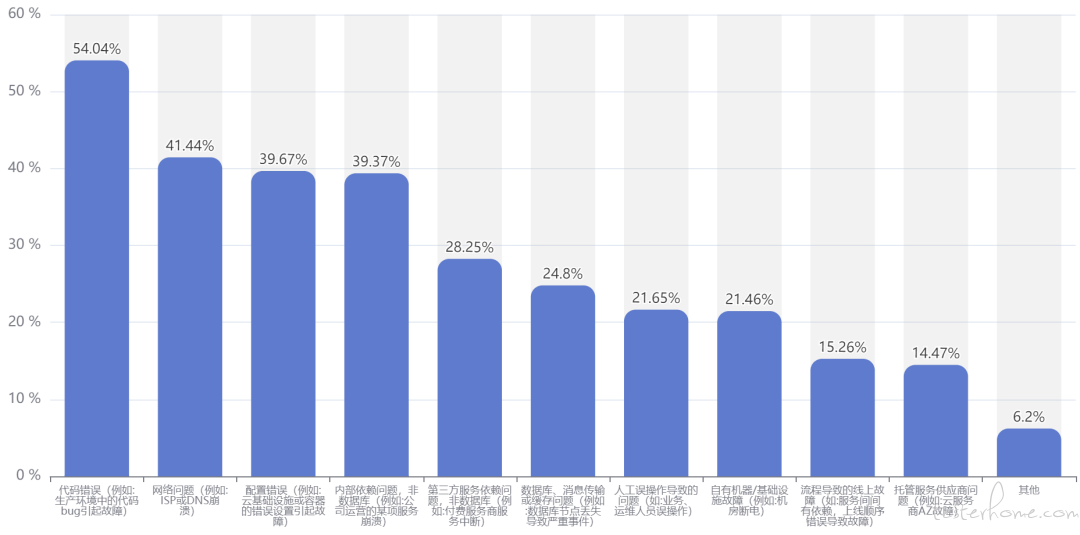
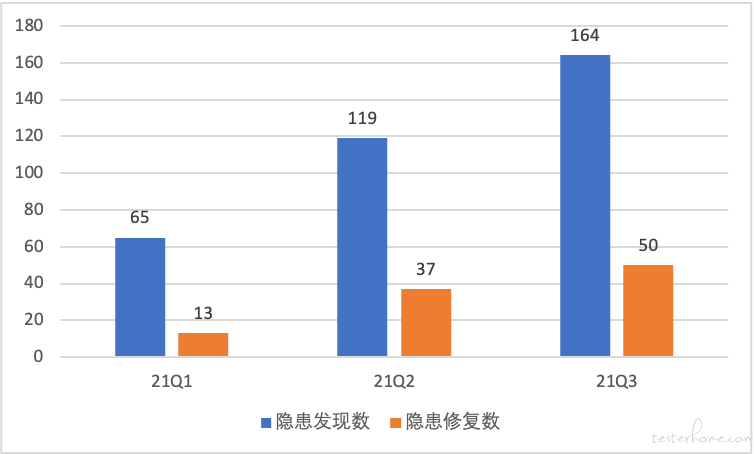
从中可以看到,变更类故障是引发重大事故的主要原因,线上机器也永远不会是 Stable 的状态。根据海恩法则,我们可以得知:每起严重事故背后,必然有 29 起轻微事故、300 起未遂征兆和 1000 个隐患。合理运用混沌工程能够很好的弱化以上问题,下图即为声网落地实践的结果。
混沌工程与我们故障演练有什么区别?
故障演练可以看做混沌工程的一种具体实践。故障演练是通过向目标系统注入真实可能发生的故障来观测系统的稳定性,但注入的场景相对是固定、已知的。混沌工程除了在其基础上提供了一些理论指导以外,还是一个发现新问题的实践过程,例如对某个区域进行服务重启等。
02 如何实施
在开始进行混沌工程之前,我们要先确定我们的系统已经有了一些高可用的特性,可以在部分异常的情况下继续正常工作。我们可以根据混沌工程原则 [2] 中的基本实践原则进行如下实验:
- 首先,用系统在正常行为下的一些可测量的输出来定义 “稳定状态”。
- 其次,假设这个稳定状态在控制组和实验组都会继续保持稳定状态。
- 然后,在实验组中引入反映真实世界事件的变量,如服务器崩溃、硬盘故障、网络连接断开等。
- 最后,通过控制组和实验组之间的状态差异来反驳稳定状态的假说。 如果混沌工程实施下来发现两者状态一致,则基本认为是可以通过此故障的;如果状态不一,那我们就找到了一个薄弱点,可以针对性地提高系统的稳定性。
这其中包含两个关键点:
- 如何产生故障
- 如何观测故障
在混沌工程实践的相关文章中,谈论最多的可能就是如何产生故障,市面上比较流行的有 ChaosBlade[3]、Chaos Mesh[4] 等工具,工具的选择是和实际业务情况密不可分的。根据 Google 的调研 [1],现在选择混沌云方案进行部署的公司也越来越多,上述的单一工具也一定无法满足所有的需求,所以如何满足自身业务需求可能会是部分团队比较头痛的问题。就声网的经验来说,自研是不可避免的,从易用性上来说也需要提供一个平台去提供全能力的支持。做比空想更重要,先实现并验证场景,然后在业务中进行实验,后续再进行优化可能是更好的一条路。
很多文章比较少提及的点就是如何观测实际故障的发生,这反而是我认为最为重要的一个点。现如今,各公司基本都会有监控报警平台,但还是有很多情况在我们的监控报警未响应时被用户所发现,即监控系统未报警但用户先报障了。这才是我们进行混沌工程最大的阻力——不能有效地发现问题。去解决此问题,在声网的实践过程中,我们总结了几个可供参考的点:
- 补足所有基础资源监控,并在实验过程观察所有基础资源是否会受影响。我们曾经就遇到过内核异常导致 slab memory 泄露的情况,这个问题就需要基础资源的监控来进行发现。
- 完善业务 SLI(Service Level Indicator) 指标。根据自身业务的特点以及客户关心的点定义 SLI 指标来进行观测,例如 Netflix 就采用 SPS(播放按钮的点击率)进行观测。指标的要求不一定是恒定,可以有着某种变化的规律,但指标一定要容易测量以及统计周期短。测量的难度越高,说明描绘业务状态的手段越少,需要进行思考及改进;统计周期越长,越有可能会略掉中间问题的点。
03 演进及评价标准
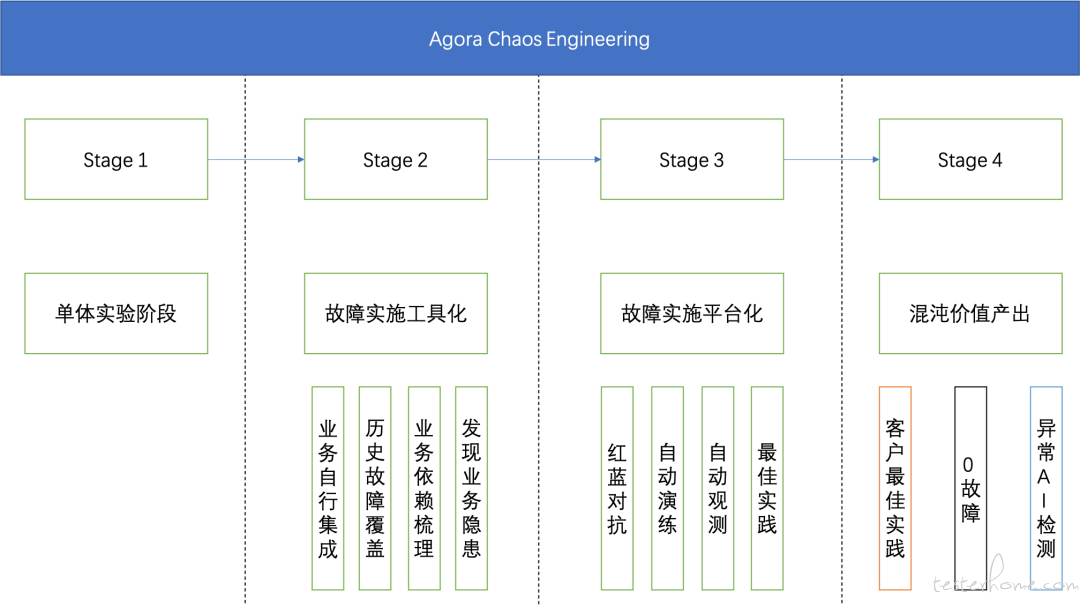
上一章节主要介绍了混沌工程的一些方法以及思路,那我们做了以后如何去评价,如何持续前进呢。从成熟度来看,我们认为落地大概会分为几个阶段:
- 单体实验阶段:本阶段主要是在单节点上进行故障的场景开发、验证以及在单节点的故障实验。
- 故障实施工具化:本阶段会针对业务进行故障实施的开发以及在业务上进行实验,并初步进行自动化、工具化及集成进 CI/CD。
- 故障实施平台化:本阶段会进行自动的故障演练,范围也逐渐从测试环境到生产环境,并且易用性大幅提升。
- 混沌价值产出:本阶段可以提供混沌工程的价值,如供客户去使用、提高客户自身服务的稳定性;使用、应用 AIOps 等手段进行一些异常的预警、监测,向着 0 故障不断前进。
上面讲了那么多,我们最终还是要为减少线上故障服务。如果不清楚做的情况,无法进行持续的改进,那就无法真正的闭环,最终不孚众望,无法真正落地。混沌工程能够帮助我们减少可用性问题,发现业务隐患,但我们很难用发现隐患的数量来衡量我们的工作,这充满不确定性。那么我们结合自身情况定义了自己的评价标准:
评价手段
• 用户场景
混沌工程的最终受益者是稳定可靠的用户体验。那在混沌工程成熟度不高的前提下(还未有信心在生产环境进行实践),在测试环境或者预发布环境中能够模拟线上场景的程度越高,我们也越有信心保障上线的可用性。另一方面,用户使用场景是可以被感知的,我们可以通过覆盖更多的用户使用场景,更好的发现问题,增强业务信心。所以我们通过对测试场景占线上用户使用场景的比例来评估覆盖度,越高越好。
• 混沌场景
一指标的选择是较为通用的,对于混沌工程,我们一定会设计对比实验,如何设计是有章法可循的。所以混沌工程的场景可以通过业界的通用故障,业务特性隐患以及业务历史故障来整体预估。我们支持的场景越多,业务也越有信心。
• 服务指标
服务指标的来源可以是 SLO(Service Level Object)、SLI,在 Agora 我们也选用 XLA(eXperience Level Agreement)。混沌工程需要与业务共同建设业务的指标,这一指标也是线上运维 & 混沌工程需要观测的指标。指标越完善,我们在对业务进行测试时,也有了更加好评判的标准,也更有信心。
04 总结
从声网的建立初始就有了对可用性的投入,到现在已经成为了内部的标准与体系(见下图)。
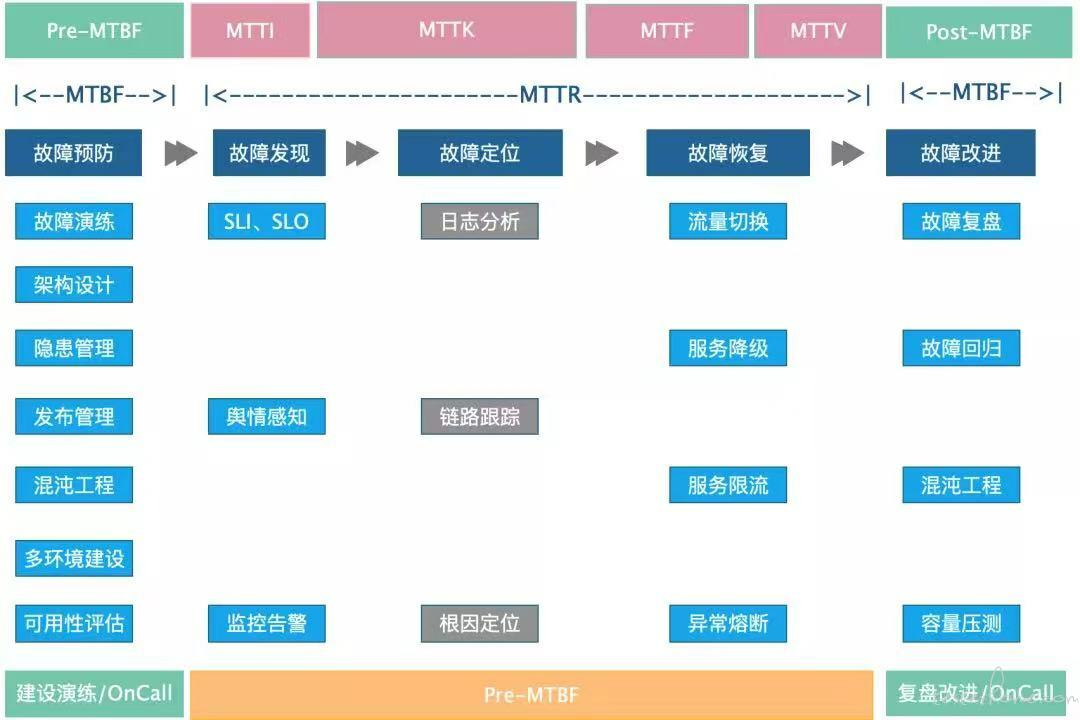
混沌工程不是万能药,是要结合公司的实际来进行设计和落地,对于可用性的投入也不仅仅是测试或者运维团队,更应该是从流程上、从设计上都进行考虑,所以混沌工程的落地不仅仅是工具方法的落地,也是一种文化、设计的落地。
05 引用
[1] Accelerate State of DevOps 2021
https://services.google.com/fh/files/misc/state-of-devops-2021.pdf
[2] PRINCIPLES OF CHAOS ENGINEERING
https://principlesofchaos.org/
[3] ChaosBlade
https://github.com/chaosblade-io/chaosblade
[4] Chaos Mesh
https://github.com/chaos-mesh/chaos-mesh
[5] 混沌工程实验室: 中国混沌工程调查报告 (2021 年)
http://www.caict.ac.cn/kxyj/qwfb/ztbg/202111/P020211115608682270800.pdf
Dev for Dev 专栏介绍
Dev for Dev(Developer for Developer)是声网 Agora 与 RTC 开发者社区共同发起的开发者互动创新实践活动。透过工程师视角的技术分享、交流碰撞、项目共建等多种形式,汇聚开发者的力量,挖掘和传递最具价值的技术内容和项目,全面释放技术的创造力。