前言
上一次写了一些持续集成的东西,但是写着写着重点就跑偏了。。。跑到自动化测试分享去了。比较重要的分支模型那部分没说明白。我在这补充一下吧。
分支模型的补充
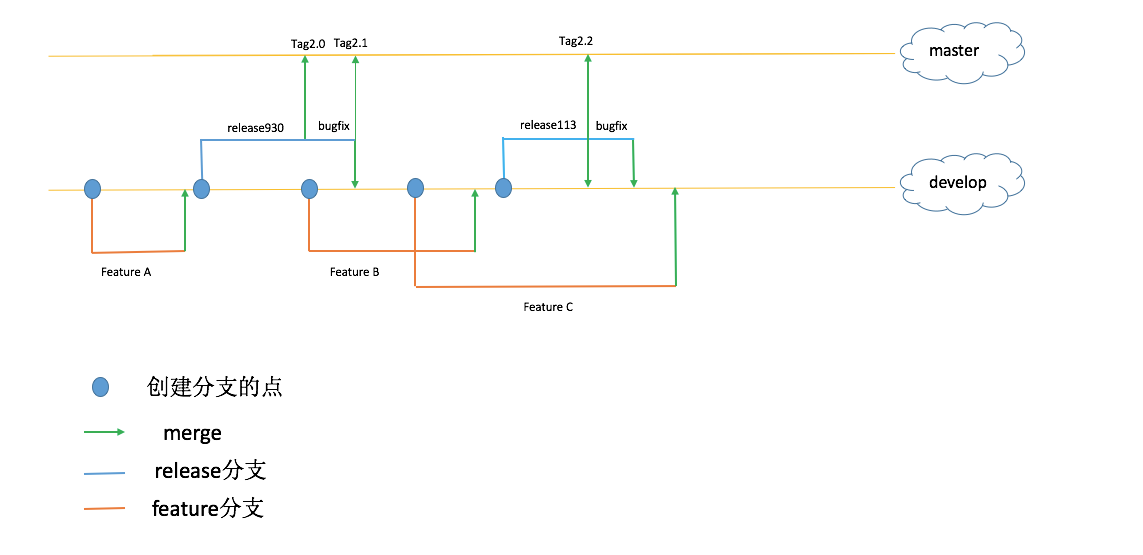
我屏蔽了 hotfix 分支的影响以让分支图看起来清晰一点。我由下往上一个一个说吧。
- feature:每个新特性和重构的开发分支。所有的测试行为结束后合并回 develop 主干上。为了能尽早的发现问题,我们会每天从 develop 分支把代码 merge 到 feature 上以尽早做集成测试。
- develop:开发主干,所有 feature 在完成特性开发合测试后合并回 develop。开发阶段最重要的分支
- release:当要发布一个版本的时候从 develop 上拉出一个 release 分支进行测试。有 bug 修 bug,测试结束后分别向 master 和 develop 合并。To B 和 To C 的业务在这里有个区别,To C 的业余一般就只有一个 release 分支贯穿整个软件生命周期。 但是 To B 的业务每个版本就都有一条 release 分支对应。因为一个版本对应着一批用户,用户是不会轻易升级软件到最新版本的。
- master: 这个就不用解释了吧。。
CI 策略的补充
总结以往的经验,我们发现版本发布延期和质量不高的主要原因在于问题暴露的过晚,在版本发布阶段堆积了过多的问题导致在时限内无法完成。造成这样的原因有以下 2 点:
- 手动测试耗费很大的人力和时间,很多测试只在验收阶段执行,导致一些 bug 发现的过晚。
- 开发代码相互集成的时间过晚,很多集成问题 (如代码冲突,功能冲突) 总是在最后才发现。
所以本着尽早集成,尽早测试,尽早反馈,尽早解决的原则。我们设计以下的 CI 模式
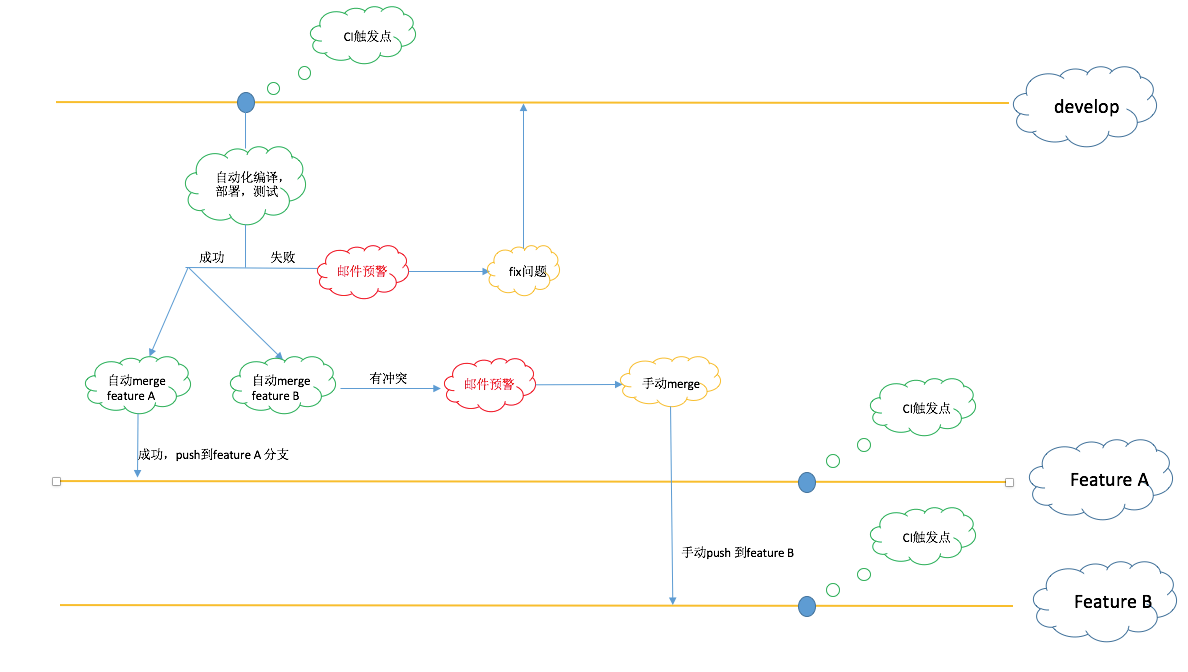
由于上一篇文章中已经说了一些了,所以我这里补充两个比较重要的说明
- 在 develop 的 CI 通过测试后,自动的把代码合并到各个 feature 分支上是为了能尽早的做集成测试
- 测试代码也走多分支模型,是为了自动化测试能适应每个不同行为的 feature 分支的测试工作
问题:
我们希望的是 develop 分支的自动化测试通过后才 merge 代码,以保证不会把 develop 的 bug 带到各个 feature 分支上影响 feature 分支的质量。这时候 UI 自动化的不稳定就带来了一些问题。虽然我们花了一些心思在 UI 自动化的稳定上 (如我上一篇文章中介绍的自动化测试维稳的方法)。但从目前的效果来看差不多每 5 次运行里总有一次会因为某些不稳定因素导致 case 失败的。所以我们目前的做法是如果 case 是由于不稳定因素失败的,我们就人为手动的触发 merge 代码的那个 job。
关于自动 merge 的一些说明
两种方案:一种是使用 jenkins 的 git lab 插件,里面有一个 merge before build 和 git publisher。在 build 之前执行 merge,执行自动化后 push 代码到 feature 分支上去。 不过面对众多的 feature 分支需要建立很多的 job,而且这个插件设计的初衷是 feature 分支的自动化测试通过后 merge 到 develop 分支上去。所以不是那么契合我们想要的场景。所以就有了第二个方案,就是写一段脚本去执行 merge 的操作。所以我们公司的一个小伙伴用 shell 写了几个脚本来完成这件事。我贴一下主要的一段
. ./configs/prophet.conf
. ./common.sh
if [ "$#" != 2 ]; then
echo "usage: merge.sh src_branch dest_branch"
exit 1
fi
src_branch=$1
dest_branch=$2
conflict_dir="../conflicts/"$dest_branch"/"
cd $SRC_DIR
for module in ${MODULES[@]}; do
echo "entering module: "$module" !!!!!!!!!!"
cd $module
if git_branch_exists $src_branch && git_branch_exists $dest_branch; then
git checkout $src_branch
git pull $ORIGIN $src_branch
git checkout $dest_branch
git pull $ORIGIN $dest_branch
git merge --no-edit $src_branch
if [ $? -ne 0 ]; then
mkdir -p $conflict_dir
git diff --diff-filter=U > $conflict_dir$module
git merge --abort
else
echo "merge successfully!"
git push $ORIGIN $dest_branch
fi
else
echo "either branch "$src_branch" or " $dest_branch " does not exist. skipping..."
fi
cd ..
done
cd ..
逻辑并不难,就是遍历所有 feature 分支的所有模块进行 merge 的操作。如果一个 feature 分支有任何一个模块是有 conflict 的,就不会 push,把 conflict 写入文件中,由另一个脚本发邮件。如果没有任何模块是有 confilct 的。就自动的 push 代码到 feature 分支里。
总结与思考
这是上一篇文章的一个补充吧,内容并不多。中间遇到过很多问题,流程上的例如定制 CI 流程并把 CI 推广到开发人员那去,让大家认可我们的 CI 策略是需要做挺多努力的。 技术上的例如自动化部署方案,配置管理方案,UI 自动化运行时间慢,运行不稳定等等。感觉 CI 就是个堆细节的东西,不断的碰到问题后解决问题。解决的问题足够多,这事基本上就成了。好在我不是孤军奋战,团队中的很多人都在帮我。例如开发的 leader 帮我推行 CI 的流程还帮我写了上面那段自动 merge 的脚本。运维的小伙伴做了配置管理方案,另一个同事在 jekins 上做了分布式自动化执行方案以解决用例执行过慢的问题等等。这就是论团队的重要性了,没有他们这个事也做不好。还有一点,请大家原谅我的懒惰,jenkins 上的好多跟持续集成有关的配置我没详细说明