新手
-
[上海] Teambition 招聘 中高级测试工程师 1 名 [15-30k] at 2019年07月24日
-
python 怎么获取页面所有酒店的名字 at 2019年03月14日
可以呀
-
python 怎么获取页面所有酒店的名字 at 2019年03月13日
import json import requests regions = ['Asia','Europe','MEA','New+Zealand','United+States'] hotels = [] for region in regions: url = "https://www.millenniumhotels.com/api/search/destinations?keywords=®ionName=%s" % region get_response = requests.get(url) if get_response.status_code == 200: # print(get_response.text) result = json.loads(get_response.text) hotelMsgs = result.get('data').get('hotels') for hotelMsg in hotelMsgs: hotels.append(hotelMsg.get('name')) [print(hotel) for hotel in hotels] -
有什么比较值得推荐的 python 书籍吗? at 2019年03月12日
《python 学习手册》《Python cookbook》
-
面试京东金融被问到的题目,希望大家求解。 at 2019年03月01日
是的,你可以对文件格式进行限制
def getfile(path): paths = [] for root, dirs, files in os.walk(path): for file in files: if os.path.splitext(file)[1] == '.jpg': paths.append(os.path.join(root,file)) return paths如果是复制的话,把
shutil.move()改成shutil.copy()即可 -
面试京东金融被问到的题目,希望大家求解。 at 2019年03月01日
这样写 可以不
# -*- coding: utf-8 -*- import os,shutil def movefile(srcfile,dstfile): fpath,fname=os.path.split(srcfile) if os.path.isfile(os.path.join(dstfile,fname)): print("%s exist!"%str(os.path.join(dstfile,fname))) elif not os.path.isfile(srcfile): print("%s not exist!")%(srcfile) else: fpath,fname=os.path.split(dstfile) if not os.path.exists(fpath): os.makedirs(fpath) shutil.move(srcfile,dstfile) def getfile(path): paths = [] for root, dirs, files in os.walk(path): for file in files: paths.append(os.path.join(root,file)) return paths def main(): path = "/path/A" pathto = "/path/B" paths = getfile(path) for pathfrom in paths: print(pathfrom) movefile(pathfrom,pathto) if __name__ == '__main__': main() -
面试题:从长度为 1 万的有序且有重复数字的列表找出第一个 0 前面的一位数字和最后一个 0 后面的一个数字,例如 [...,-1,0,0,0,6,...] 打印-1 和 6,谢谢。 at 2019年01月17日
做两次二分查找
def binarySearch(testList): if testList[0] >0 or testList[-1] < 0 or len(testList)< 3: print "error" midFlag1 = len(testList)/2 midFlag2 = len(testList)/2 reArray = [] while(1): if testList[midFlag1] == 0 and testList[midFlag1 - 1] < 0: print "item before first 0 is : %s" % testList[midFlag1 - 1] reArray.append(testList[midFlag1 - 1]) break if testList[midFlag1] >= 0 and midFlag1 > 0: print(testList[midFlag1],midFlag1) midFlag1 = midFlag1 / 2 if testList[midFlag1] < 0 and midFlag1 <len(testList) : print(testList[midFlag1],midFlag1) midFlag1 = (len(testList) -midFlag1)/2 + midFlag1 while(1): if testList[midFlag2] == 0 and testList[midFlag2 + 1] > 0: print "item After last 0 is : %s" % testList[midFlag2 + 1] reArray.append(testList[midFlag2 + 1]) break if testList[midFlag2] > 0 and midFlag2 > 0: print(testList[midFlag2],midFlag2) midFlag2 = midFlag2 / 2 if testList[midFlag2] <= 0 and midFlag2 <len(testList) : print(testList[midFlag2],midFlag2) midFlag2 = (len(testList) -midFlag2)/2 + midFlag2 return reArray def main(): testList = [-4,-2,-1,0,0,0,0,0,3,4,5] # testList = [-1,0,1] Result = binarySearch(testList) if __name__ == '__main__': main() -
大家平时工作中用到 shell 了么,一般都用来做哪儿些呢~ at 2018年12月29日
#!/bin/sh
while true
do
time=$(date "+%Y-%m-%d %H:%M:%S")
echo "${time}" >> cpu_mem.txt
top -b -n 1 |grep -E "CPU:|Mem:" >> cpu_mem.txt
sleep 1
done用来监控 cpu memory
-
请教个问题:python 中我想取出这个字符串的部分字:大家都在搜 “我的世界”,我想把我的世界取出来 at 2018年12月07日
str = '大家都在搜 “我的世界”'
print str
大家都在搜 “我的世界”
import re
re = re.compile(r'.“(.)”')
find = re.findall(str)
print find[0]
我的世界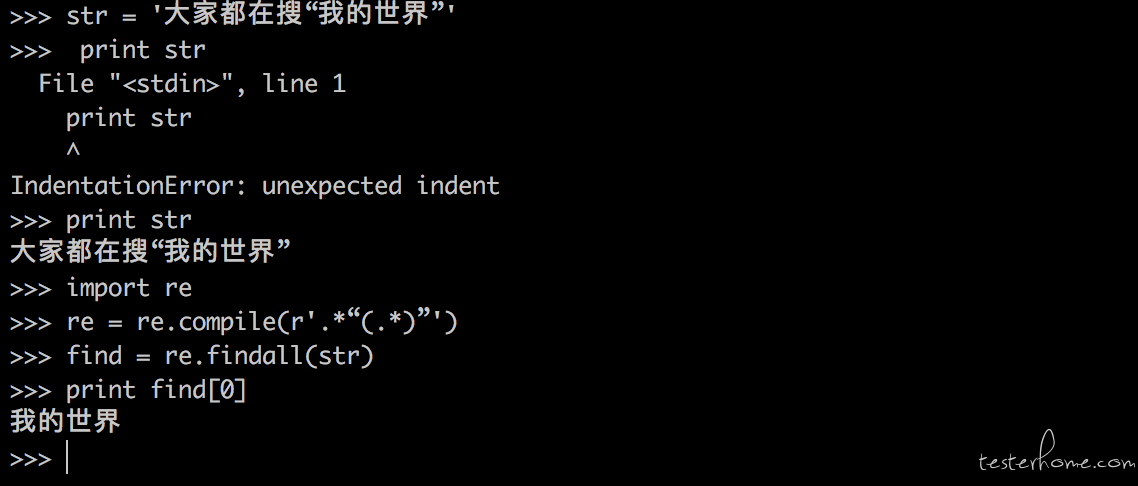
-
统计字符串里的字母个数怎么测试? at 2018年11月27日
应该是要正则\w* 排除空,特殊字符,数字这些,再用 len