分享一个自己写的 AI 测试插件 —— AITestCase
前言
大家好,我是一名刚工作一年的测试工程师。去年 12 月到今年 2 月,趁着有点空闲时间,我用业余时间做了一个 AI 驱动的测试工具 —— AITestCase,一款 Chrome 浏览器扩展插件。
最近因为一些个人原因,这个项目暂停迭代了一段时间。现在我打算重新开始维护和更新它,所以想在这里和大家分享一下,也希望能收集到一些实用的需求和建议。
项目地址:https://github.com/LiuYuan0115/AITestCase
💡 为什么做这个插件?
做测试这一年,我发现日常工作中有几个痛点:
- PRD 分析费时间:需求文档来了,要手动梳理功能点、提取测试点
- 测试用例编写重复劳动多:很多场景都是相似的,但还是要一条条写
- UI 自动化成本高:写 Selenium 代码又慢又容易坏,维护成本高
- 质量评估靠人工:用例写完了,覆盖度够不够、有没有遗漏,得靠经验
所以我想,能不能用 AI 来辅助这些工作?让 AI 帮我们做重复劳动,人只需要审核和调整。于是就有了这个项目。
🎯 插件能做什么?
AITestCase 是一个端到端的 AI 测试工作流工具,从需求分析到用例生成,再到 UI 自动化执行,都能用 AI 来辅助完成。
主界面一览
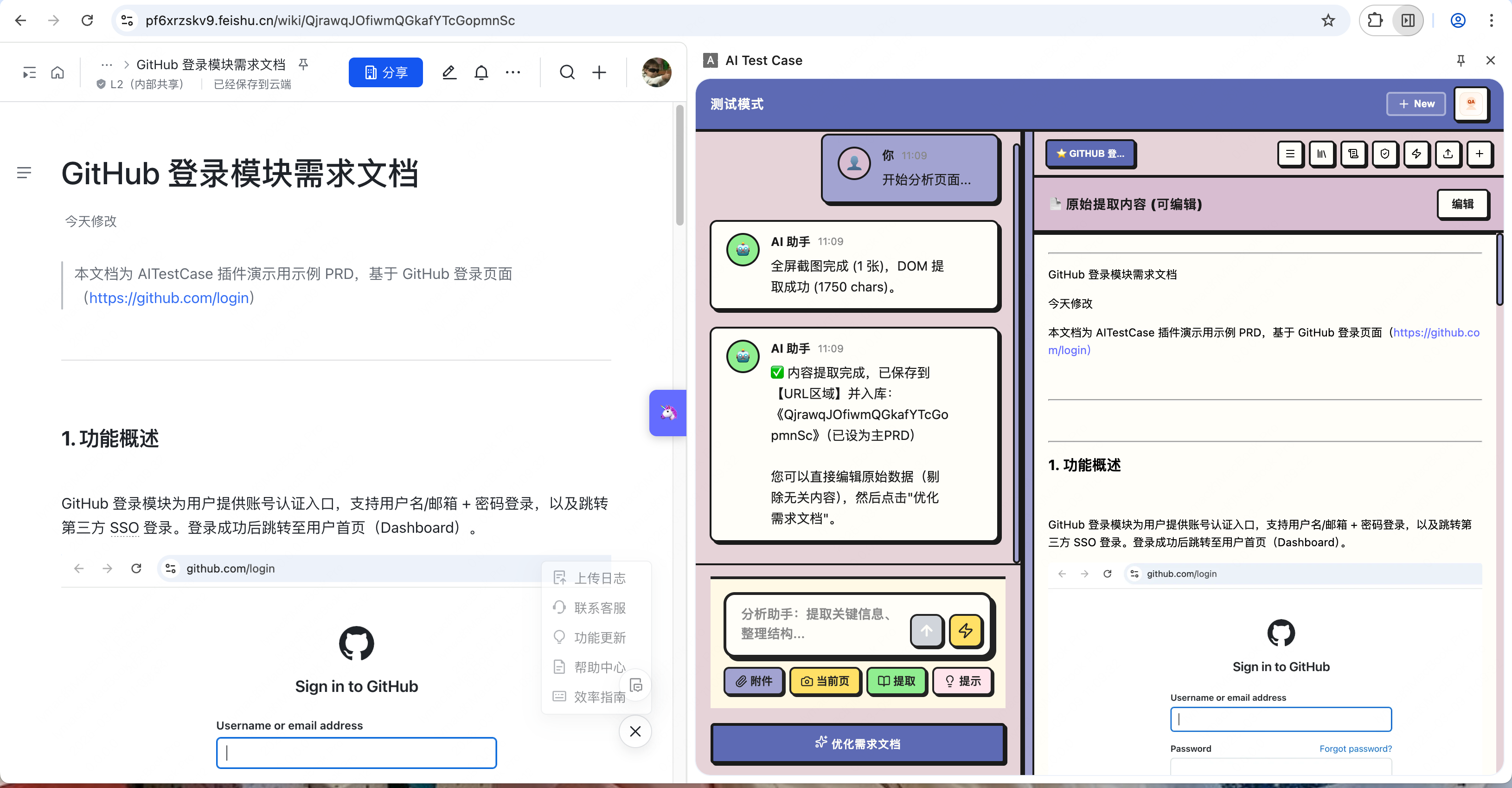
插件提供了三个角色视图(PM / DEV / QA),每个角色都有针对性的 AI 助手。我们测试人员主要用 QA 角色。
QA 工作流:5 个步骤搞定测试
1.分析 → 2.PRD → 3.测试点 → 4.用例 → 5.测试
第 1 步:分析 — 提取需求文档内容
- 输入一个 URL,或者上传 PDF、图片、文字文档
- 插件自动提取页面内容、截图、OCR 识别
- 文档内容会存入知识库,后续可以复用
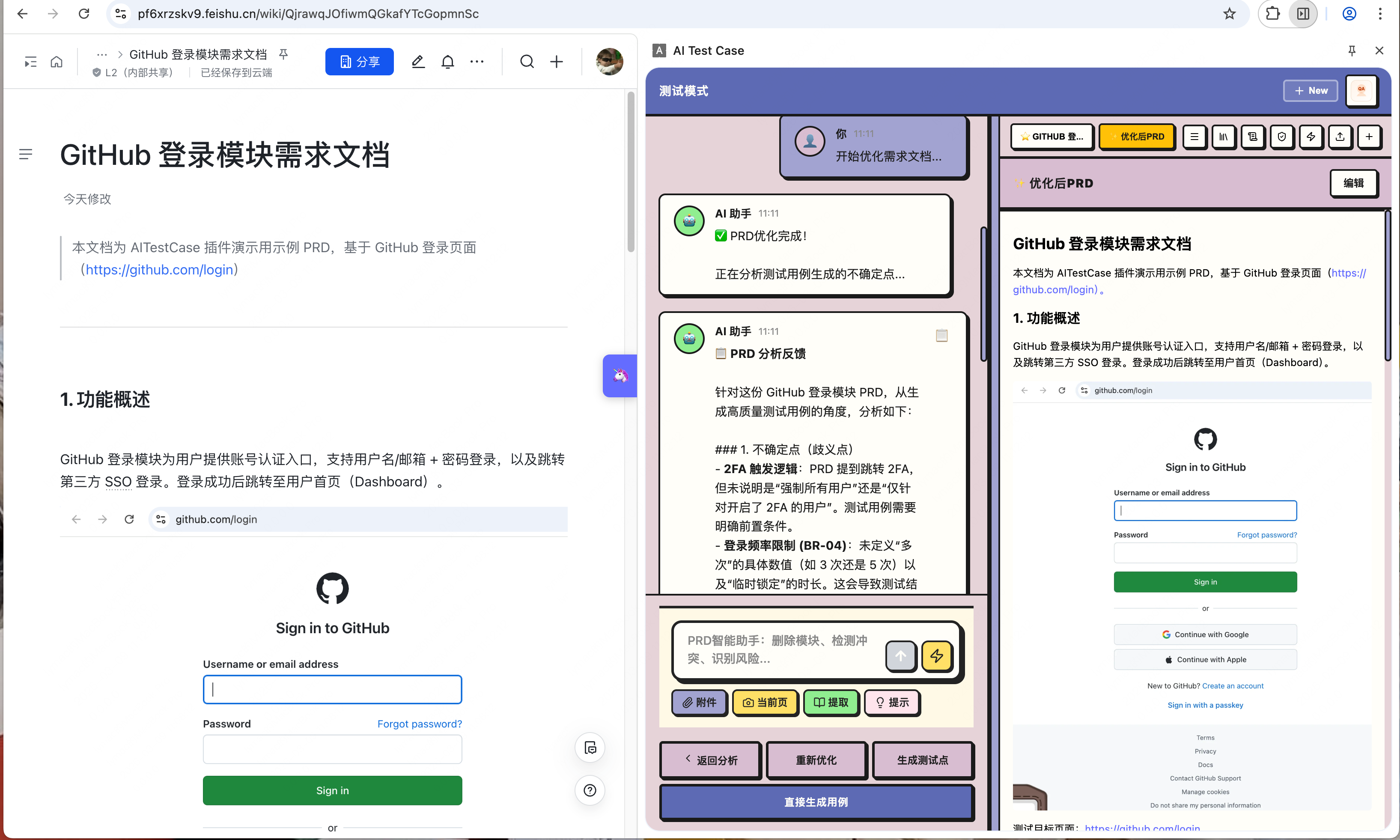
第 2 步:PRD — AI 生成优化的需求文档
- AI 会分析原始需求,输出一份结构化的 PRD 文档
- 包含功能描述、业务规则、边界条件等
- 格式清晰,方便后续测试点提取
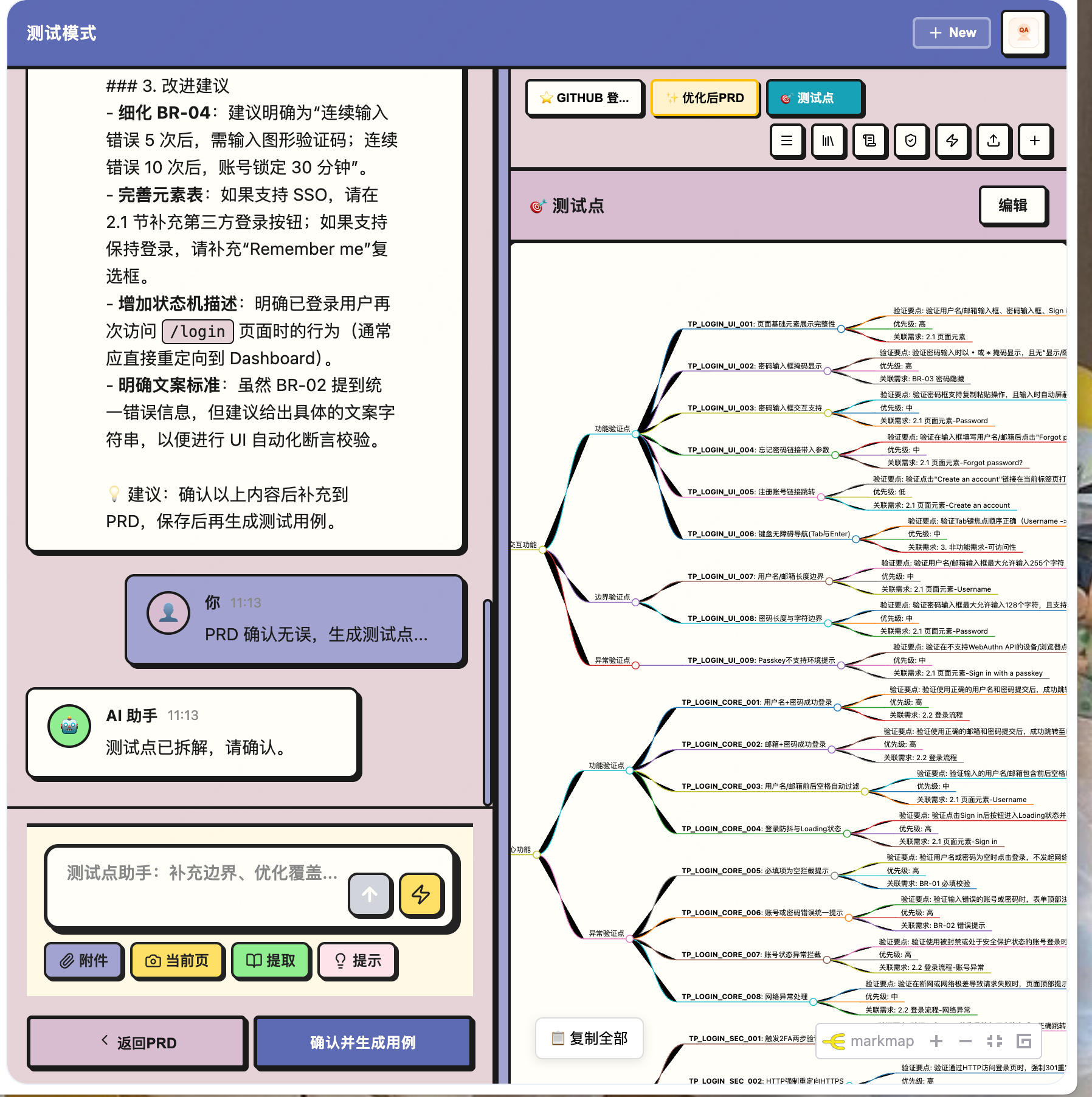
第 3 步:测试点 — 自动提取测试要点
- 基于 PRD 自动提取测试点
- 输出思维导图格式,层次清晰
- 可以手动编辑、补充遗漏的点
第 4 步:用例 — 生成测试用例
- 根据测试点生成详细的测试用例
- 支持多种格式:思维导图、表格、YAML、JSON
- 用例包含前置条件、操作步骤、预期结果
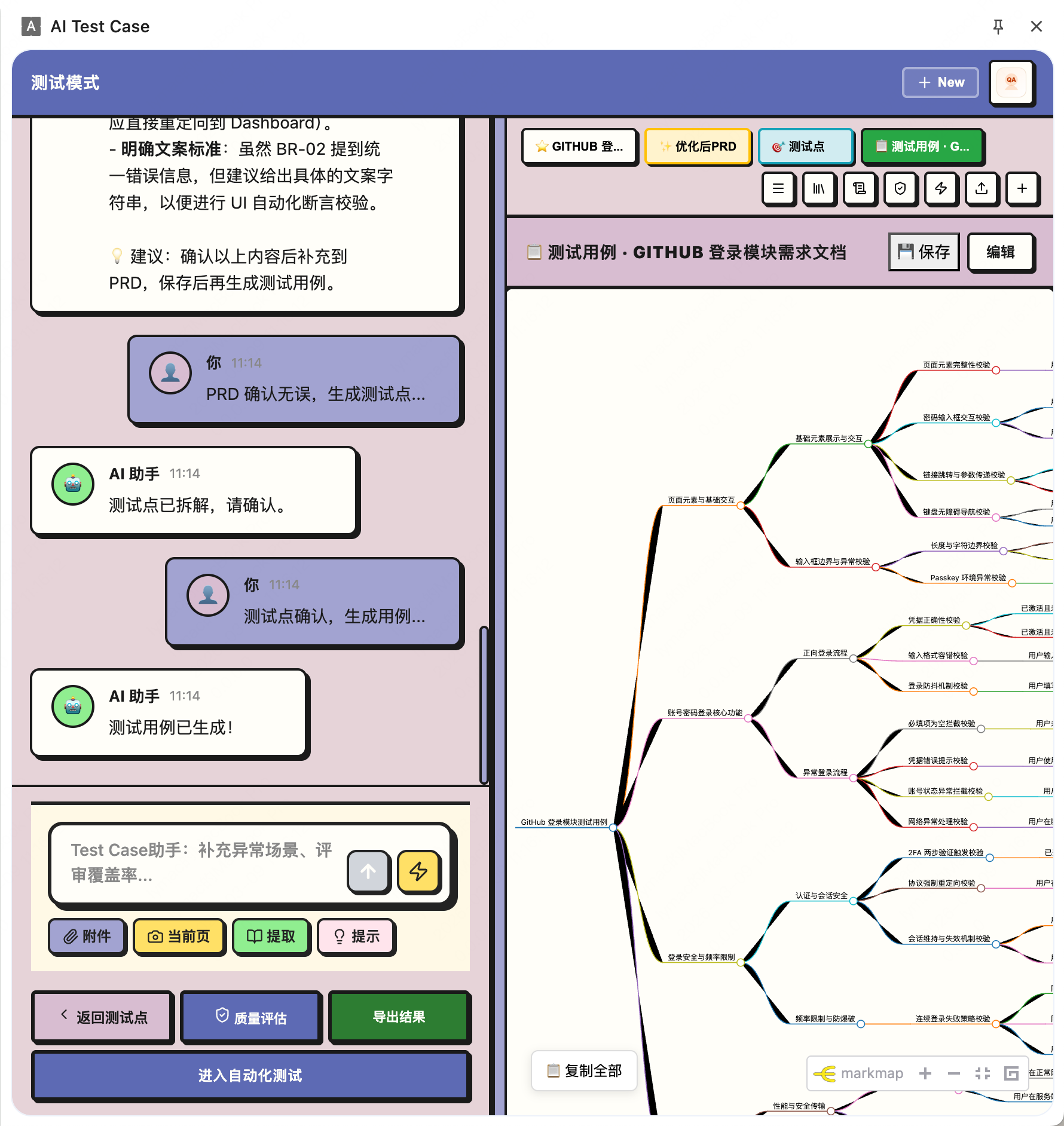
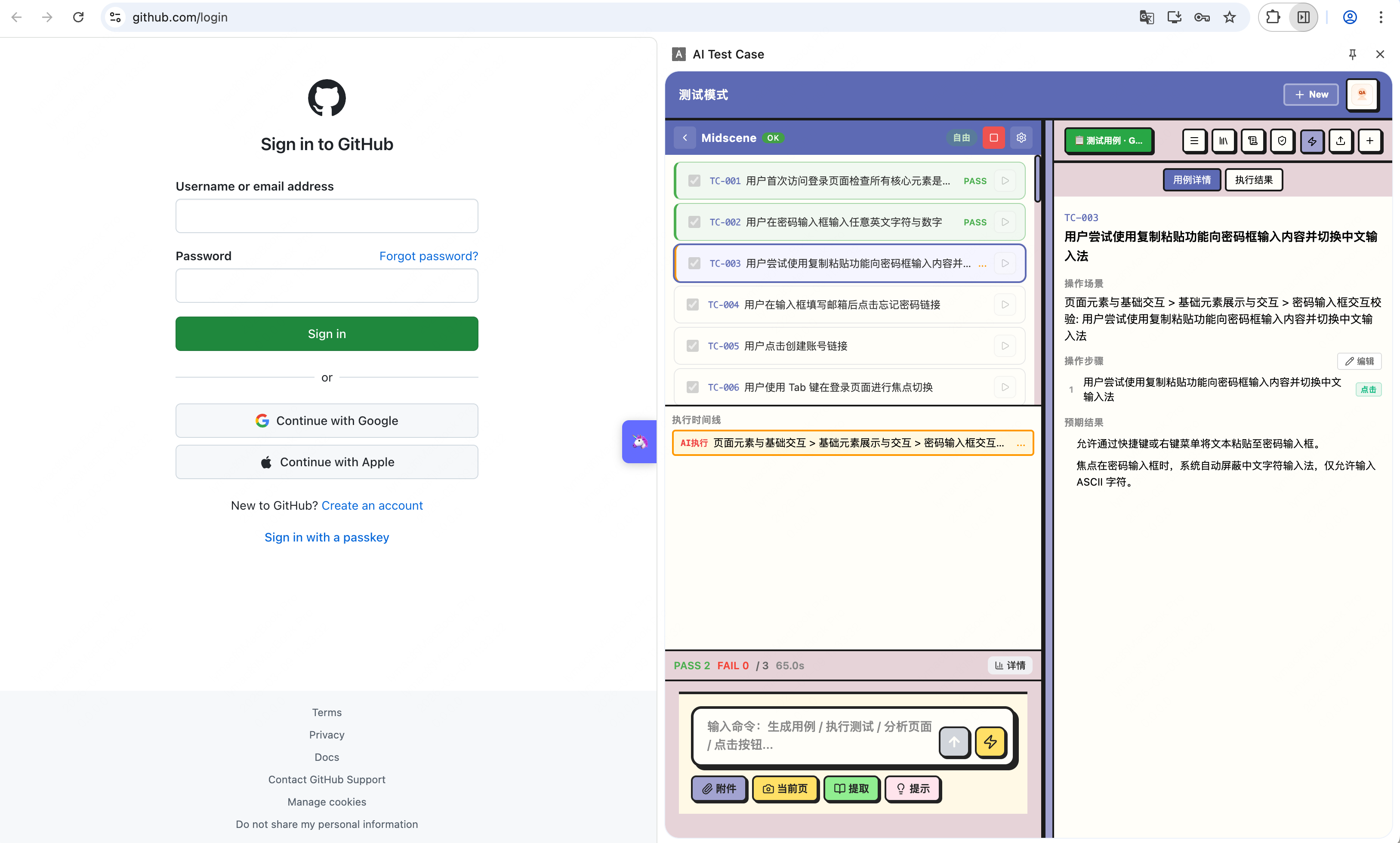
第 5 步:测试 — UI 自动化执行
- 这是我觉得最酷的部分! 🚀
- 生成的测试用例可以直接交给 AI 执行 UI 自动化
- 不需要写代码,AI 会自己理解步骤、定位元素、执行操作
- 实时看到执行进度、截图、日志
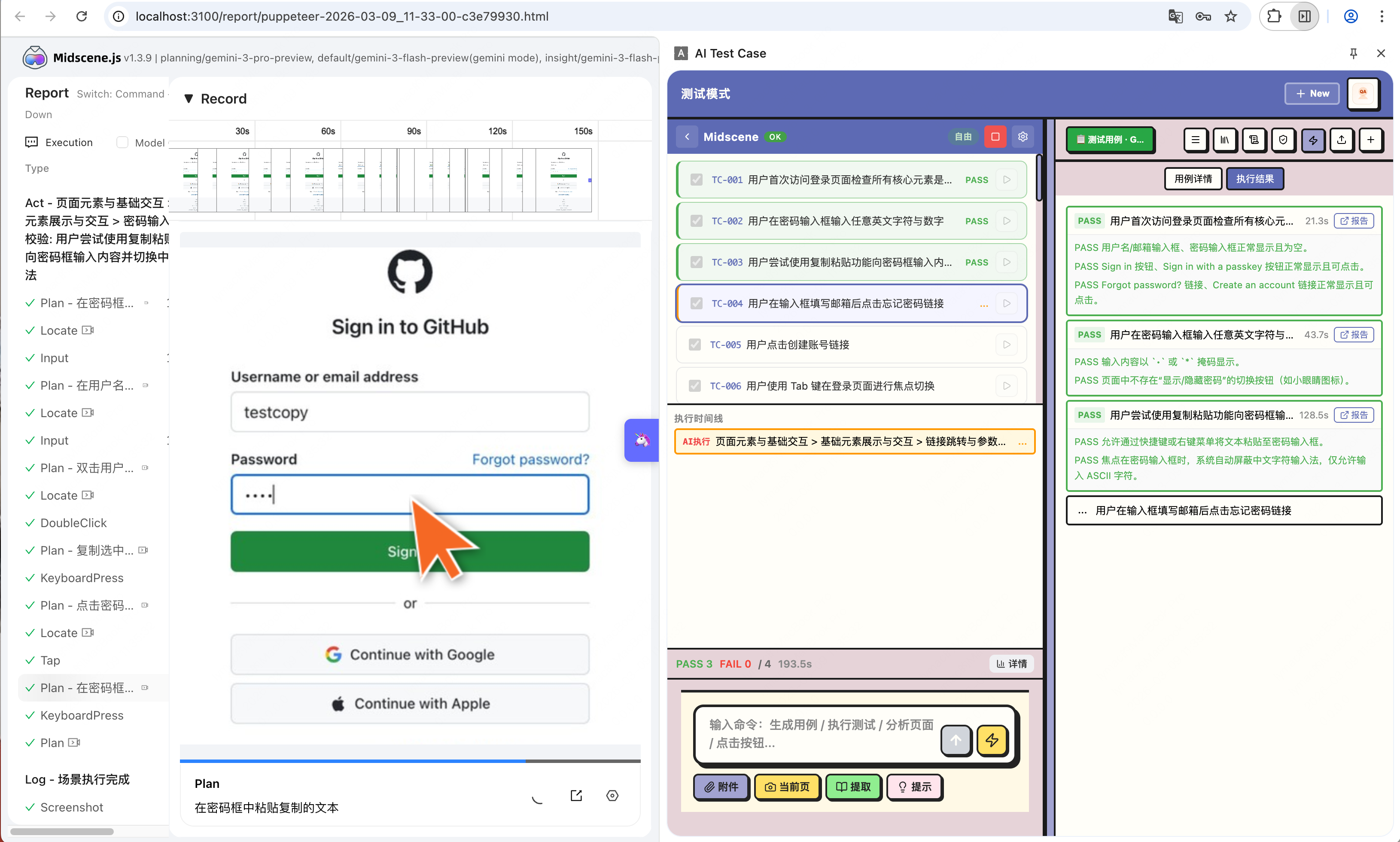
执行完成后,会生成测试报告:
🛠️ 技术实现
架构设计
整个项目分为三个服务:
| 服务 | 技术栈 | 端口 | 职责 |
|---|---|---|---|
| Agent Server | Python FastAPI + LangGraph | 8000 | AI 对话、测试用例生成、文档管理 |
| Midscene Sidecar | Node.js + Midscene SDK | 3000 | UI 自动化执行引擎 |
| Chrome Extension | Vue 3 + WXT | — | 浏览器插件前端 |
UI 自动化的核心:三种执行模式
这是我花时间最多的部分。为了平衡 准确性、速度 和 成本,我设计了三种执行模式:
| 模式 | 执行方式 | 适用场景 | AI 开销 |
|---|---|---|---|
| 自由模式 | AI 一次性规划整个流程 | 复杂的端到端测试 | 高 |
| 混合模式 | 逐步执行,三层降级策略 | 标准结构化用例 | 中 |
| 回归模式 | 回放保存的 YAML 基线 | 回归测试 | 零(不调用 AI) |
混合模式的三层降级策略是亮点:
- Layer 1: Instant — 正则匹配步骤意图,直接调用基础操作(点击、输入、滚动等),零 AI 开销
- Layer 2: aiAct — 如果正则匹配失败或操作失败,让 AI 理解步骤并执行
- Layer 3: deepThink — 如果还失败,启用 AI 深度思考模式,分析页面后再执行
这样既能保证成功率,又能降低 AI 调用成本。大多数标准操作("点击登录按钮"、"在邮箱输入框中输入 xxx")都能被 Layer 1 直接处理,不产生 AI 费用。
技术亮点
- LangGraph 智能体编排:使用 LangGraph 管理 AI Agent 的工作流,支持 PRD 分析、测试用例生成、质检评估等多个 Agent
- ChromaDB 向量检索:历史用例、知识库文档都存入向量数据库,支持语义搜索和 RAG 增强
- 三层缓存系统:LLM 响应缓存、Embedding 缓存、PDF 解析缓存,大幅降低重复调用成本
- Midscene SDK:基于视觉的元素定位,不依赖 CSS Selector,页面改版后也能工作
- SSE 流式输出:实时看到 AI 生成进度和测试执行进度
🎬 实际应用场景
场景 1:快速分析新需求
PM 发来一个需求文档 URL:
- 打开插件,输入 URL
- 点击"分析" → AI 自动提取内容
- 点击"PRD" → AI 生成结构化需求文档
- 点击"测试点" → AI 提取所有测试要点
原本需要 1-2 小时的需求分析工作,现在 5 分钟搞定。 我只需要审核 AI 的输出,补充遗漏的边界条件。
场景 2:批量生成回归用例
每次版本迭代,都要写一堆重复的登录、注册、密码重置的用例:
- 在"用例"步骤输入简单描述:"用户登录:邮箱密码登录,密码 8-16 位,失败 3 次锁定"
- AI 自动生成完整的测试用例(正常登录、错误密码、账号锁定等场景)
- 导出为表格格式,导入测试管理平台
场景 3:探索性测试 → 自动化回归
第一次测新功能时:
- 手动测试一遍,记录步骤
- 把步骤粘贴到插件,选择"自由模式"执行
- AI 理解步骤后自动执行,成功后自动保存为 YAML 基线
- 下次回归测试时,直接"回归模式"回放 YAML,零 AI 开销
📊 使用体验
优点
- 上手快:不需要写代码,会用 Chrome 扩展就能用
- 节省时间:用例编写效率提升 70%+(主观感受)
- 灵活性高:支持多种输入格式(URL、PDF、文字、图片),多种输出格式
- 自动化门槛低:不会写 Selenium 代码也能做 UI 自动化
局限性(坦白说)
- 依赖 AI 服务:需要自己配置 OpenAI/Claude API Key,有一定成本(我用的是第三方代理 API,成本还能接受)
- 复杂交互可能失败:拖拽、Canvas 操作、复杂表单等场景,AI 成功率不是 100%
- 中文环境优化:Prompt 主要针对中文优化,英文场景可能效果差一些
- 部署稍复杂:需要启动三个服务(Agent Server、Midscene Sidecar、Chrome Extension),对新手有点门槛
💬 希望听到你的声音
这个项目是我工作一年来对测试工作的一些思考和实践。功能也不够完善。
如果你对这个项目感兴趣,或者有任何需求、建议,欢迎:
- 在 GitHub 加个收藏
- 在本帖下方留言
- 有伙伴想要一起交流学习微信:19577301928
📝 快速开始
如果你想试试这个插件,按照以下步骤:
1. 环境要求
- Node.js >= 18
- Python >= 3.9
- Chrome >= 88
2. 克隆项目
git clone https://github.com/LiuYuan0115/AITestCase.git
cd AITestCase
3. 启动后端服务
cd agent-server
python3 -m venv venv && source venv/bin/activate
pip install -r requirements.txt
cp .env.example .env
# 编辑 .env 填入你的 OPENAI_API_KEY
python agent_server.py
4. 启动 UI 自动化引擎
cd agent-server/midscene-sidecar
npm install
npm run dev
5. 构建 Chrome 扩展
cd solvely-mvp
npm install
npm run dev
6. 安装扩展
- 打开 Chrome,访问
chrome://extensions/ - 开启「开发者模式」
- 点击「加载已解压的扩展程序」
- 选择
solvely-mvp/.output/chrome-mv3
详细文档见项目 README:https://github.com/LiuYuan0115/AITestCase/blob/main/README.md
结语
作为一个刚入行一年的测试,这个项目让我学到了很多:从 Python 后端到 Vue 前端,从 LangGraph 智能体到 Chrome 扩展开发。过程中踩了无数坑,但每次解决一个问题都很有成就感。
虽然项目还有很多不完善的地方,但我相信持续迭代能让它变得更好。希望能和 testerhome 的大家一起进步学习~
最后,感谢你看到这里!如果觉得这个项目有点意思,欢迎 Star ⭐️ 支持一下~
项目地址:https://github.com/LiuYuan0115/AITestCase
关键词:#AI 测试 # 测试用例生成 #UI 自动化 #Chrome 扩展 #LangGraph # 测试工具
