Python 请教个问题:python 中我想取出这个字符串的部分字:大家都在搜 “我的世界”,我想把我的世界取出来
需求:
python 中我想取出这个字符串的部分字:大家都在搜 “我的世界”,我想把我的世界取出来
看了下正则表达,没写出来,感谢
str = '大家都在搜 “我的世界”'
pring str[6:9]
?
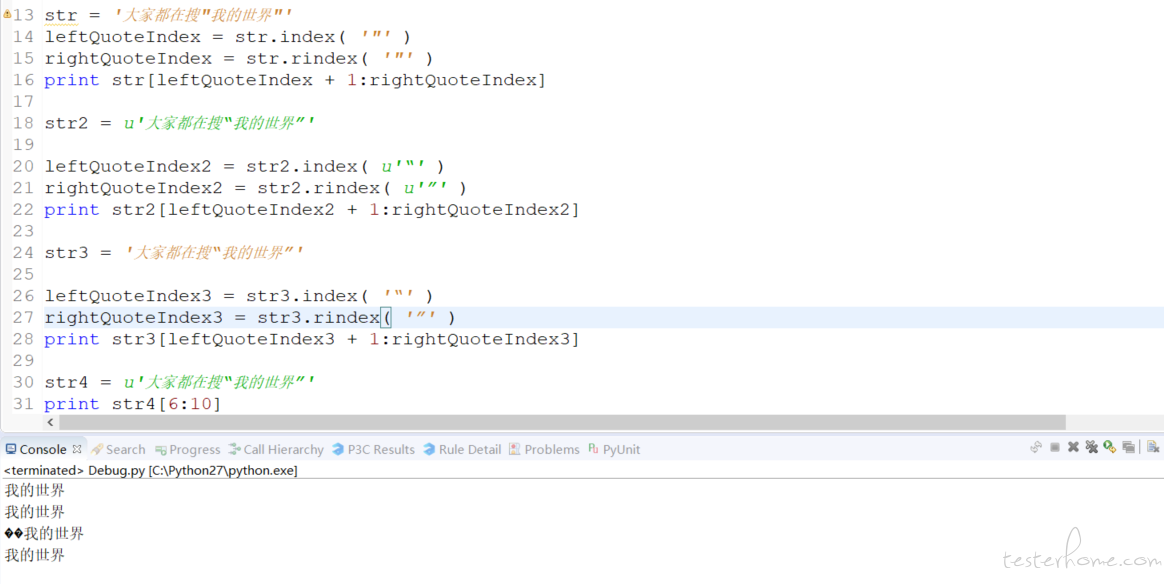
str = '大家都在搜"我的世界"'
leftQuoteIndex = str.index( '"' )
rightQuoteIndex = str.rindex( '"' )
print str[leftQuoteIndex + 1:rightQuoteIndex]
str2 = u'大家都在搜“我的世界”'
leftQuoteIndex2 = str2.index( u'“' )
rightQuoteIndex2 = str2.rindex( u'”' )
print str2[leftQuoteIndex2 + 1:rightQuoteIndex2]
str3 = '大家都在搜“我的世界”'
leftQuoteIndex3 = str3.index( '“' )
rightQuoteIndex3 = str3.rindex( '”' )
print str3[leftQuoteIndex3 + 1:rightQuoteIndex3]
str4 = u'大家都在搜“我的世界”'
print str4[6:10]
里面包含中文,python2 的话注意加 u,不然结果可能不同,如 str3 不加 u 取的结果就不同的。
另外 [:] 切片操作,前索引包含,后索引不包含。
def testre():
data = '大家都在搜“我的世界”,我想把我的世界取出来'
matchObj = re.search( r'(我的世界)', data)
return matchObj.group(0)
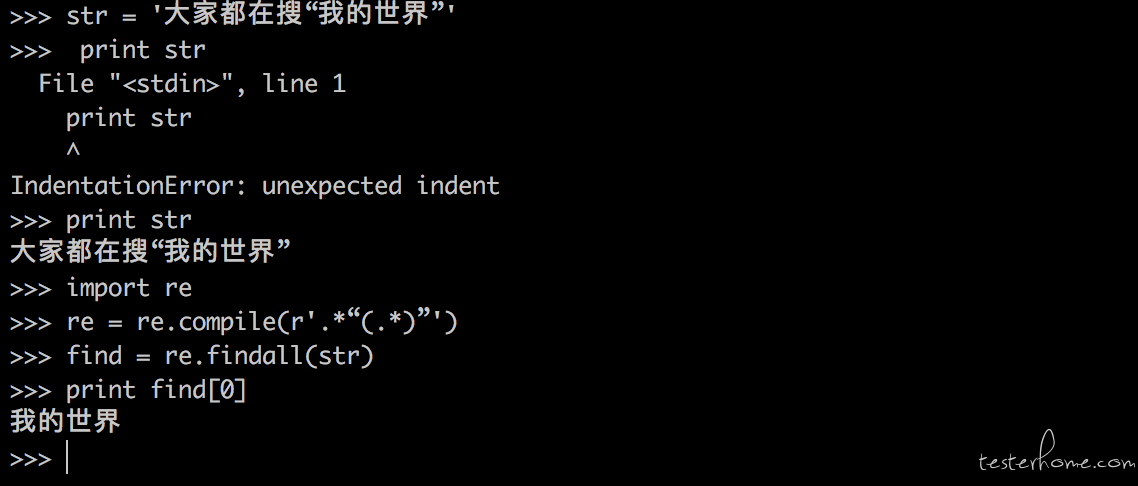
str = '大家都在搜 “我的世界”'
print str
大家都在搜 “我的世界”
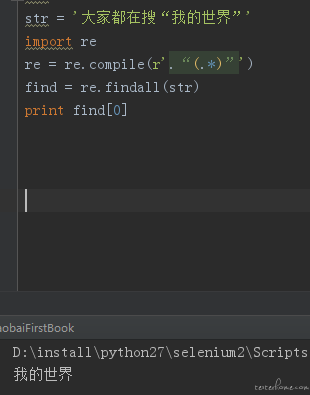
import re
re = re.compile(r'.“(.)”')
find = re.findall(str)
print find[0]
我的世界
pattern = re.compile('"(.*)"')
str = '大家都在搜 “我的世界”'
import re
re = re.compile(r'.“(.*)”')
find = re.findall(str)
print find[0]