作者:shane,腾讯后台开发高级工程师
QQ18 年
1999年2月10日,腾讯 QQ 横空出世。光阴荏苒,那个在你屏幕右下角频频闪动的企鹅已经度过了 18 个年头。随着 QQ 一同成长的你,还记得它最初的摸样吗?
1999 年:腾讯 QQ 的前身 OICQ 诞生,该版本具备中文网络寻呼机、公共聊天室以及传输文件功能。
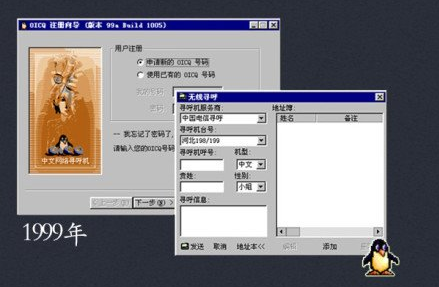
1999 年 QQ 界面
2000 年,OICQ 正式更名为 QQ,发布视频聊天功能、QQ 群和 QQ 秀等功能。
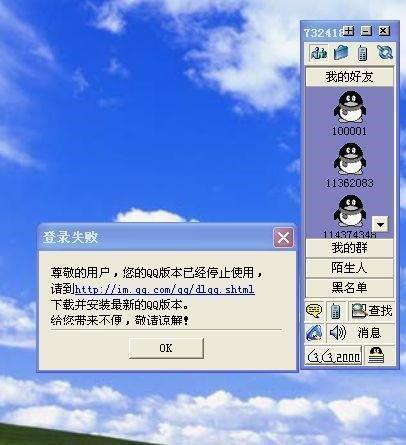
2003 年版本,QQ 发布聊天场景、捕捉屏幕、给好友播放录影及 QQ 炫铃等功能。
2004 年,QQ 新增个人网络硬盘、远程协助和 QQ 小秘书功能。
···
几经更迭,QQ 版本也产生许多变化,很多操作方式都变了,也让 QQ 更有现代感了。如今的 QQ 越来越精美,越来越简洁,如你所见。

据不完全统计,腾讯 QQ 月活用户达到 8.7 亿左右,而这个数字还在不断增加。。。
如此庞大的用户群的任何行为,都会产生巨大的影响。
2017 年春节,QQ 推出 AR 红包加入红包大战,经调查手机 QQ 的红包全网渗透率达到 52.9%。
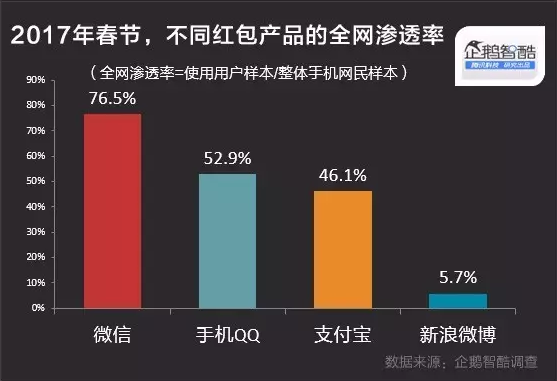
在此期间,后台想必又一次承受了海量的压力,年后第一波推送,来看看腾讯内部对 QQ 后台的接口处理的相关技术干货,或许可以给到你答案。
一、背景
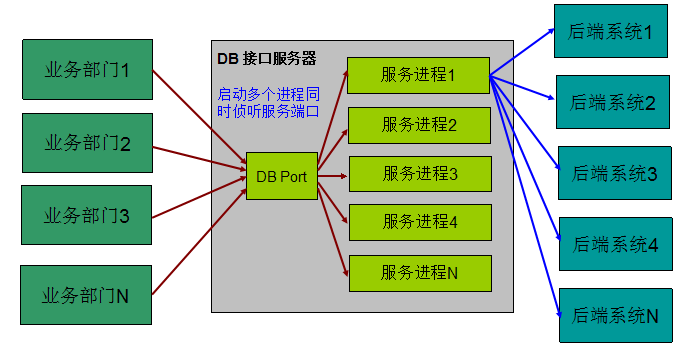
QQ 后台提供了一套内部访问的统一服务接口,对腾讯各业务部门提供统一的资料关系链访问服务,后面我们把这套接口简称为 DB。
现在说说分 set 的背景:2013 年的某一天,某个业务的小朋友在申请正式环境的 DB 接入权限后,使用正式环境来验证刚写完的测试程序,循环向 DB 接口机发送请求包,但因为这个包格式非法,触发了 DB 解包的一个 bug,导致收到这些请求包的服务器群体 core dump,无一幸免。。。。整个 DB 系统的服务顿时进入瘫痪状态。
因此有了故障隔离的需求,2014 年初,我们着手 DB 的故障隔离增强改造。实现方法就是分 set 服务 -- 把不同业务部门的请求定向到不同的服务进程组上,如果某个业务的请求有问题,最多只影响一个部门,不会影响整个服务系统。
二、总体方案
为了更清楚描述分 set 的方案,我们通过两个图进行分 set 前后的对比。
分 set 之前:
分 set 之后:
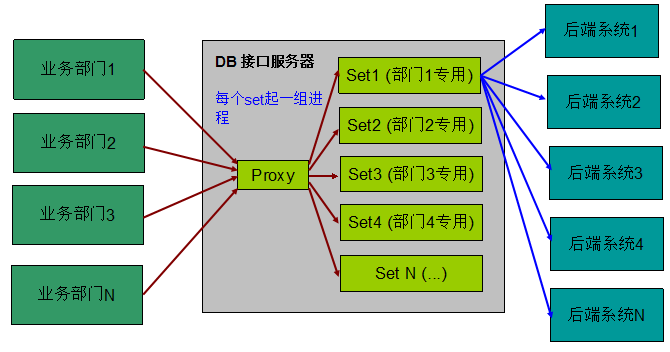
从图中可以看出,实现方式其实非常简单,就是多启动一个 proxy 进程根据 IP 到 set 的映射关系分发请求包到对应 set 的进程上。
三、分 set 尝试
很多事情往往看起来非常简单,实现起来却十分复杂,DB 分 set 就是一个典型的例子。怎么说呢?先看看我们刚开始实现的分 set 方案。
实现方案一:通过 socket 转包给分 set 进程,分 set 进程直接回包给前端。
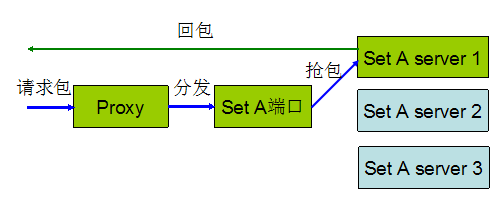
这个方案刚发布几台后就发现问题:
1,有前端业务投诉回包端口不对导致访问失败。后来了解这些业务会对回包端口进行校验,如果端口不一致就会把包丢弃。
2,CPU 比原来上涨了 25%(同样的请求量,原来是 40%,使用这个方案后 CPU 变成 50%)
回包端口改变的问题因为影响业务(业务就是我们的上帝,得罪不起),必须马上解决,于是有了方案二。
实现方案二:通过 socket 转包给分 set 进程,分 set 进程回包给 proxy,由 proxy 回包。
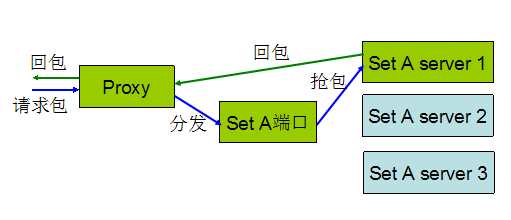
改动很快完成,一切顺利,马上铺开批量部署。。。。
晚上 10 点准时迎来第一次高峰,DB 出现大量的丢包和 CPU 告警,运维紧急迁移流量。
第二天全部回滚为未分 set 的版本。
重新做性能验证的时候,发现 CPU 比原来涨了 50%,按这个比例,原来 600 多台机器,现在需要增加 300 多台机器才能撑起同样请求的容量。(这是写本文时候的机器数,目前机器数已经翻倍了~)
后来分析原因的时候,发现网卡收发包量都涨了一倍,而 CPU 基本上都消耗在内核 socket 队列的处理上,其中竞争 socket 资源的 spin_lock 占用了超过 30% 的 CPU -- 这也正是我们决定一定要做无锁队列的原因。
四、最终实现方案
做互联网服务,最大的一个特点就是,任何一项需求,做与不做,都必须在投入、产出、时间、质量之间做一个取舍。
前面的尝试选择了最简单的实现方式,目的就是为了能够尽快上线,减少群体 core 掉的风险,但却引入了容量不足的风险。
既然这个方案行不通,那就得退而求其次(退说的是延期,次说的是牺牲一些人力和运维投入),方案是很多的,但是需要以人力作为代价。
举个简单的实现方法:安装一个内核模块,挂个 netfilter 钩子,直接在网络层进行分 set,再把回包改一下发送端口。
这在内核实现是非常非常简单的事情,但却带来很大的风险:
1,不是所有同事都懂内核代码
2,运营环境的机器不支持动态加载内核模块,只能重新编译内核
3,从运维的角度:动内核 == 杀鸡取卵 -- 内核有问题,都不知道找谁了
好吧,我无法说服开发运营团队,就只能放弃这种想法了 -- 即便很不情愿。
。。。跑题了,言归正传,这是我们重新设计的方案:
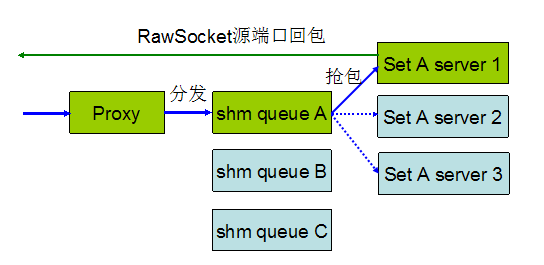
方案描述:
1,使用一写多读的共享内存队列来分发数据包,每个 set 创建一个 shm_queue,同个 set 下面的多个服务进程通过扫描 shm_queue 进行抢包。
2,Proxy 在分发的时候同时把收包端口、客户端地址、收包时间戳(用于防滚雪球控制,后面介绍)一起放到 shm_queue 中。
3,服务处理进程回包的时候直接使用 Raw Socket 回包,把回包的端口写成 proxy 收包的端口。
看到这里,各位同学可能会觉得这个实现非常简单。。。不可否认,确实也是挺简单的~~
不过,在实施的时候,有一些细节是我们不得不考虑的,包括:
1)这个共享内存队列是一写多读的(目前是一个 proxy 进程对应一组 set 化共享内存队列,proxy 的个数可以配置为多个,但目前只配一个,占单 CPU 不到 10% 的开销),所以共享内存队列的实现必须有效解决读写、读读冲突的问题,同时必须保证高性能。
2)服务 server 需要侦听后端的回包,同时还要扫描 shm_queue 中是否有数据,这两个操作无法在一个 select 或者 epoll_wait 中完成,因此无法及时响应前端请求,怎么办?
3)原来的防滚雪球控制机制是直接取网卡收包的时间戳和用户层收包时系统时间的差值,如果大于一定阀值(比如 100ms),就丢弃。现在 server 不再直接收包了,这个策略也要跟着变化。
基于 signal 通知机制的无锁共享内存队列
A. 对于第一个问题,解决方法就是无锁共享内存队列,使用 CAS 来解决访问冲突。
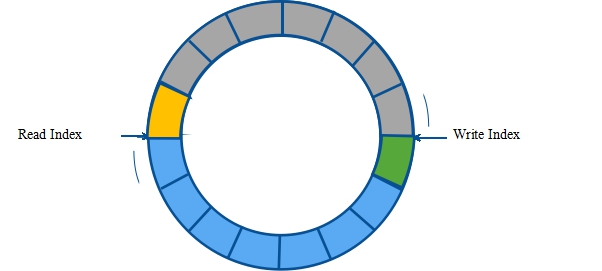
这里顺便介绍一下 CAS(Compare And Swap),就是一个汇编指令 cmpxchg,用于原子性执行 CAS(mem, oldvalue, newvalue):如果 mem 内存地址指向的值等于 oldvalue,就把 newvalue 写入 mem,否则返回失败。
那么,读的时候,只要保证修改 ReadIndex 的操作是一个 CAS 原子操作,谁成功修改了 ReadIndex,谁就获得对修改前 ReadIndex 指向元素的访问权,从而避开多个进程同时访问的情况。
B. 对于第二个问题,我们的做法就是使用注册和 signal 通知机制:
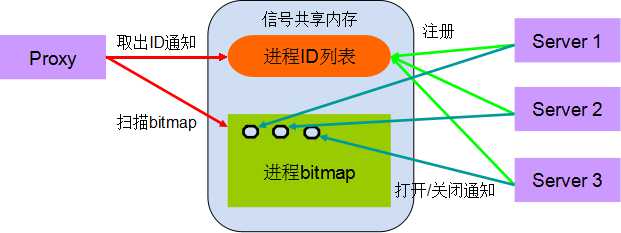
工作方式如下:
1)Proxy 负责初始化信号共享内存
2)Server 进程启动的时候调用注册接口注册自己的进程 ID,并返回进程 ID 在进程 ID 列表中的下标(sigindex)
3)在 Server 进入睡眠之前调用打开通知接口把 sigindex 对应的 bitmap 置位,然后进入睡眠函数(pselect)
4)Proxy 写完数据发现共享内存队列中的块数达到一定个数(比如 40,可以配置)的时候,扫描进程 bitmap,根据对应 bit 为 1 的位取出一定个数(比如 8,可以配置为 Server 进程的个数)的进程 ID
5)Proxy 遍历这些进程 ID,执行 kill 发送信号,同时把 bitmap 对应的位置 0(防止进程死了,不断被通知)
6)Server 进程收到信号或者超时后从睡眠函数中醒来,把 sigindex 对应的 bit 置 0,关闭通知
除了 signal 通知,其实还有很多通知机制,包括 pipe、socket,还有较新的内核引入的 eventfd、signalfd 等等,我们之所以选择比较传统的 signal 通知,主要因为简单、高效,兼容各种内核版本,另外一个原因,是因为 signal 的对象是进程,我们可以选择性发送 signal,避免惊群效应的发生。
防滚雪球控制机制
前面已经说过,原来的防滚雪球控制机制是基于网卡收包时间戳的。但现在 server 拿不到网卡收包的时间戳了,只能另寻新路,新的做法是:
Proxy 收包的时候把收包时间戳保存起来,跟请求包一起放到队列里面,server 收包的时候,把这个时间戳跟当前时间进行对比。
这样能更有效的做到防滚雪球控制,因为我们把这个包在前面的环节里面经历的时间都考虑进来了,用图形描述可能更清楚一点。

五、性能验证
使用 shm_queue 和 raw socket 后,DB 接口机处理性能基本跟原来未分 set 的性能持平,新加的 proxy 进程占用的 CPU 一直维持在单 CPU 10% 以内,但摊分到多个 CPU 上就变成非常少了(对于 8 核的服务器,只是增加了 1.25% 的平均 CPU 开销,完全可以忽略不计)。
最后,分 set 的这个版本已经正式上线运行一段时间了,目前状态稳定。
对许多企业而言,虽不一定经历月活 8 亿用户,但为了能够面对蜂拥而来的用户游刃有余,时刻了解并保持自己的最优状态迎接用户,一定要在上线之前对自己的网站承载能力进行一个测试。如果自己没有服务器,没有人力,没有钱,都没有关系。。。
腾讯提供了一个可以自主进行服务器性能测试的环境,用户只需要填写域名和简单的几个参数就可以获知自己的服务器性能情况,目前在腾讯 WeTest 平台可以免费使用。
腾讯 WeTest 服务器性能测试运用了沉淀十多年的内部实践经验总结,通过基于真实业务场景和用户行为进行压力测试,帮助游戏开发者发现服务器端的性能瓶颈,进行针对性的性能调优,降低服务器采购和维护成本,提高用户留存和转化率。
功能目前免费对外开放中,点击 http://WeTest.qq.com/gaps 即可体验!
如果对使用当中有任何疑问,欢迎联系腾讯 WeTest 企业 qq:800024531
