Docker 测试开发之路--kubeadm 搭建 kubernetes 集群踩坑记
背景
好久没写文章了,想想都有一个月了吧,还是头一次间断了这么长的时间。 其实我是想写的, 但是自从某天我写代码写 high 了没管待产的女王大人导致女王大人暴怒狠镭了我一顿之后。在家的时候我就老老实实的当乖宝宝了。上次参见完测试沙龙之后就答应大家要写一些关于 docker 和 kubernetes(以下简称 k8s) 的文章。 今天先给大家补上一篇吧 (上周 5 发版,今天开始不忙了,中午偷闲写篇文章,不要向我老板打小报告啊嘿嘿)。
kubeadm 介绍
我们都知道集群这个东西从来就不是简单的事。在 kubeadm 出现之前我们搭建一个 k8s 的集群是很费劲的, 需要安装各种服务,配置各种参数。 随着 docker1.12 发布的 swarm mode 打破了集群搭建困难这个事。它能使用一条命令就创建一个集群出来, 极大的降低了 swarm mode 的使用门槛, 即便你只是刚刚入门没多久的 docker 使用者, 也可能很容易的搭建出一个 swarm 集群玩玩。基于这种简化操作,降低使用门槛的目的。 google 也随之推出了 kubeadm 这个工具, 同样提供一个 kubeadm init 命令初始化集群, kubeadm join 扩充节点。使得我们可以很方便的搭建出我们自己的集群。 同时你仍然可以根据你自己的需要安装各种 add-on 来扩充集群功能。 这些 add-on 全部是容器化部署,你可以在 k8s 的 github 上找到。使用简单方便。
注:之前 kubeadm 是处于α版本,随着最近 k8s1.6 的发布 kubeadm 也到了 beta 版本。比之前稳定了一些但仍然有一些坑。 所以你在使用 kubeadm 命令的时候也会提示你当前 kubeadm 处于 beta 版本,请不要应用于生产环境。 所以如果大家使用的时候碰到一些坑也请淡定~~ 毕竟这还不是稳定版本。
准备工作
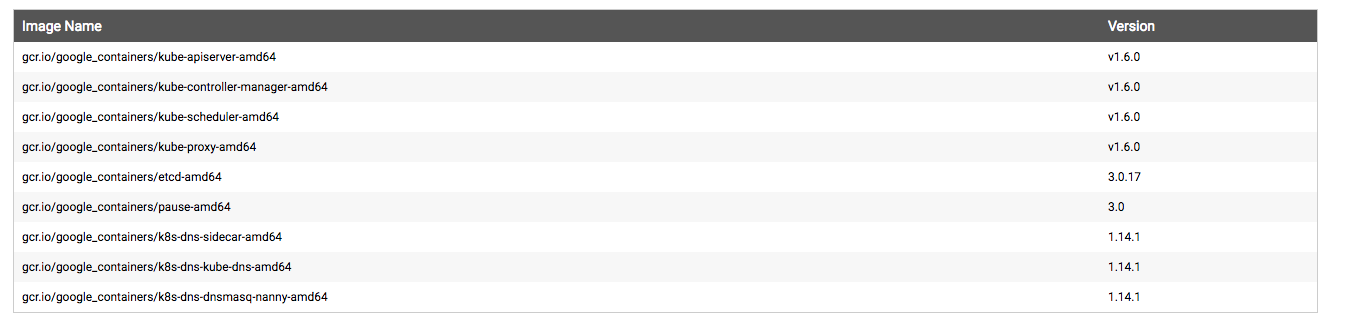
我司是默认,所以省却了我手动下载部署镜像再导到服务器上的麻烦了,如果没有 *** 的小伙伴可以参考https://mritd.me/2016/10/29/set-up-kubernetes-cluster-by-kubeadm/ 。 1.6 版本的 k8s 需要以下镜像:
我使用的是 centos7。所以是用 systemd 管理 docker 和 kubelet 的。yum 安装相关软件。 首先是添加源。
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-${ARCH}
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg
https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
EOF
然后安装相关软件。
yum install -y docker kubelet kubeadm kubectl kubernetes-cni
systemctl enable docker && systemctl start docker
systemctl enable kubelet && systemctl start kubelet
初始化集群
kubeadm init
[kubeadm] WARNING: kubeadm is in beta, please do not use it for production clusters.
[init] Using Kubernetes version: v1.6.0
[init] Using Authorization mode: RBAC
[preflight] Running pre-flight checks
[preflight] Starting the kubelet service
[certificates] Generated CA certificate and key.
[certificates] Generated API server certificate and key.
[certificates] API Server serving cert is signed for DNS names [kubeadm-master kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 10.138.0.4]
[certificates] Generated API server kubelet client certificate and key.
[certificates] Generated service account token signing key and public key.
[certificates] Generated front-proxy CA certificate and key.
[certificates] Generated front-proxy client certificate and key.
[certificates] Valid certificates and keys now exist in "/etc/kubernetes/pki"
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/admin.conf"
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/kubelet.conf"
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/controller-manager.conf"
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/scheduler.conf"
[apiclient] Created API client, waiting for the control plane to become ready
[apiclient] All control plane components are healthy after 16.772251 seconds
[apiclient] Waiting for at least one node to register and become ready
[apiclient] First node is ready after 5.002536 seconds
[apiclient] Test deployment succeeded
[token] Using token: <token>
[apiconfig] Created RBAC rules
[addons] Created essential addon: kube-proxy
[addons] Created essential addon: kube-dns
Your Kubernetes master has initialized successfully!
To start using your cluster, you need to run (as a regular user):
sudo cp /etc/kubernetes/admin.conf $HOME/
sudo chown $(id -u):$(id -g) $HOME/admin.conf
export KUBECONFIG=$HOME/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
http://kubernetes.io/docs/admin/addons/
You can now join any number of machines by running the following on each node
as root:
kubeadm join --token <token> <master-ip>:<master-port>
如果一切正常,那么运行完这一条命令你就可以看见如上的提示。 在另一个节点运行 kubeadm join 就可以加入到集群上了。 这里需要注意几点:
- 根据上面的提示可以知道如果你想使用集群必须有相应的权限。 你需要运行下面的命令才能使用集群。
sudo cp /etc/kubernetes/admin.conf $HOME/
sudo chown $(id -u):$(id -g) $HOME/admin.conf
export KUBECONFIG=$HOME/admin.conf
- 根据上面的提示可以知道目前我们是没有容器网络的。也就是说现在 kube-dns 是无法工作的。 你需要选择安装一个网络插件来完成容器网络的安装。 我选择的是 weave。如下:
shell kubectl apply -f https://git.io/weave-kube-1.6
其他服务
通过上面的命令我们就已经搭建好了一个集群。 但是我们需要一些其他的服务,例如用 kube-dashbord 提供 UI 界面管理集群. 安装 ingress 网络提供 7 层路, 安装 heapster 监控集群等。好在这些服务 google 都提供了容器化部署方案。 我们挨个去下载就好了。
坑,大坑
好了,上面说的是很简单的。随便运行几个命令一个集群就好了。 但我几乎从来没这么顺利过, google 自己都说 kubeadm 还在 beta 版本么,有坑很正常~~ 那下面我来列一下我记得的几个坑吧。
kubelet 的 cgroup-driver 与 docker 设置的不一致导致无法启动
这个好特么坑,docker 是使用 cgroup 技术来限制容器的资源的。 docker 的启动参数中特意有一个参数是--cgroup-driver。 我本机的 docker 设置的为 cgroups。 而不幸的是在某个 linux 发行版的默认设置的 diver 为 systemd 后。 kubeadm 也给 kubelet 的这个默认参数设置为 systemd 了。 这就导致你看 kubelet 的日志的时候发现类似下面的错误信息:
kubelet: error: failed to run Kubelet: failed to create kubelet: misconfiguration: kubelet cgroup driver: "systemd" is different from docker cgroup driver: "cgroups"
解决方案倒是挺简单的。编辑 kubel 的配置文件,把 driver 的类型改了。 路径在: /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
重启 kubelet,问题解决
安装的 add-on 没有权限访问集群资源
这个也是坑的一 B。 由于 k8s 在升级到 1.6 版本以后就抛弃了以前的权限控制方式,而是使用了基于角色的 RBAC 的机制。 所以之前我们使用的所有 add-on 的镜像都没有了权限。 这个坑了我一下午, 我到各个 github 上去找可以在 1.6 上使用的镜像。可是还是有一小部分例如 heapster 没有更新基于 RBAC 机制的镜像。 所以最后我干脆大笔一挥。直接开了 admin 权限给所有角色用户 (官方很不建议这么做). 命令如下:
kubectl create clusterrolebinding permissive-binding \
--clusterrole=cluster-admin \
--user=admin \
--user=kubelet \
--group=system:serviceaccounts
kube reset 毁所有
在之前版本的 kubeadm 上发现了这个问题。 好像最新的已经没有这个问题了。 就是 kube reset 这个命令, 一个让你倾家荡产的命令。如果有些时候你要重新搭建集群,这个命令会帮助清除之前安装的痕迹。它是下面这 4 个命令的组合
systemctl stop kubelet;
docker rm -f -v $(docker ps -q);
find /var/lib/kubelet | xargs -n 1 findmnt -n -t tmpfs -o TARGET -T | uniq | xargs -r umount -v;
rm -r -f /etc/kubernetes /var/lib/kubelet /var/lib/etcd;
看到第二条命令的时候我就开始颤抖了。 他会删除掉你所有的容器,即便是跟 k8s 没关系的。 所以当我抱着试试看的心思运行这个命令之后。。。。可想而知,我心里那是一万头某种动物飘过。。。 长记性以后我就手动运行第 1,3,4 条命令清理 k8s 了~~ 不过我再最新的 kubeadm 上运行 reset 好像已经不会清理其他不相关的容器了。 这个坑好歹是填上了。
kubectl logs 和 kubectl exec 无法与其他节点通讯
现在我们来到巨坑的 iptables 问题。 不论是 k8s 还是 docker,只要想做端口映射必然就得用 iptables 中 nat 这张表的 prerouting 这条链。k8s 是不会清理你现有防火墙的规则的。 所以一旦如果你本机的 iptables 把 k8s 的网络给堵死了。。。例如我的机器。。。 那一定又是一万头某种动物飘过。。。。 好了,我说一下现象。 如果你发现 kubectl logs 和 kubectl exec 无法跟其他节点的容器通信的时候。 你就要好好查查你这些节点的 iptables 规则了。 我当时是发现 input 链里竟然把 TCP 的 10250 端口给堵死了。。。这就是 kubectl logs 和 kubectl exec 需要用到的端口。所以添加如下规则,打开端口:
iptables -I INPUT -p tcp -m tcp --dport 10250 -j ACCEPT
weave 网络失效,pod 内部无法 ping 通 kube dns
这又是一个 iptables 的坑。当时我发现所有运行在从节点的容器全部失败。由于容器内部根本 ping 不通 kube dns。返回访问被禁止, 当时又是一句我去你妈到底哪里又给 weave 的网络给堵死了。我翻遍了 iptables 的 input 和 output 链都没找到原因。 后来突然想起来了 weave 的网桥跟本机网卡是要走 forward 链的。 于是跑去查一下 forward 链里是不是有什么蛋疼的规则。 果然, 有这么一条规则如下:
REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
这条规则的意思是只要上面没有任何一条规则命中,就拒绝转发并且返回连接禁止的提示。 于是乎删掉这条规则,问题解决。 为了确保万无一失,在安装 docker 和 k8s 前最好把上面的规则都给删了。 或者给 input,output,forward 链上都增加如下的规则,把 weave 需要的端口给打开。 否则一碰到问题是真心很蛋疼的。
iptables -I INPUT -p udp -m udp --dport 6784 -j ACCEPT
iptables -I INPUT -p udp -m udp --dport 6783 -j ACCEPT
iptables -I INPUT -p tcp -m tcp --dport 6783 -j ACCEPT
Heapster 报错
当我安装了 heapster 后,本打算欢喜的跑上去看看监控的图形界面的。 但是突然发现 headster 一直在报错。 错误信息我也看不懂。 几经周折,终于在 heapster 的 github 上找到了一个人提的 issue 跟我碰到同样的情况。 如下:

意思是我们的节点上有个容器的名字是包含英文的句号:. 我赶忙找了找发现果然我的容器里也有一个是这样的。 哭了,我给自己埋了好大一个坑。把这个容器删除后果然正常运行了。 heapster 是使用 cAdvisor 来采集的。 而 cAdvisor 使用句号来分割容器。 所以一旦我们的容器名里有句号,那就悲剧了
总结
这是我还能记起来的碰到的一些坑。 虽然现在轻描淡写的很容易就能解决了, 但是当初碰见的时候真是撞墙的心都有。说到底还是 kubeadm 虽然简化了操作,但是 k8s 内部已然是复杂的。 不理解 k8s 的一些原理和内部机制,碰上问题的时候真的是搞不了。最近借了 k8s 权威指南打算研读一遍,马哥 linux 视频也下载好了。 是时候重新学一遍基础了。 下一次我会跟大家分享 docker 的网络原理。我觉得这还蛮重要的,因为不懂这些东西的话,碰到问题真搞不定。