Appium python 3.5.1,生成 HTMLTestRunner 报告后,无法显示用例中的 print 字符串
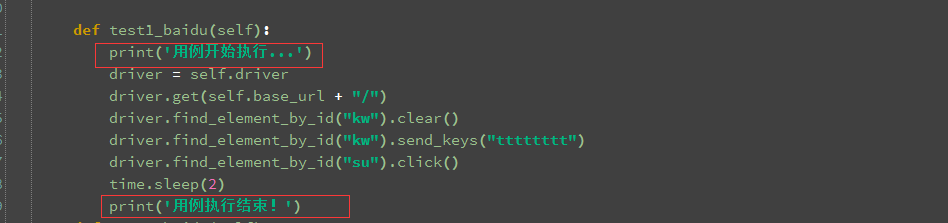
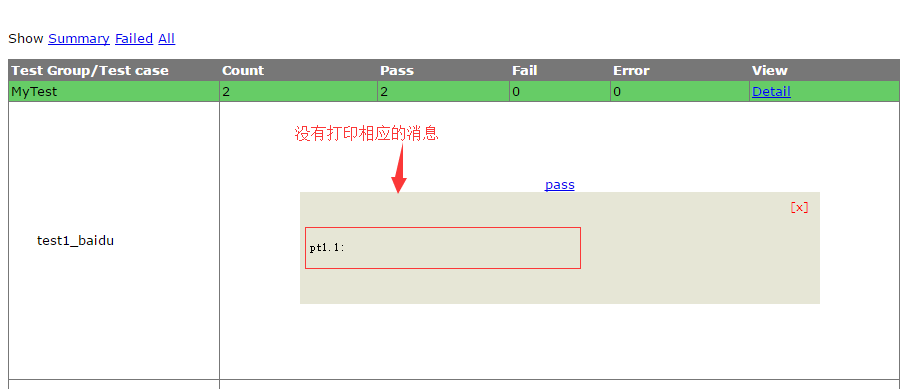
python 3.5.1,生成 HTMLTestRunner 文件后,用例中的 print 无法打印在 html 文件中,请教下这如何代码或文件,用例和截图如下:
网上下的 python 3+HTMLTestRunner 吧?
python 3+ 的 HTMLTestRunner 源码中找到:
if isinstance(o,str):
*******
else:
*******
删掉 if else 直接改成 uo=o
@xiaoj 可以,问题已解决,谢谢。我是网上下载的 HTMLTestRunner 没错
@wanggaoxing 你能生成图片吗
可以啊,你看下和你一不一样,还是你那里生成图片有什么问题?
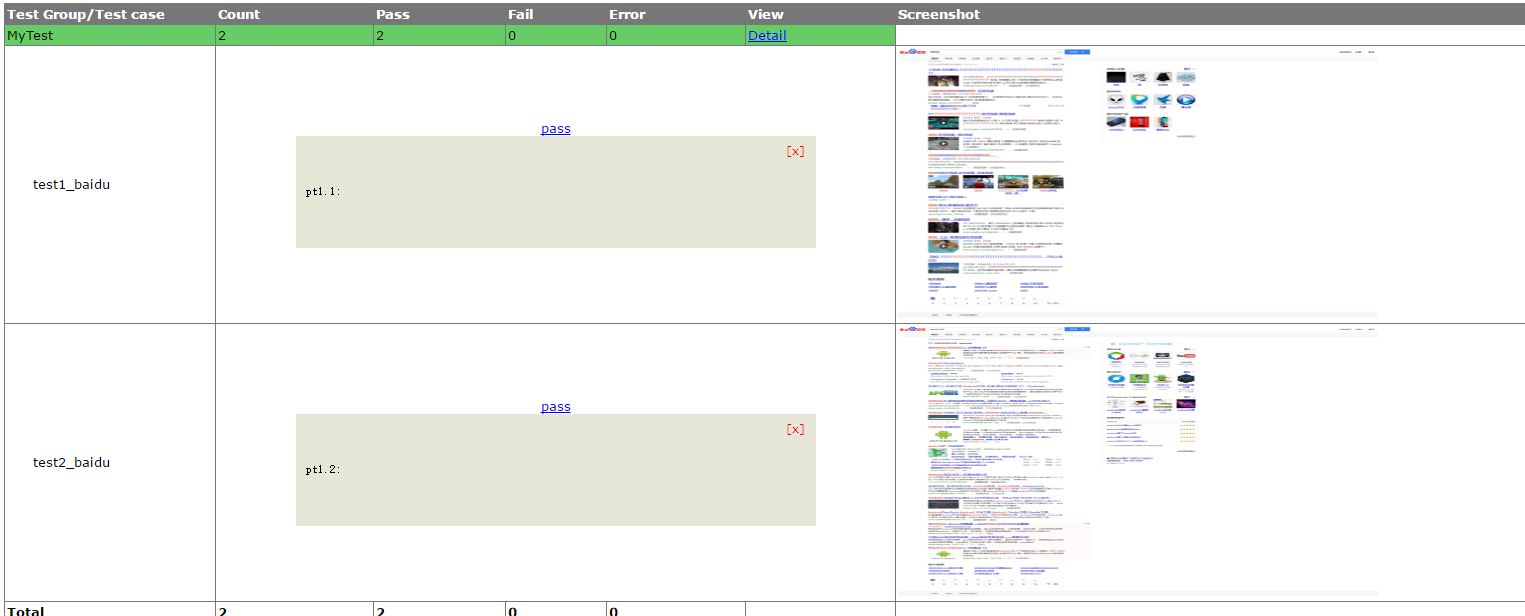
@wanggaoxing 楼主 能给我一个改好格式的 HTMLTestRunner.py 吗
链接地址:http://pan.baidu.com/s/1skXC8m5
用例中也要写一些方法,才能实现截图,下面是一个简答 的用例
import unittest
import HTMLTestRunner
from selenium import webdriver
import time
index = 1 # 这个也和截图有关
class MyTest(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Firefox()
self.driver.maximize_window()
self.driver.implicitly_wait(10)
self.base_url = "http://www.baidu.com"
png_file = 'E:\Test_png\' # 图片存放地址,这个地址要想创建好
def screenshot(self, index): # 需要写这个方法才能实现截图
timestr = time.strftime('%Y%m%d',time.localtime(time.time())) # 精确到秒会无法截图,要和 htmltestrunner.py 文件格式一致
img_name = timestr + '_' + str(index) + '.png' # 图片以时间 + 第几次截图命名
self.driver.get_screenshot_as_file('%s%s' % (self.png_file,img_name)) # 图片保存在定义路径中
return img_name
def test1_baidu(self):
print('用例开始执行...')
driver = self.driver
driver.get(self.base_url + "/")
driver.find_element_by_id("kw").clear()
driver.find_element_by_id("kw").send_keys("tttttttt")
driver.find_element_by_id("su").click()
time.sleep(2)
print('用例执行结束!')
def tearDown(self):
global index
print(index)
self.screenshot(index)
index += 1
print('index2' + str(index))
self.driver.quit()
if name == 'main':
suite = unittest.TestSuite()
suite.addTest(MyTest("test1_baidu"))
timestr = time.strftime('%Y%m%d%H%M%S',time.localtime(time.time()))
filename = 'E:\Test_png\' + timestr + '.html'
runner = unittest.TextTestRunner()
fp = open(filename,'wb')
runner = HTMLTestRunner.HTMLTestRunner(stream=fp,title=u'测试结果:',description=u'运行结果如下:')
runner.run(suite)
fp.close
@wanggaoxing 给楼主点赞
互相帮助,我的问题也解决了。
你好,请教一个问题,如下
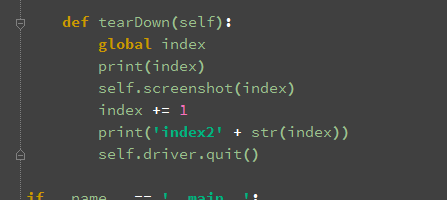
def tearDown(self):
global index
print(index)
self.screenshot(index)
index += 1
print('index2' + str(index))
self.driver.quit()
我目前执行有些用例后会报错,提示 index 没有定义
Error
Traceback (most recent call last):
File "E:\python_Script\yibao\test_Login.py", line 95, in tearDown
print(index)
NameError: name 'index' is not defined
请问你有遇到过这个问题吗?求大神解惑
@lanyou315 你 index 要在 tearDown 外面先定义,可以写在: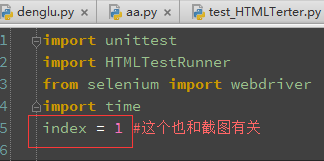
teardown 中写:
现在遇到一个问题,用例执行完了之后,生成报告的时间很慢,是不是跟截图有关?
现在遇到一个问题,用例执行完了之后,生成报告的时间很慢,是不是跟截图有关?我精确到秒进行截图,然后 HtmlTestRunner 的格式也改成 timestr = time.strftime('%Y-%m-%d_%H-%M_%S'),用例中定义截图也是用这个格式,打印出来的报告没有截图,你知道是什么原因吗
HtmlTestRunner 的内容:
def screenshot(self):
timestr = time.strftime('%Y-%m-%d_%H-%M-%S')
global index
img_name = timestr + '_' + str(index) + '.png'
count = 0
while count < 10:
lsdir = os.listdir(self.img_path)
if img_name in lsdir:
index+=1
return self.img_path+img_name
else:
time.sleep(10)
count +=1
用例中的内容:
png_file = 'E:\python_Script\yibao\screenshot\woyao_touzi\' # 图片存放地址,这个地址要先创建好
def screenshot(self, index): # 需要写这个方法才能实现截图
timestr = time.strftime("%Y-%m-%d_%H-%M-%S") # 精确到秒会无法截图,要和 htmltestrunner.py 文件格式一致
img_name = timestr + '_' + str(index) + '.png' # 图片以时间 + 第几次截图命名
self.driver.get_screenshot_as_file('%s%s' % (self.png_file, img_name)) # 图片保存在定义路径中
return img_name
@lanyou315 不能精确到秒,截图是异步加载的,差不都就是我进入一个页面,然后 就已经截图了,然后那一串代码运行完后,再重新截图覆盖原本那张,然后会比对两次的时间,如果时间不一样就判断截图失败,所以精确到分就可以了;
还有你说的截图比较慢,首先 python 运行代码就是偏慢,也要看下你电脑配置怎么样,我这里执行的话是没出现报告生成比较慢的问题
嗯 谢谢大神,
Error
Traceback (most recent call last):
File "E:\python_Script\yibao\test_Login.py", line 95, in tearDown
print(index)
NameError: name 'index' is not defined
这个问题搞定了
不过如果精确到分的话,如果时间超过 1 分钟以上,输出报告会出现有些用例无法获取到截图或者截图错乱的情况,目前感觉精确到小时的话,可以规避这个问题
我也遇到了用例中的 print 无法打印在 html 文件中的问题,你是怎么解决的呢?要修改 HTMLTestRunner 吗
就删掉 if else 直接改成 uo=o,就行了,其他地方不用修改吗,你能把改好的发我邮箱一份吗?万分感谢。我是新学 Python。我邮箱 1246603306@qq.com
你上面百度云这个http://pan.baidu.com/s/1skXC8m5直接下载就可以用吧。截图方法按照你上面说给出的用例就可以了吧。
怎么可以生成在一个文本文件中,类似这种执行命令,‘python test_suite.py > output.log’,print 打印的信息能输出在 output.log 文件中
@wanggaoxing 您好,我是 python3.6 的系统,我的也是出现了你那个问题,输出报告不打印函数信息,也下载了你那个 HTMLTestRunner 文件,可是还是打印不出来
我这边使用了你给我的 HTMLTestRunner 后,可以打印出图片,但只能打印出来最后一张,我想截图每一个页面改怎么处理@wanggaoxing
@xiaoj 根据你说的方法问题已解决
python 3 的 HTMLTestRunner 没找到官网下载地方,官网没有提供么?
为啥这样删掉 if else,uo = o 改就行了呢?