会员
AMEAME
第 82577 位会员 / 2023-05-18
5 篇帖子 • 47 条回帖
-
88 个赞 / 37 条回复
-
22 个赞 / 10 条回复
-
11 个赞 / 6 条回复
-
1 个赞 / 6 条回复
-
AI 驱动的应用,传统测试正在失效 at 2026年01月27日
解决方案呢

-
十年 “邪修” 老测试的 2026 狂想:用 Spec Coding 重铸属于每个 QA 自己的测试神器(开篇) at 2026年01月16日
sdd 确实可能是未来 AI 深度嵌入开发流程的一个范式。
-
周日直播录屏:使用 AI(cursor)生成自动化测试用例实践分享 at 2025年12月26日
cursor 中用 playwrightMcp 可以做到启动浏览器做 UI 自动化的

-
大模型稳定性测评:从理念到实现的完整技术方案 at 2025年11月03日
分布统计(Distribution):各成功率区间的题目数量和占比 json { "0 次对": 5 题 (5%), "1 次对": 3 题 (3%), ... "10 次全对": 70 题 (70%) }
这个 json 的含义没看太懂,麻烦楼主解答下 -
有点好奇论坛大佬们提测后每天的产出 bug 量 at 2025年09月22日
一个月只能提 10 多个
-
2025 年软件测试工程师必备工具:Cursor 让测试效率提升 10 倍 at 2025年06月17日
Cursor 用了快两年,现在没 Cursor 已经完全不能工作了,唯一缺点是之前白嫖太多,现在每个月只能充值使用
-
有没有发现,自动化覆盖率越高反而成了一种负担? at 2025年05月30日
写的很好

-
有偿求 deepseek+ 软件测试得落地方案 at 2025年02月12日
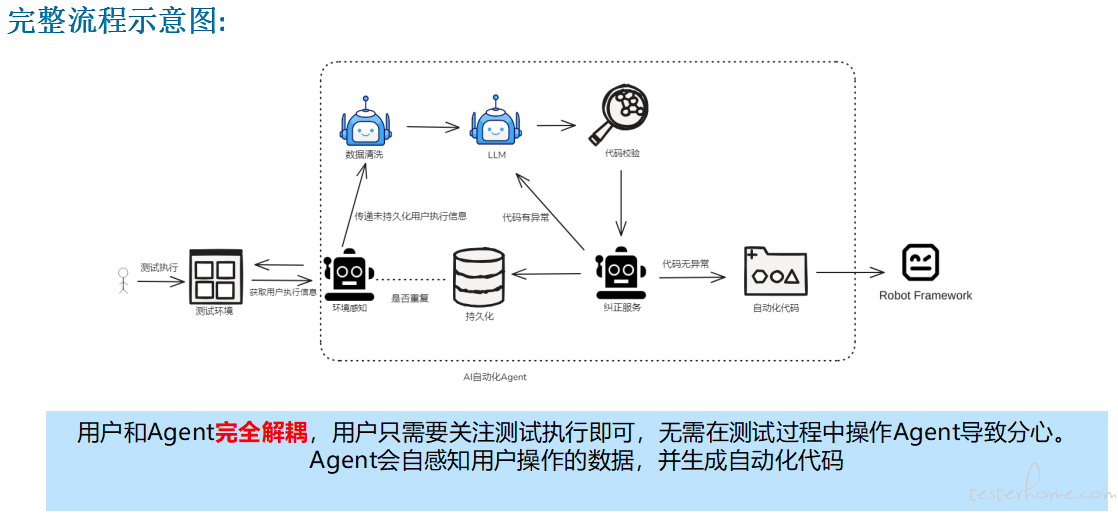
-
有偿求 deepseek+ 软件测试得落地方案 at 2025年02月12日
我们用的 BurpSuite,然后二次开发加了 url 配置,只汇总配置中的接口调用信息给 AI
-
有偿求 deepseek+ 软件测试得落地方案 at 2025年02月12日
是这个原理,目前我们用的 BurpSuite