自动化工具 Python 调 Jmeter 执行 自定义多场景多个 jmx 测试计划,达成半步无人值守 (一)
本渣使用 python 已久,一直响应 “Life is short, use Python”(人生苦短,我用 python)这句话号召。用着久了,真会变 “懒 “,但凡是手工处理的任务,都想使用 python 脚本替代。况且,我理想中的性能测试是可以无人值守的进行下去。虽然 Jmeter 可以设置简单的调度作业,但好像是无法参数化线程数
同时,我也烦透了 jmeter 输入如下鬼命令:
Jmeter -n -t {tmpjmxfile} -l {csvfilename} -e -o {htmlreportpath}
尤其是{htmlreportpath}这个文件夹路径,没有这个文件夹又不会自动创建,有的话又必须为空。经常要给文件夹、文件命名,而且命名又没什么规范,乱七八糟的。
于是想着,即便是用 python 帮我创建文件夹,帮我生成命令,也是好的。
精益求精,做着做着,就会想着,干脆把命令也给执行了,于是就有这样的产出。
使用场景:
1.需要不断的运行性能测试脚本,摸底,取数。 如线程数、循环次数。
2.需要等待较长时间的

执行此脚本的条件是,在一个目录下,只能有一个 jmx 后缀文件。当然可以有参数化文件,拷贝 execjmeter.py 和 runafter.py 文件到该目录下。简单例子如下:
话不多说,直接来段代码,代码仍需不断改进:
python 版本=3.6.1,这段代码命名为 execjmeter.py
#coding=utf-8
import os
from os.path import join
import re
import subprocess
import time
from string import Template
currpath = os.path.dirname(os.path.realpath(__file__))
JMETER_Home = r'''"D:\Program Files\apache-jmeter\bin\jmeter.bat"'''
origin_jmxfile = replaced_jmxfile = ''
def before_check():
global origin_jmxfile
count_jmxfile = 0
for root, dirs, files in os.walk(currpath):
for name in files:
if '-P.jmx' in name:
os.remove(join(root, name))
if '-P.jmx' not in name and '.jmx' in name and 'XL' not in name:
count_jmxfile = count_jmxfile + 1
origin_jmxfile = join(root, name)
if count_jmxfile != 1 and origin_jmxfile:
print('为了更智能地执行jmx文件,请确保有且仅有一个有效的jmx文件!')
return False
else:
return True
def create_para_jmxfile():
global origin_jmxfile, replaced_jmxfile
jmx_str = ''
with open(origin_jmxfile, "r", encoding="utf-8") as file:
jmx_str = file.read()
patten = '<stringProp name="LoopController.loops">(.*?)</stringProp>'
replace_str = '<stringProp name="LoopController.loops">$loops</stringProp>'
jmx_str = re.sub(patten, replace_str, jmx_str)
patten = '<stringProp name="ThreadGroup.num_threads">(.*?)</stringProp>'
replace_str = '<stringProp name="ThreadGroup.num_threads">$num_threads</stringProp>'
jmx_str = re.sub(patten, replace_str, jmx_str)
replaced_jmxfile = origin_jmxfile.replace('.jmx', '-P.jmx')
with open(replaced_jmxfile, "w+", encoding="utf-8") as file:
file.writelines(jmx_str)
def getDateTime():
'''
获取当前日期时间,格式'20150708085159'
'''
return time.strftime(r'%Y%m%d%H%M%S', time.localtime(time.time()))
def execcmd(command):
print(f"command={command}")
output = subprocess.Popen(
command,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
shell=True,
universal_newlines=True)
stderrinfo, stdoutinfo = output.communicate()
print(f"stderrinfo={stderrinfo}")
print(f"stdoutinfo={stdoutinfo}")
print(f"returncode={output.returncode}")
def execjmxs(Num_Threads, Loops):
tmpstr = ''
with open(replaced_jmxfile, "r", encoding="utf-8") as file:
tmpstr = Template(file.read()).safe_substitute(
num_threads=Num_Threads, loops=Loops)
now = getDateTime()
tmpjmxfile = currpath + f'\{now}-T{Num_Threads}XL{Loops}.jmx'
with open(tmpjmxfile, "w+", encoding="utf-8") as file: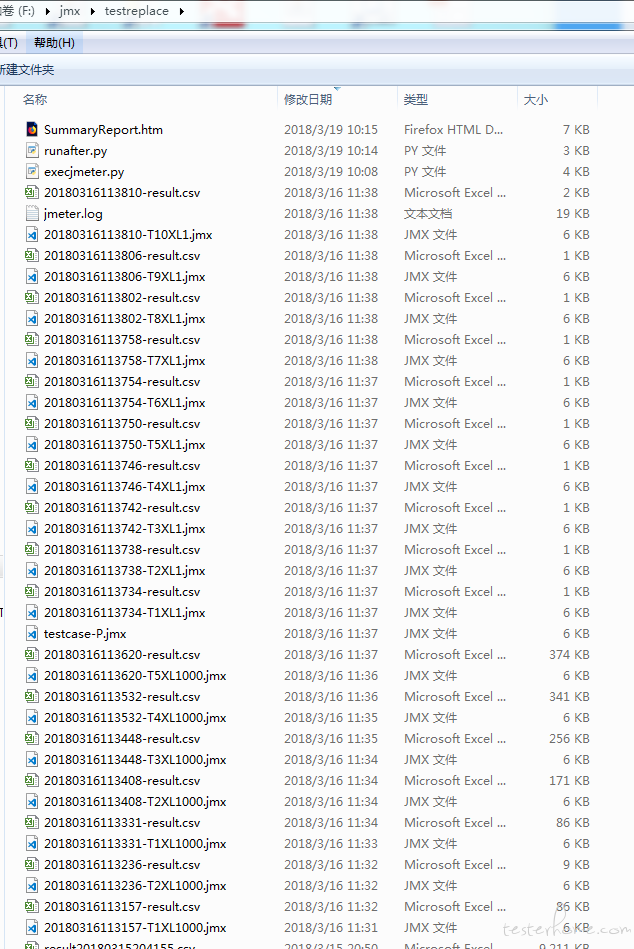
file.writelines(tmpstr)
csvfilename = currpath + f"\{now}-result.csv"
htmlreportpath = currpath + f"\{now}-htmlreport"
if not os.path.exists(htmlreportpath):
os.makedirs(htmlreportpath)
execjmxouthtml = f"cmd.exe /c {JMETER_Home} -n -t {tmpjmxfile} -l {csvfilename} -e -o {htmlreportpath}"
execcmd(execjmxouthtml)
if before_check():
create_para_jmxfile()
jobs = [dict(Num_Threads=(x+1), Loops=1) for x in range(10)]
[execjmxs(x["Num_Threads"], x["Loops"]) for x in jobs]
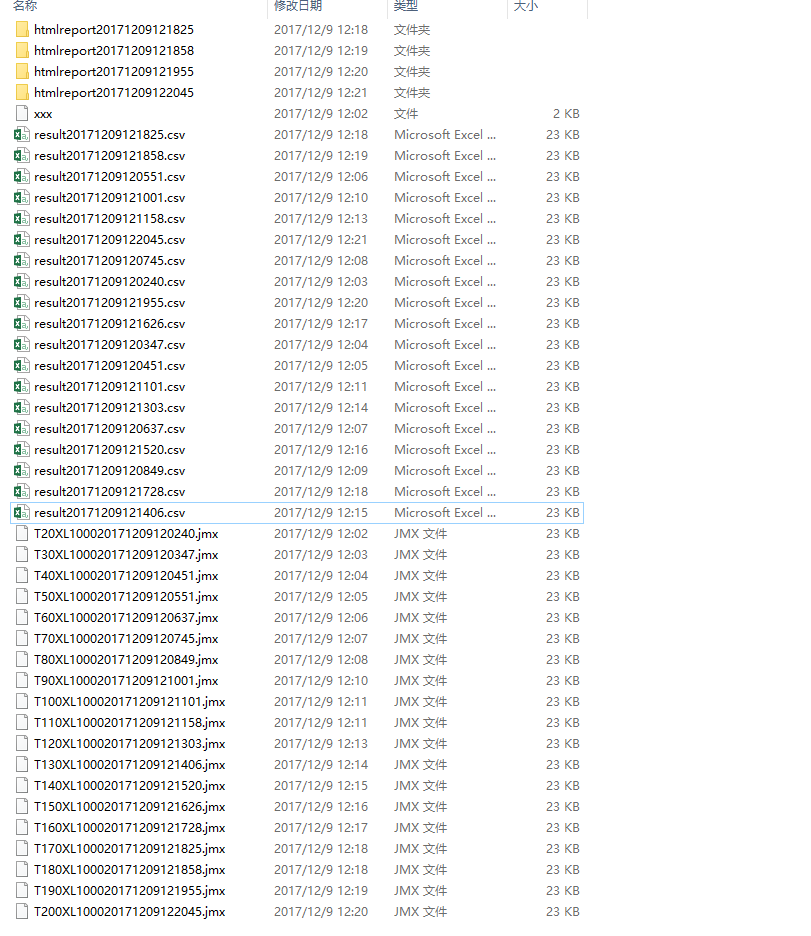
执行代码后,将会生成有规律的文件。文件列表如下:
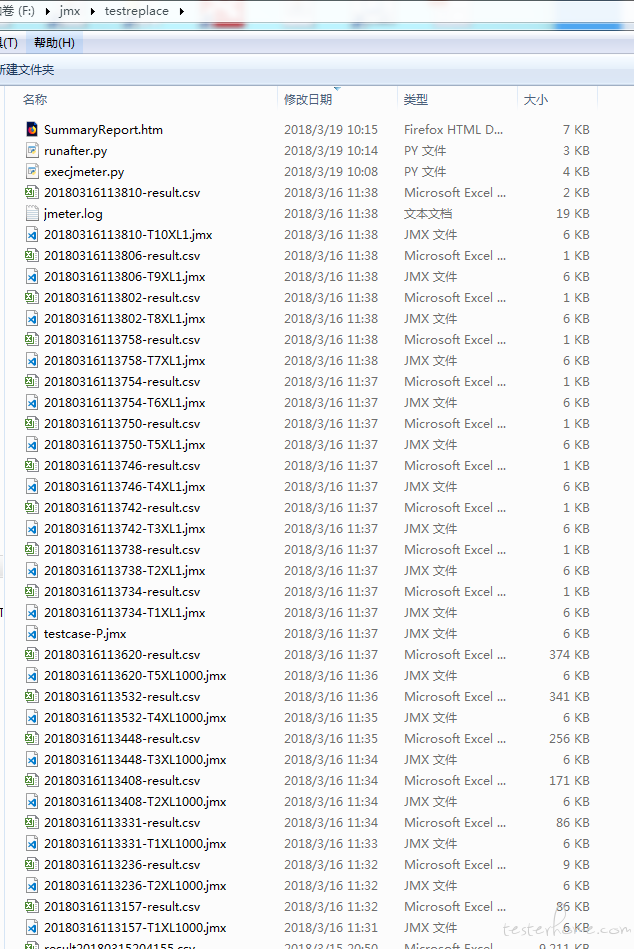
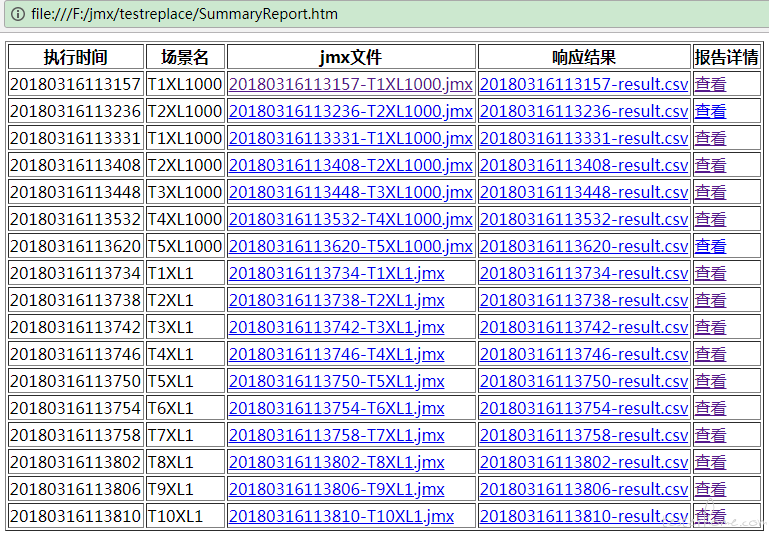
由于持续的多次执行,将会产生很多文件。文件太多,会让人感觉很错乱,看起来累人。比如说每次执行的T 线程数 XL 循环数场景后,都会产生很多文件。文件多了,查看 html 报表需要进入逐个目录打开 index.html 文件查看。于是又想到再做一个 html>表格页面。方便一览查看。便再做了一个 py 脚本,命名为 runafter.py 。当然这还不是最好的,忘记了最初的想要的结果是什么了吗?
import os
from os.path import join
currpath = os.path.dirname(os.path.realpath(__file__))
run_time_list = []
scene_name_list = []
jmxfile_name_list = []
csvfile_list = []
htmlreport_list = []
for root, dirs, files in os.walk(currpath):
for name in files:
if '.jmx' in name and '-' in name and 'XL' in name:
name_split_list = name.split('-')
run_time_list.append(name_split_list[0])
scene_name_list.append(name_split_list[-1].replace('.jmx', ''))
jmxfile_path = join(root, name).replace('\\', '/')
jmxfile_link = f'<a href="file:///{jmxfile_path}" target="_blank">{name}</a>'
jmxfile_name_list.append(jmxfile_link)
csvfile_name = name_split_list[0]+'-result.csv'
csvfile_path = join(root, csvfile_name).replace('\\', '/')
csvfile_link = f'<a href="file:///{csvfile_path}" target="_blank">{csvfile_name}</a>'
csvfile_list.append(csvfile_link)
htmlfile_tail = '\\' + name_split_list[0] + '-htmlreport\\index.html'
htmlfile_path = currpath + htmlfile_tail
htmlfile_path = htmlfile_path.replace('\\', '/')
htmlfile_link = f'<a href="file:///{htmlfile_path}" target="_blank">查看</a>'
htmlreport_list.append(htmlfile_link)
result = [run_time_list, scene_name_list, jmxfile_name_list, csvfile_list,
htmlreport_list]
title = ['执行时间', '场景名', 'jmx文件', '响应结果', '报告详情']
th_str = '<tr>'
for x in title:
th_str = th_str + '<th>' + x + '</th>'
else:
th_str = th_str + '</tr>'
td_str = ''
for index, item in enumerate(run_time_list):
td_str = td_str + '<tr>'
for x in result:
td_str = td_str + '<td>' + x[index] + '</td>'
td_str = td_str + '</tr>'
table_str = f'<table border="1">{th_str}{td_str}</table>'
html_str = f'<!DOCTYPE html><html lang="en"><body><center>{table_str}</center></body></html>'
with open('SummaryReport.htm', 'w', encoding='utf-8') as file:
file.writelines(html_str)
执行完该脚本后,会生成一个 SummaryReport.htm 的 html 表格页面。效果如下:
期间,碰到的坑如下,如命令行执行 Jmeter -n -t {tmpjmxfile} -l {csvfilename} -e -o {htmlreportpath} 命令,由于本渣的 JMETER_Home =D:\Program Files\apache-jmeter\bin,就因为这个就碰到两个坑
一、路径包含空格,识别不了可执行的程序命令
解决办法:命令要用 “” 引号包起来
二、执行命令识别不了 Jmeter,即便将 JMETER_Home 加入 path,或者用 cd 命令进入 JMETER_Home 也无效。
解决办法:控制台用 cmd 命令执行。如"cmd.exe /c {JMETER_Home} -n -t {tmpjmxfile} -l {csvfilename} -e -o {htmlreportpath}"