-
接口测试的痛点 at 2023年07月21日
定时消息之类的 可以调接口调整时间,kafka 消息之类的 也可以快速消费。没有必要一直等,其实用例执行时间很短,就是前置条件耗时太久了
-
请教一下,爬虫怎么爬取知乎话题下面所有回答的图片 at 2023年05月29日
@ 陈恒捷 卧槽 时隔两年 在看到这个回答。最后一条回复已经忘记那个时候是咋解决的了。但是看代码 看到了那个 if 3 + offer > 467 branck 自己跳出循环了

-
请教一下,怎么区分图片是否可以下载呢,向下面的图片就是下载会爆 404 的错误,未找到图片 at 2021年10月15日
判断一下请求的状态码是否正常就行了,已经解决了,谢谢各位
-
请教一下,怎么区分图片是否可以下载呢,向下面的图片就是下载会爆 404 的错误,未找到图片 at 2021年10月14日
好的 谢谢
-
请教一下,怎么区分图片是否可以下载呢,向下面的图片就是下载会爆 404 的错误,未找到图片 at 2021年10月14日

-
请教一下,爬虫怎么爬取知乎话题下面所有回答的图片 at 2021年10月13日
这里找到原因了,谢谢大佬的讲解
-
请教一下,爬虫怎么爬取知乎话题下面所有回答的图片 at 2021年10月13日
好的 谢谢。我的期望是获取到所有的答案,不需要跳过已删除的回答。现在的这个逻辑已经够使用了。疑惑是上面的代码逻辑是没有跳过已删除的回答的,但是获取到的回答是全部回答减去已删除的回答的
-
请教一下,爬虫怎么爬取知乎话题下面所有回答的图片 at 2021年10月13日
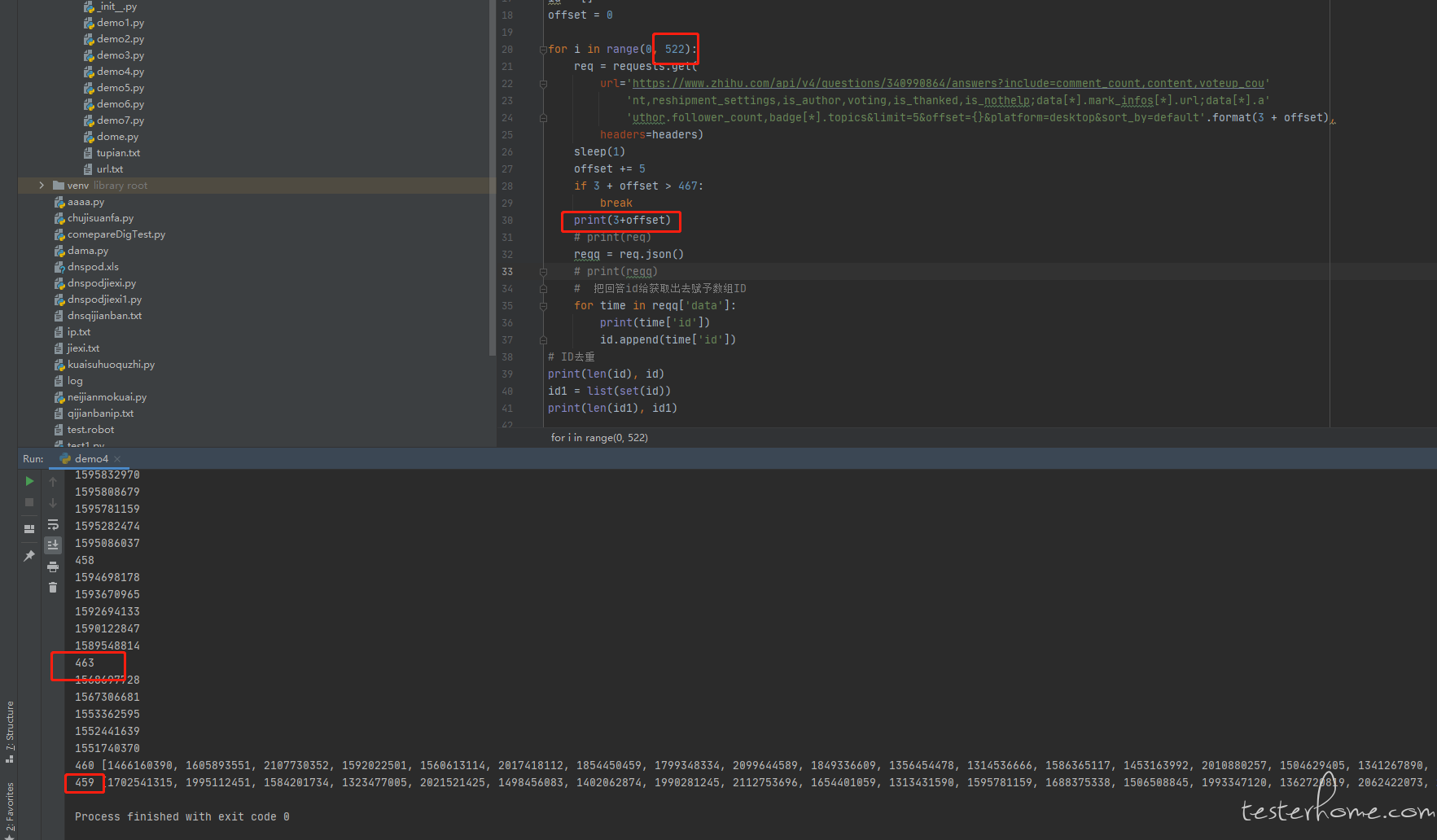
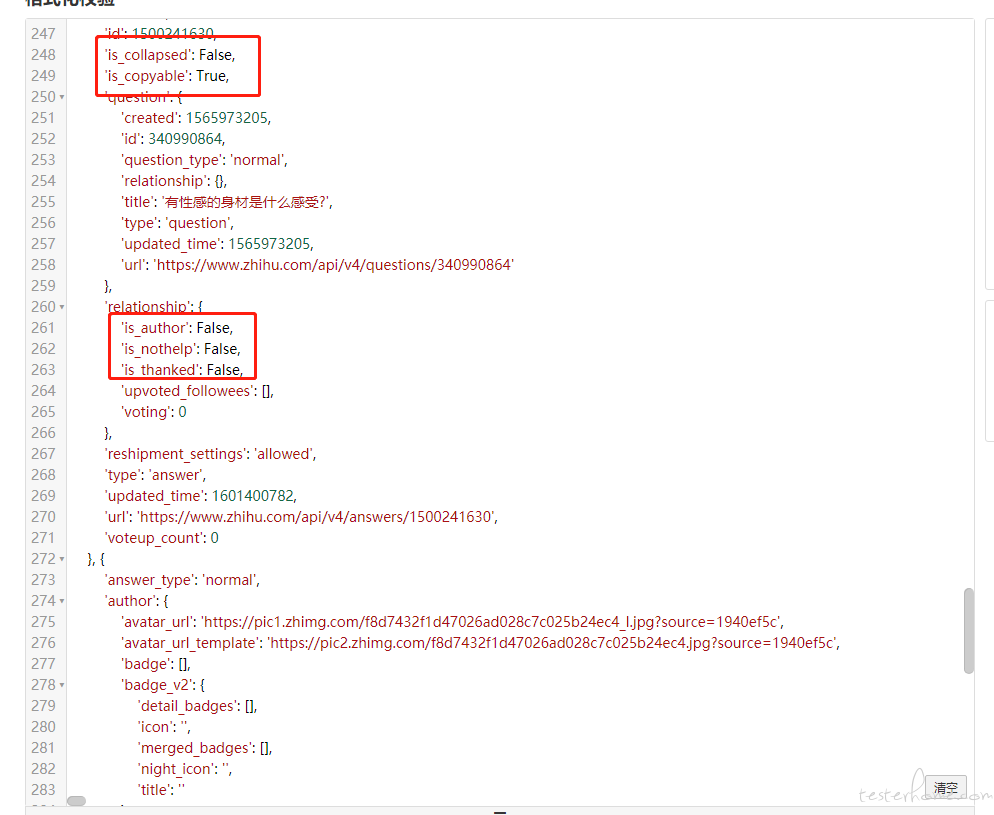
获取到的回答跟前端界面上显示的回答有差异,查看了一下是因为有些回答被删除了,所以获取不到,到了删除回答的直接就跳出循环了。这样是正常的吗? -
请教一下,爬虫怎么爬取知乎话题下面所有回答的图片 at 2021年10月12日
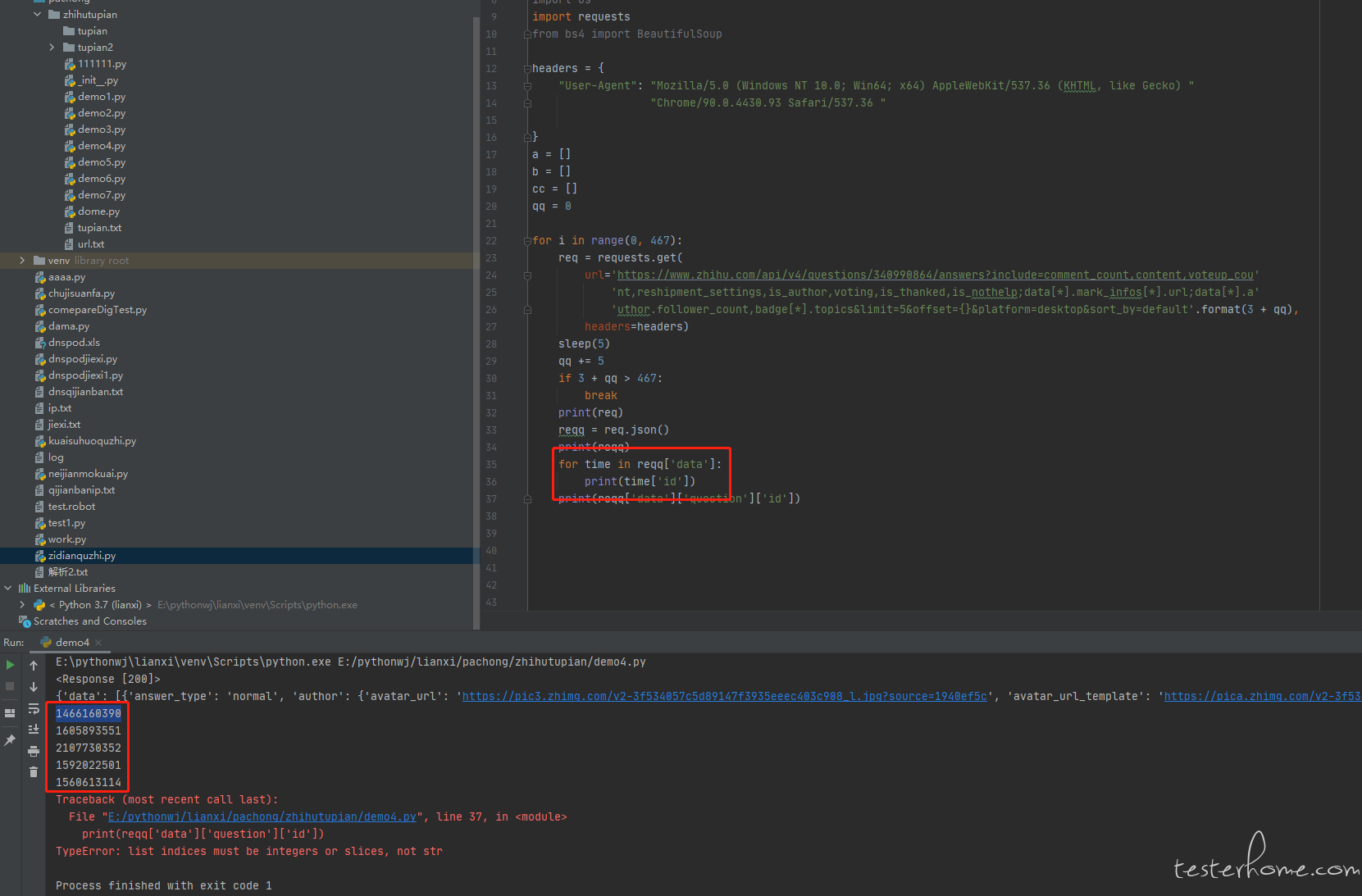
再次谢谢大佬,直接通过 json 去获取到回答的 ID,然后在通过 ID 去访问回答,在获取回答下面的图片。 -
请教一下,爬虫怎么爬取知乎话题下面所有回答的图片 at 2021年10月12日
懂了,看了一下 json 格式,正则匹配的出来的是回答里面引用的回答。还是得用 json 去匹配出来回答 ID,然后在通过 ID 去请求回答
-
请教一下,爬虫怎么爬取知乎话题下面所有回答的图片 at 2021年10月12日

正则匹配到很少回答 ID 或者没有的时候,html 返回的格式内容里面的图片很多,都是一些图片,没有回答的 ID 了 -
请教一下,爬虫怎么爬取知乎话题下面所有回答的图片 at 2021年10月12日
好的,谢谢
-
请教一下,爬虫怎么爬取知乎话题下面所有回答的图片 at 2021年10月12日
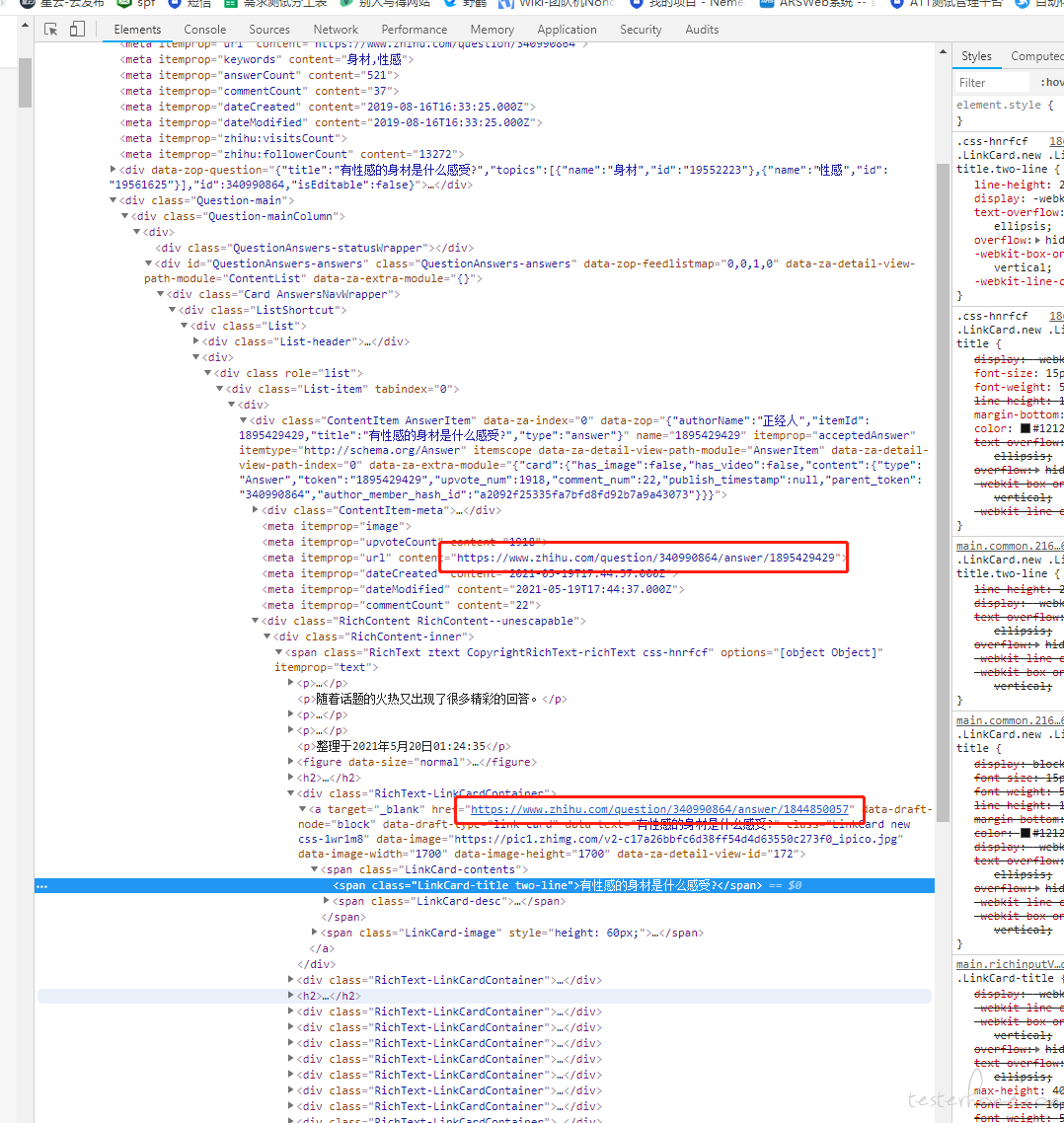
因为获取的是 html 的格式返回内容,会获取到回答的 ID,然后也会获取到这个回答下面引用的回答的 ID,然后在通关 ID 去进行访问,这样加起来只有 181 个,所以看起来就很懵 -
请教一下,爬虫怎么爬取知乎话题下面所有回答的图片 at 2021年10月12日
好的 谢谢,非常感谢您提的意见。这个正则的匹配方式是我按照前端界面的 url 去匹配的,不知道匹配到的是引用其他回答。
-
请教一下,爬虫怎么爬取知乎话题下面所有回答的图片 at 2021年10月11日
@ 陈恒捷
-
请教一下,爬虫怎么爬取知乎话题下面所有回答的图片 at 2021年10月11日
# -*- coding: utf-8 -*- from time import sleep import ahttp import urllib.request import re import socket import os import requests from bs4 import BeautifulSoup headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/90.0.4430.93 Safari/537.36 " } a = [] b = [] cc = [] qq = 0 for i in range(0, 467): req = requests.get( url='https://www.zhihu.com/api/v4/questions/340990864/answers?include=comment_count,content,voteup_cou' 'nt,reshipment_settings,is_author,voting,is_thanked,is_nothelp;data[*].mark_infos[*].url;data[*].a' 'uthor.follower_count,badge[*].topics&limit=5&offset={}&platform=desktop&sort_by=default'.format(3 + qq), headers=headers) sleep(5) qq += 5 if 3 + qq > 467: break reqq = req.text # print(reqq) # 先获取到界面上的回答,然后一个个去请求回答,在获取回答下面的图片 aaa = re.findall(r'https://www.zhihu.com/question/340990864/answer/(\d*)', reqq) print(aaa) print(3 + qq) if len(aaa) == 0: continue else: for j in range(len(aaa)): b.append(aaa[j]) print(len(b), b) bb = list(set(b)) print(len(bb), bb) bbb = [f"https://www.zhihu.com/question/340990864/answer/" + str(bb[i]) for i in range(len(bb))] print(len(bbb)) ress = ahttp.Session() res1 = [ress.get(url) for url in bbb] res2 = ahttp.run(res1) tupian = [] m = 0 for j in range(len(bb)): res3 = res2[j].text tu = re.findall(r'https://pic2.zhimg.com/v2.*?\.jpg', res3) if len(tu) == 0: continue else: for k in range(len(tu)): tupian.append(tu[k]) print(len(tupian), j) tupian2 = set(tupian) print(len(tupian2)) while m < len(list(tupian2)): print(list(tupian2)[m]) urllib.request.urlretrieve(list(tupian2)[m], filename='./tupian2/' + str(m) + '.jpg') m += 1 print(m) -
请教一下,爬虫怎么爬取知乎话题下面所有回答的图片 at 2021年10月11日
我这个是只获取一个固定话题下面的回答,回答数不会为 0 ,获取不到回答的时候我看了 html 格式返回的内容,返回的全部都是图片,没有回答
-
请教一下,爬虫怎么爬取知乎话题下面所有回答的图片 at 2021年10月11日
-- coding: utf-8 --
from time import sleep
import ahttp
import urllib.request
import re
import socket
import os
import requests
from bs4 import BeautifulSoupheaders = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/90.0.4430.93 Safari/537.36 "}
a = []
b = []
cc = []
qq = 0for i in range(0, 467):
req = requests.get(
url='https://www.zhihu.com/api/v4/questions/340990864/answers?
'include=comment_count,content,voteup_cou'
'nt,reshipment_settings,is_author,voting,is_thanked,is_nothelp;data[].mark_infos[].url;data[].a'
'uthor.follower_count,badge[].topics&limit=5&offset=
'{}&platform=desktop&sort_by=default'.format(3 + qq),
headers=headers)
sleep(5)
qq += 5
if 3 + qq > 467:
break
reqq = req.text
# print(reqq)
# 先获取到界面上的回答,然后一个个去请求回答,在获取回答下面的图片
aaa = re.findall(r'https://www.zhihu.com/question/340990864/answer/d*)(\', reqq)
print(aaa)
print(3 + qq)
if len(aaa) == 0:
continue
else:
for j in range(len(aaa)):
b.append(aaa[j])print(len(b), b)
bb = list(set(b))
print(len(bb), bb)bbb = [f"https://www.zhihu.com/question/340990864/answer/" + str(bb[i]) for i in range(len(bb))]
print(len(bbb))
ress = ahttp.Session()
res1 = [ress.get(url) for url in bbb]
res2 = ahttp.run(res1)
tupian = []
m = 0
for j in range(len(bb)):
res3 = res2[j].text
tu = re.findall(r'https://pic2.zhimg.com/v2.?\.jpg*', res3)
if len(tu) == 0:
continue
else:
for k in range(len(tu)):
tupian.append(tu[k])
print(len(tupian), j)
tupian2 = set(tupian)
print(len(tupian2))
while m < len(list(tupian2)):
print(list(tupian2)[m])
urllib.request.urlretrieve(list(tupian2)[m], filename='./tupian2/' + str(m) + '.jpg')
m += 1
print(m) -
请教一下,爬虫怎么爬取知乎话题下面所有回答的图片 at 2021年10月11日
等待时间太短了,offset 的值越大,响应的时间就越长,等待时间太短,导致有些回答直接没有获取到
-
请教一下,爬虫怎么爬取知乎话题下面所有回答的图片 at 2021年10月11日
以前是获取到 181 个回答,现在获取到 184 个回答
-
请教一下,爬虫怎么爬取知乎话题下面所有回答的图片 at 2021年10月11日
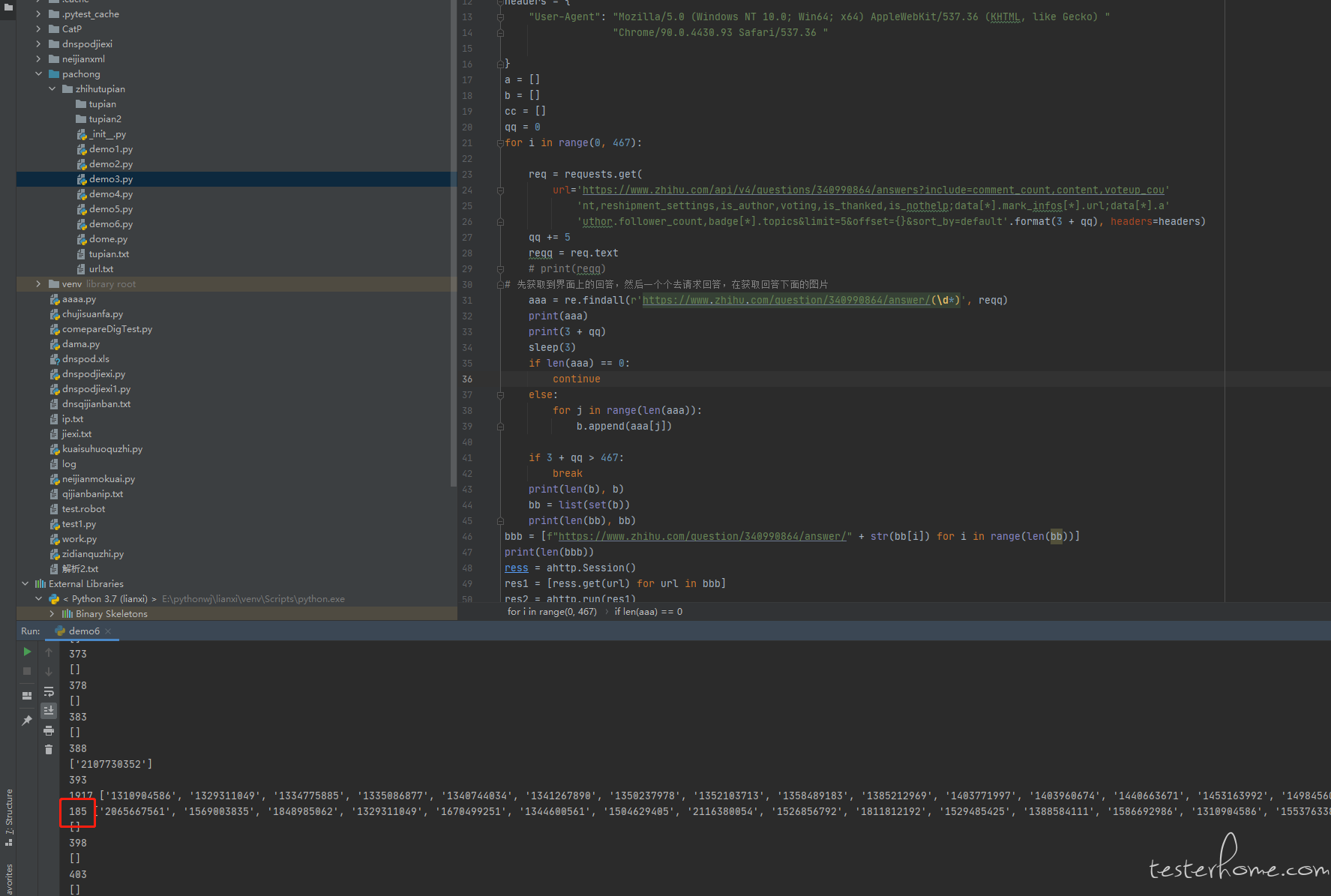
改了之后,多获取了 3 个回答 -
请教一下,爬虫怎么爬取知乎话题下面所有回答的图片 at 2021年10月11日
好的 谢谢
-
请教一下,爬虫怎么爬取知乎话题下面所有回答的图片 at 2021年10月11日
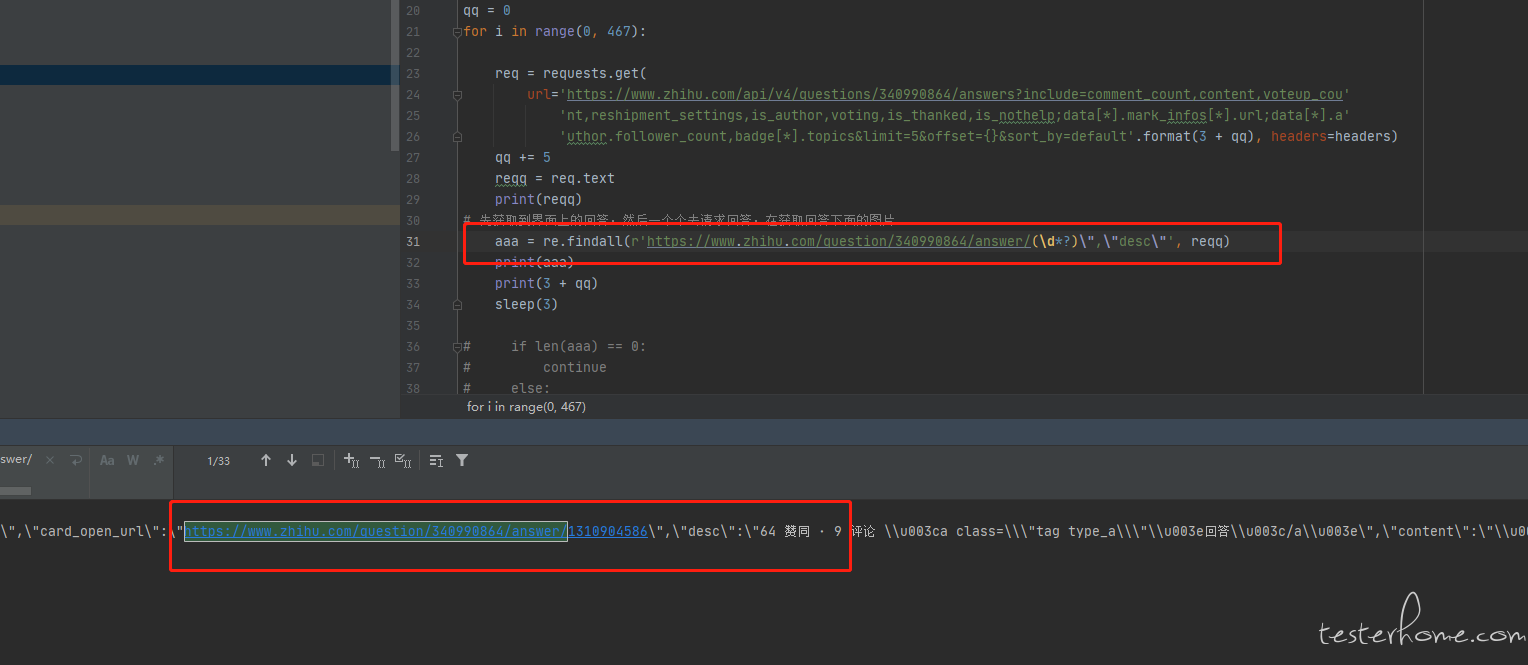
很奇怪,匹配不出来 -
请教一下,爬虫怎么爬取知乎话题下面所有回答的图片 at 2021年10月11日
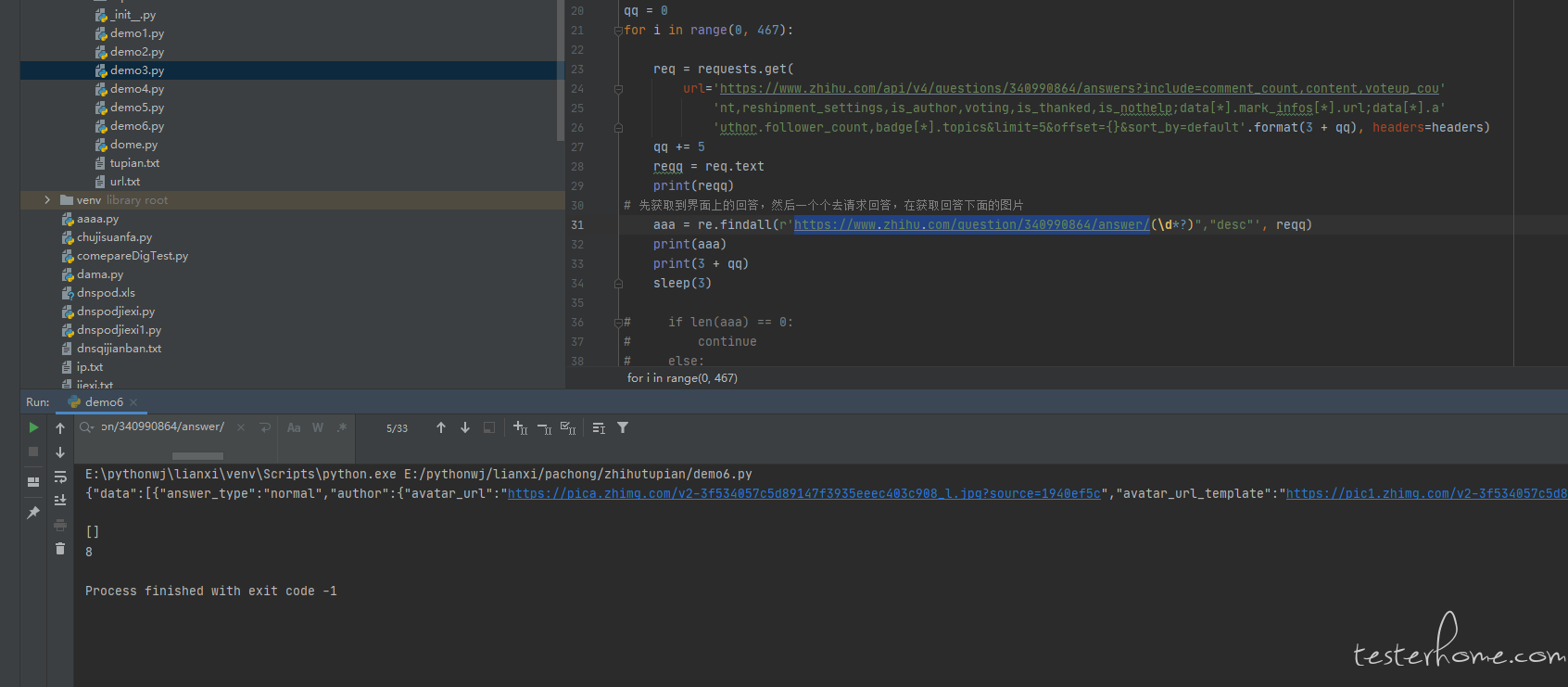
原始有值,正则没有匹配到 -
请教一下,爬虫怎么爬取知乎话题下面所有回答的图片 at 2021年10月11日
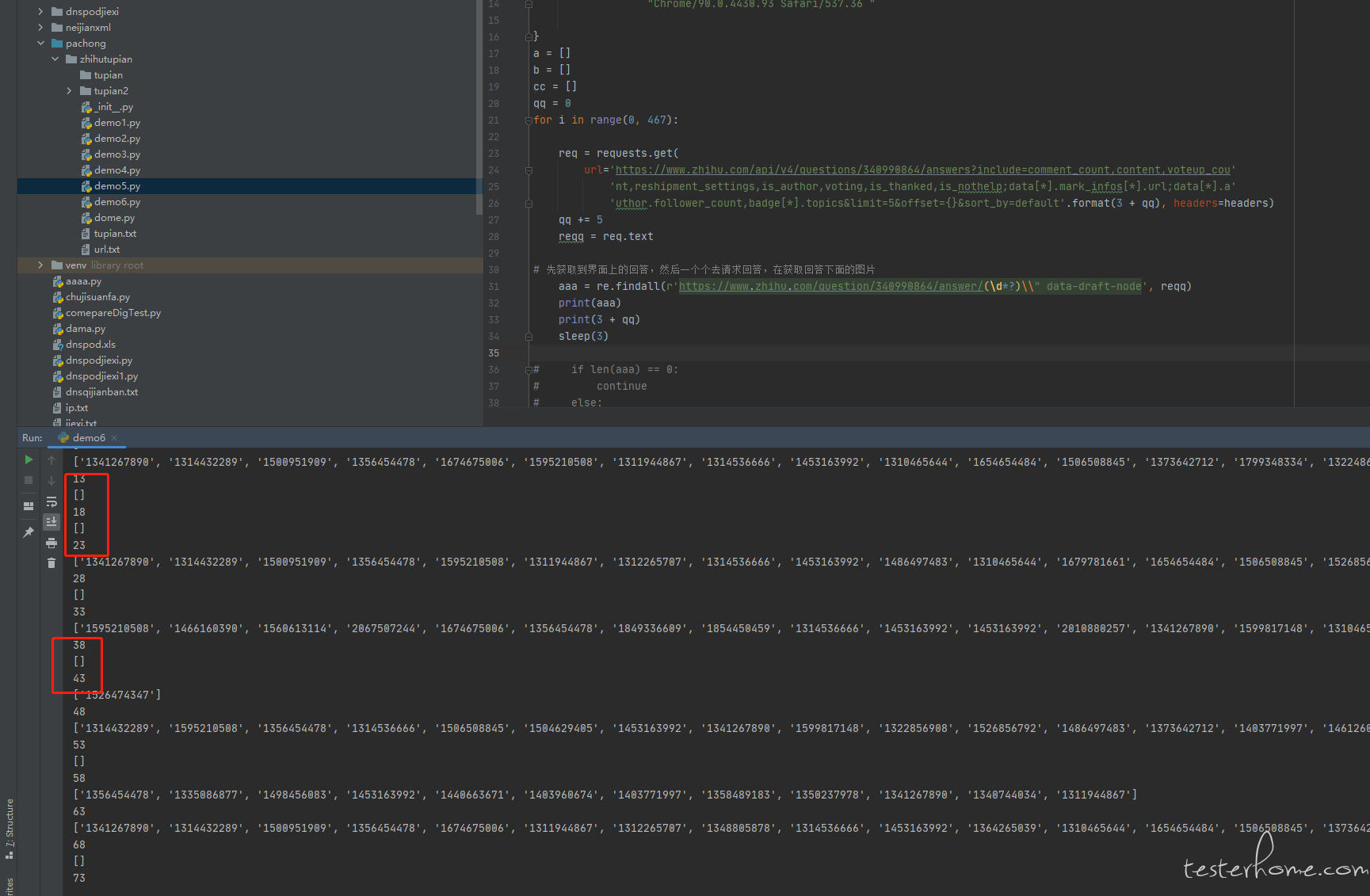
有很多请求下面没有回答,不知道是不是我正则写的有问题 ,我在去理一理我的正则,谢谢