前言
之前有过一篇文章是将 sql 的 group 通过 java 进行内存分组并统计。
具体请查看这篇文章:https://testerhome.com/topics/7688
问题
- 上篇文章虽然解决了功能问题,但是效率上很差。
- 回顾那篇文章的策略可以发现,对每个 set 进行遍历,时间复杂度可以到达 n 的立方。
- 仅仅 600 条记录就要运行 1 分钟,简直要人崩溃。
- 那么有没有什么更好的策略呢?
策略
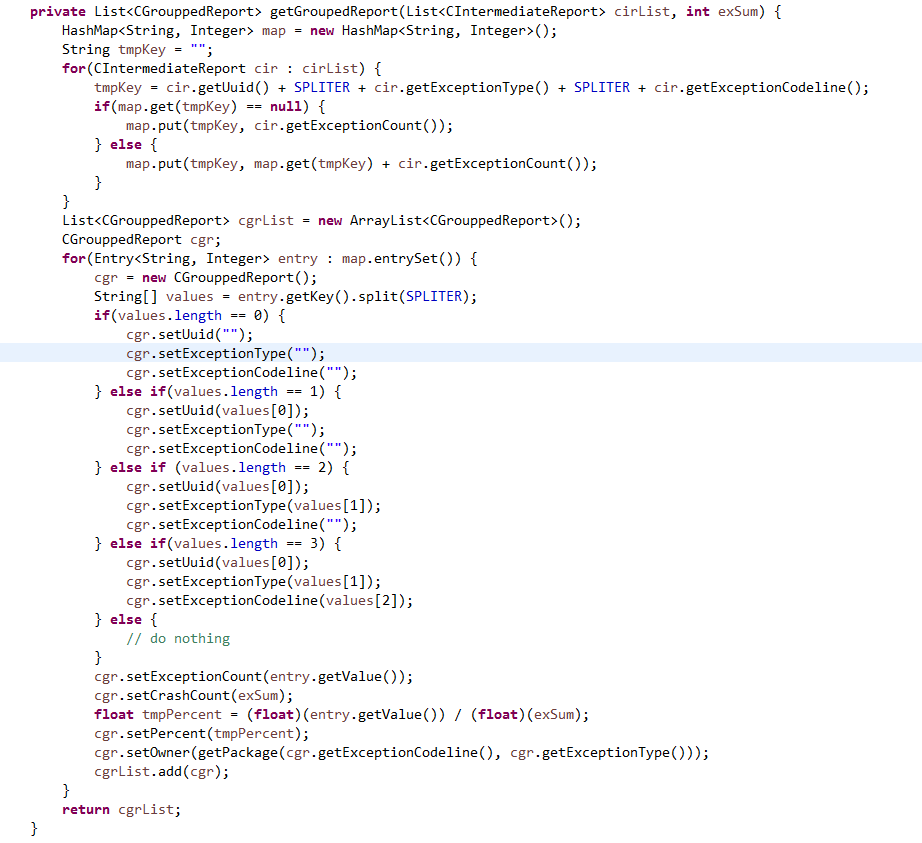
- 这次依然采用 Hash 算法。
- 取而代之的是用 HashMap。
- 遍历原始输入的 List。
- HashMap 的 key 由 List 里的元素的各字段加上一个分隔符组成,如"key" + "@luoshangyu@" + "value" + "@luoshangyu@" + "remark";
- 通过将组合后的 key 输入的 hashMap 中,修改相应的 value 值。
- 比如 key 存在,则其 value 的值加 1。
- 修改完后,运行效率明显提升;原来 600 条数据,运行约 1 分钟;修改后只需要 1 秒中即可。
代码
完!
Best Regards,
Lucas Luo
「原创声明:保留所有权利,禁止转载」
如果觉得我的文章对您有用,请随意打赏。您的支持将鼓励我继续创作!
暂无回复。