-
基于 Jmeter 的轻量级云压测平台的原理与实现 (一):开篇 at October 26, 2018
看来你这一下提了不少的需求啊,总体的数据结果分析 + 分布式节点的拆分利用。
简单聊聊吧。
数据结果 table 展示:
当然这个我还没做,因为 Jmeter 提供的测试报告是包含这些的。
你提的应该是抛弃测试报告的时候,这些聚合数据怎么弄?
我可以给折线图增加这些数据的线啊,Jmeter 传统的聚合报告的 table 展示是有弊端的,因为对比它,折线图不仅能展示趋势,还能包含历史数据,是更优的选择。
目前我没做因为我用不到 99%Line 等,还因为没人给我提这种需求。分布式节点的拆分利用:
这个比较复杂了,其实 Jmeter 自己对这个支持的就不好啊,想一想,如果单独用 Jmeter,怎么利用多个 slave?还不是要多个 master。
我的平台想要展示不同的 slave 集群的结果,还要基于 Jmeter 的 API 之上,其实是有难度的。
这个地方我是有想法的,但是还没验证就不在这里说了。
我的原则是能不改 Jmeter 的源码就不改,因为它发展的很快,改它源码不合适。
是有想法的,嗯嗯,如果真有这方面的需求,是可以实现的。 -
基于 Jmeter 的轻量级云压测平台的原理与实现 (一):开篇 at October 26, 2018
唉,也是一种取舍吧。
想要十全十美,肯定是要费一番功夫的。
其实性能测试到底目的是什么,这个要想清楚,后续我合计介绍介绍这个。
有些人都不看测试报告的,或者说报告中有什么根本看不明白,看不出来门道。
我们测试人想的,测试报告,什么趋势图,什么统计数据,其实对某些人来说,有了就是 “哦”,没有了就是 “你这不行呀”。
我们想的周到的,费力实现的,其实除了自己,别人都体会不到。
测试人不能自己把自己玩死,还是要聚焦到能提高自身价值的地方去。 -
基于 Jmeter 的轻量级云压测平台的原理与实现 (一):开篇 at October 26, 2018
没有呀,我的平台支持不生成 css 结果文件的,然后监控数据可以直接来我的平台截图呀,这样测试报告不会过于单薄,同时还会有监控。
你这个自己的算法还是不错的,但是还会面对一个问题,就是测试报告的整合。
你自己的算法也是改的 Jmeter 源码吗还是插件生成的?还是说处理已有的 JTL 文件? -
基于 Jmeter 的轻量级云压测平台的原理与实现 (一):开篇 at October 26, 2018
还是被说出来了啊……其实这个坑我也是深有体会的。文中我也提了。

这个坑,属于 Jmeter 的缺陷,但你的多 master 的方式也有问题,主要就是测试数据的监控收集和测试报告的整合及生成。
我想的解决方式,应该还是给 Jmeter 写插件,不要实时发送数据,而是固定间隔发送数据给 master。当然目前我没心急火燎的解决这个问题,因为实际上,master-slave 的结构能产生的压力还凑合。
我这边是有数据的,master 是 1G 网卡的情况下,多 slave 能产生接近 8 万的 TPS 压力。
这个压力的数值,已经可以了。
通俗点儿说,这个压力我认为已经满足绝大多数的压力需求了。这个问题我已经想着呢,会实现。
-
基于 Jmeter 的轻量级云压测平台的原理与实现 (一):开篇 at October 26, 2018
有执行压测的启动按钮。
-
基于 Jmeter 的轻量级云压测平台的原理与实现 (一):开篇 at October 26, 2018
RPC 的接口吗?这个没尝试过。
我们平台是 Jmeter 内核的,如果 Jmeter 可以测,那平台就可以。 -
基于 Jmeter 的轻量级云压测平台的原理与实现 (一):开篇 at October 26, 2018
研究一下 Jmeter 的断言,能对响应码是 502 504 500 标记为错误或者成功。
-
基于 Jmeter 的轻量级云压测平台的原理与实现 (一):开篇 at October 26, 2018
感谢使用。
第三方的 jar 包要写到 pom 文件里,相当于平台加载的三方 jar 包,然后重启平台使用。
这方面目前没有什么好办法。 -
基于 Jmeter 的轻量级云压测平台的原理与实现 (一):开篇 at October 25, 2018
你这个问题 github 上也提了是吧,我在那里回答你。
-
记一次面试问题——Python 垃圾回收机制 at October 23, 2018
面试题很不错。
-
《全链路压测平台 (Quake) 在美团中的实践》读后有感 at October 22, 2018
性能测试工作有一个经验,就是一般不是未雨绸缪,而是实在不行了经常出性能问题了需要性能测试。
这样往往会出现一个结果,要搞性能测试,并且必须最快速度搞起来。
同时,由于性能问题排查比较复杂,性能测试工作会非常多非常频繁,加班也是很强烈的。
然后,一方有了成功经验,其他部门/项目也会要求搞性能测试,需求更猛烈的来了。说到这里,开发同学的效率和速度就是特别大的优势了,能加班,可以快速的让产品成型。
同时,也变相说明了,其实开发和性能测试,测试开发的技能栈知识树是很重叠的。
-
基于 Jmeter 的轻量级云压测平台的原理与实现 (一):开篇 at October 22, 2018
我就是 win10 啊。
mac 成功了,win10 不成功,那先检查配置呗……主要是 Jmeter_home 的路径,目录下是这样的:
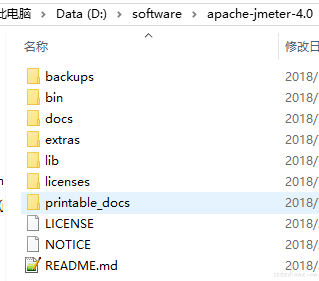
-
基于 Jmeter 的轻量级云压测平台的原理与实现 (一):开篇 at October 22, 2018
嗯嗯 , 需要配置一下 Jmeter_home 在数据库中配置。
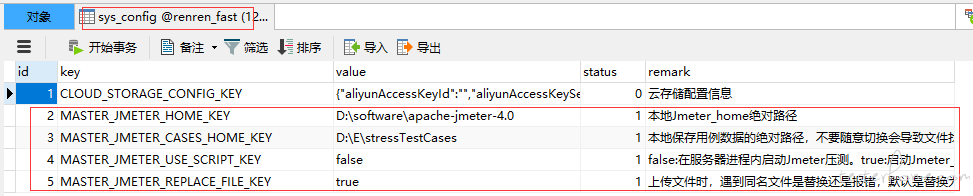
-
基于 Jmeter 的轻量级云压测平台的原理与实现 (一):开篇 at October 22, 2018
pom.xml 打 war 包使用 pom-war.xml
-
offer 比较:百度测开 OR 猿辅导开发 at October 17, 2018
-
offer 比较:百度测开 OR 猿辅导开发 at October 16, 2018
百度吧,不用想。
你这个级别的开发去了也是增删改查,没区别,创业公司有都是业务代码让你写,写到麻木。 -
基于 Jmeter 的轻量级云压测平台的原理与实现 (一):开篇 at October 10, 2018
我以为没人看呢……
-
Locust 源码阅读及特点思考 (二) at September 17, 2018
1.主要是 python 语言和 Java 语言(解释型和编译型)自身的性能差距吧。还有一些其它的优化原因,主要有 JVM 的垃圾回收算法比 python 的先进,JVM 的 JIT 即时编译。
2.还有关于你的测试数据,10 个线程这种体量的并发,太弱了,你可以试试单线程搞 10000 次,可能都比 10 个线程的好。我们讲压力测试都是几百几千甚至集群的上万的线程这种压力。
3.还有真正的压测,脚本逻辑都是比较复杂的,比如创造数据,数据关联等等,逻辑和处理都会比较复杂,这时候 python 语言和 Java 语言的自身性能差异就会更明显了。换句话说,你的测试数据,对于真正的压测场景,代表性还有待商榷。
4.关于协程和线程这个还不好说的,协程相当于把用户端来处理多线程(一个线程达到多线程切换的效果),多线程是操作系统来处理多线程(用户端程序不管这个事情直接调用操作系统的接口来实现多线程)。Java 没有协程是有原因的,因为用户端来处理多任务的切换逻辑,毕竟是在操作系统上层搞的事情,一是需要对操作系统 CPU 命令等非常了解,二是要适配多种环境多种操作系统多种 CPU,成本是很高的。Java 是讲究跨平台和高性能(接近于 C 的性能)的,协程 Java 觉得不行。总之,就是不要太迷恋协程的性能,python 不存在多线程的,它是只能用协程。建议还是具体问题具体环境具体分析。python 语言的优势在书写和语法糖,不在性能。
5.说了这么多,其实压力端对性能的要求很高的,一般语言不能胜任。如果你有兴趣,可以搞搞 GO 语言的压力端,GO 语言是支持协程的。locust 的作者自己都说高压力的压测要求 locust 不支持,咱们就别纠结这个了。 -
求一款轻量级的性能监控工具 at September 11, 2018
很赞!
-
压力测试遇上了一个奇怪的问题,请有经验的兄弟们帮忙看下。 at August 30, 2018
查了一下 Jmeter4 的源码,其中的停止也是 TimeUnit.MILLISECONDS.sleep(pause); 本质也是 Thread.sleep()。
-
压力测试遇上了一个奇怪的问题,请有经验的兄弟们帮忙看下。 at August 30, 2018
简单看了描述,我这里总结及猜测一下,应该 8 9 不离十。
楼主觉得奇怪的地方:
为什么相同的接口实现,仅仅是加了 200ms 的延时,为什么总 TPS 就涨不上去了?
为此,你先搞压力端,排除了压力端的原因。
你接着分析服务器端,发现 CPU,内存,网络啥问题也没有,“基本排除” 了服务器端的问题。
表示奇怪。
你还在搞 Jmeter,打算换一种工具。可惜结果不会有变化。其实不奇怪。
你 200ms 的延迟是加在了 Java 实现里,使用的是 new Thread().sleep(200), 此方法及其耗费 Java 线程资源。因为你是 spring boot 的自带启动,本身的线程总数就不多,还用了这么消耗线程资源的方式来实现延时,服务器性能会大大降低。
如果你能监控到 JVM 进程中的线程状态,会发现都是 block 或者 wait。
说白了,服务器性能不行,不是因为硬件资源不行,而是被你的代码强制的暂停住了。解决方式:
- 200ms 的延迟放到压力端去实现,不要放在服务器端。
- 如果还是要压力端实现,把 spring boot 给换了,换成 tomcat 等其他,但记得调优 tomcat 等其他。
-
基于 Jmeter 的轻量级云压测平台的原理与实现 (一):开篇 at August 29, 2018
多谢肯定。
实时监控的开源产品太多了,最近我还发现了一个 :https://github.com/AsuraTeam/monitor
这方面要考虑的太多,自己实现很难专业。
另外提到的 报表分析 ,如果做出来确实很牛,就像 听云 ,但是到这步就很难开源了, 是可以赚钱的了。 -
mysql 亿级数据优化 at August 28, 2018
还有,你这么牛,你去文章中找其他问题去,别这里有个人回复了,你就来喷来找茬,你搞点儿新鲜的。
我的回复不是给你划重点让你深刻思考的。
你这样的还没有实锤的,纯蹭热度。 -
mysql 亿级数据优化 at August 28, 2018
1.真不知道你在这强调什么,还是就没看懂问题。
https://www.zhihu.com/question/36996520
https://tech.meituan.com/mysql_index.html


“顺序是有影响的”,把实锤放出来。最左前缀匹配原则是有 mysql 的内部实现算法支撑的,你的 “顺序是有影响的”,依据是什么?
-
mysql 亿级数据优化 at August 28, 2018
- “并且应尽可能的让字段顺序与索引顺序相一致。”,这个是不必要的,mysql 会自动排序。
- 存储过程,游标,触发器,都是不推荐的,可以忽略。
- in 是走索引的。
- “一切的 > < != 等等之类的写法都会导致全表扫描” 大于号小于号应该是可以走索引的。
建议先查一下 explain。
另外,去搜索一下 otter,类似的技术你这里没提。
你引用的技术帖子已经很老了,觉得能落后 5 年,建议多看看。