DEMO 工程下载
下周的公开直播要讲如何搭建一个 AI 驱动的 UI 自动化工程。 为了这个直播之前在星球里也写了一系列文章进行铺垫了。目前这个 DEMO 工程已经准备好, 放在星球上可下载。

如何使用这个 DEMO 工程
本 DEMO 工程的技术栈为:
| 类别 | 选型 | 作用 |
|---|---|---|
| 浏览器驱动 | Playwright | 启动 Chromium、操作页面、获取截图 |
| AI 定位引擎 | Midscene | 用自然语言驱动 AI 模型完成 UI 操作与断言 |
| 测试运行器 | Vitest | 组织 describe / test、并行/串行控制 |
| 报告工具 | Allure | 生成可视化测试报告(含失败截图) |
| 语言 | TypeScript | 强类型,更易维护 |
可用任何 IDE 打开本工程。 但由于本工程的亮点在于内置了一个 多 Agent 协同的 Skill 来完成 使用自然语言编写测试用例的实践方法。 所以强烈建议使用 AI 编程工具打开。 我本身是使用 codebuddy 来编写的, 所以 skill 存放在 .codebuddy 目录下。 如果大家是用 codebuddy 就不用迁移,实现无缝连接。 如果使用其他的 AI 工具。 需要让大模型帮你读取.codebuddy 目录下的 skill,然后要它根据你的 AI IDE 复刻一个出来。
注意:ui-automation 的 skill 是基于多个 Agent 协同的方法。 在复刻到自己的 AI IDE 的时候要注意让大模型创建 Agent, 有时候大模型复刻的时候会偷懒,把多 Agent 变成了单 Agent。
编写 case 一般使用如下方式:
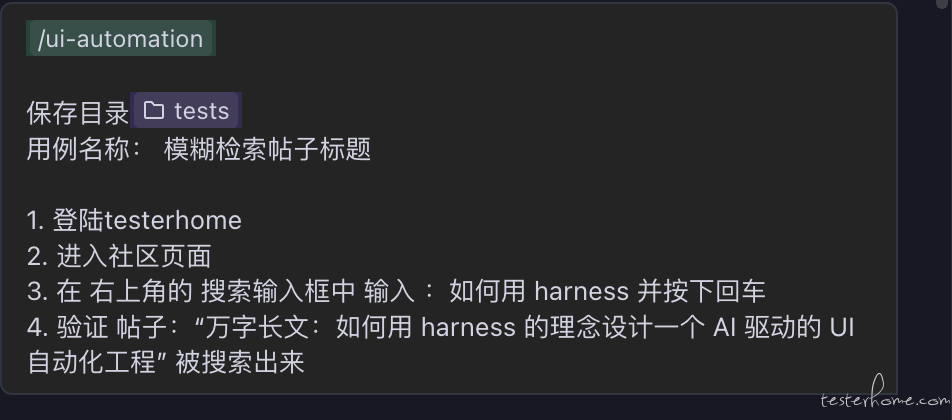
skill 中的 分析 agent 会读取你的需求, 分析代码复用情况等,输入一个报告:

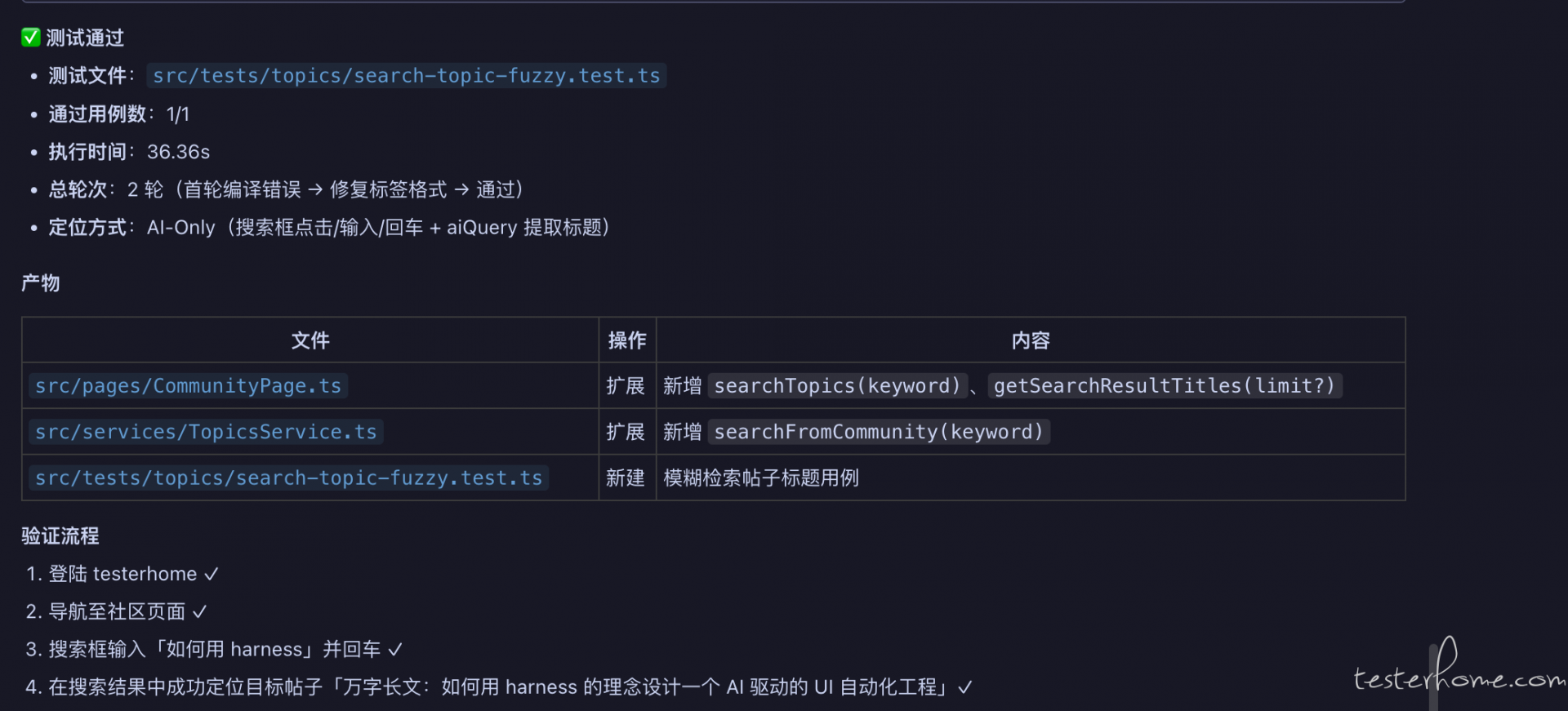
为了安全,分析 agent 分析后需要用户确认才会进入下一个阶段。 如果需要回复确认。 然后 AI 开始编写代码。 编写代码后会启动浏览器进行测试(流转到测试 Agent),当一切通过后,会产出结果报告:
注意:
- 为了保证稳定性, 目前我给 skill 下的指令是 AI 定位控件优先。也就是运行 case 定位控件的时候, 会动态截图,然后输出给工程配置的多模态大模型去识别控件坐标,然后再结合 DOM 树操控控件。 如果大家不喜欢 AI 定位控件优先, 可以修改 skill 指令,让编写 case 的 Agent 优先动态启动浏览器,探索控件的传统定位方式(css selector),然后用 AI 定位来进行兜底(如果传统定位失败, 就使用 AI 定位)。 这个口子我已经留下了
- 为了能在 case 运行的时候使用 AI 来定位控件,需要我们自己配置一个多模态大模型,我这里配置的是千问 VL3.5。 需要大家按 .env.example 文件中的格式进行填写。如下:
# ============================================================
# th-ui-playwright 环境变量示例
# 使用方式:复制本文件为 .env,并按需修改
# cp .env.example .env
# ============================================================
# ── Midscene AI 模型配置(必填) ─────────────────────────────
# 支持任何兼容 OpenAI API 协议的模型,如 GPT-4o、Claude、DeepSeek、
# 通义千问(DashScope 兼容模式)、智谱、火山方舟等。
# AI 模型 API 基础地址(OpenAI 兼容协议的 /v1 端点)
# 示例:
# OpenAI : https://api.openai.com/v1
# 阿里 DashScope: https://dashscope.aliyuncs.com/compatible-mode/v1
# DeepSeek : https://api.deepseek.com/v1
MIDSCENE_MODEL_BASE_URL=https://api.openai.com/v1
# AI 模型 API Key(绝对不要提交到 git!)
MIDSCENE_MODEL_API_KEY=sk-your-api-key-here
# 使用的模型名称
# 推荐:gpt-4o / qwen-vl-max-latest / doubao-vision-pro 等具备视觉能力的多模态模型
MIDSCENE_MODEL_NAME=gpt-4o
# 模型家族(可选,部分模型如 qwen3.5 需要显式指定,便于 Midscene 选择适配的 prompt 模板)
# MIDSCENE_MODEL_FAMILY=qwen3.5
# 是否启用模型推理模式(可选,默认 false;某些 reasoning 模型可设为 "true")
# MIDSCENE_MODEL_REASONING_ENABLED=false
# ── 被测网站配置(可选) ────────────────────────────────────
# 目标网站首页地址,默认 https://testerhome.com
# BASE_URL=https://testerhome.com
# 登录页地址,默认 ${BASE_URL}/account/sign_in
# LOGIN_URL=https://testerhome.com/account/sign_in
# ── 登录测试账号(可选) ────────────────────────────────────
# 用于 src/tests/auth/login.test.ts 和 `npm run auth` 半自动登录脚本
# 注意:请使用你自己的测试账号,不要提交真实凭据到 git
# TEST_USERNAME=your_username_or_email
# TEST_PASSWORD=your_password
# ── 运行模式(可选) ────────────────────────────────────────
# 设为 true 开启无头模式(不显示浏览器窗口,CI 环境推荐)
# HEADLESS=false
# 设为 true 开启调试日志
# DEBUG=false
- 还需要注意:原本还有一个 Agent 是用来自学习的,也就是编写 case 的时候就让大模型判断哪些方法可以提取成公共方法,然后写进知识库里,这样以后大模型编写新 case 的时候可以快速的进行查找。 但由于当前已经有好几个 Agent 了,再加一个 Agent 会进一步消耗 token,而自学习这个需求也不是很强烈。 所以我目前的方式是给大家留个口子。在 docs/plans/2026-05-12-ui-automation-curator-design.md 这个文档里记录了详细的计划,如果大家需要自学习能力,可以用大模型读取这个计划,按计划去执行改造 skill。
结尾
其余的如何安装环境依赖,如何编写 case 的细节等等, 大家都去看项目中的 readme 文件吧。 里面写的很详细。 如果想要这个 demo 工程的,欢迎加入星球下载。 不想加入星球的,也可以下周来我直播听听这个工程的设计思路。

如果觉得我的文章对您有用,请随意打赏。您的支持将鼓励我继续创作!