近两年,“AI 测试工程师” 这个词越来越常见,但很多测试人员一接触大模型应用,就会有一种明显的不适应:
以前测试的是一个相对确定的系统。按钮点击后会跳转到哪里,接口返回什么字段,输入某个值会出现什么结果,理论上都可以提前定义清楚。
但到了大模型应用这里,情况变了。
同一个问题,模型这次可能回答得很好,下次却可能答偏;改了一句 Prompt,效果可能提升,也可能让原本正常的场景退化;系统明明没有报错,页面也没有异常,可用户就是觉得 “不好用”。
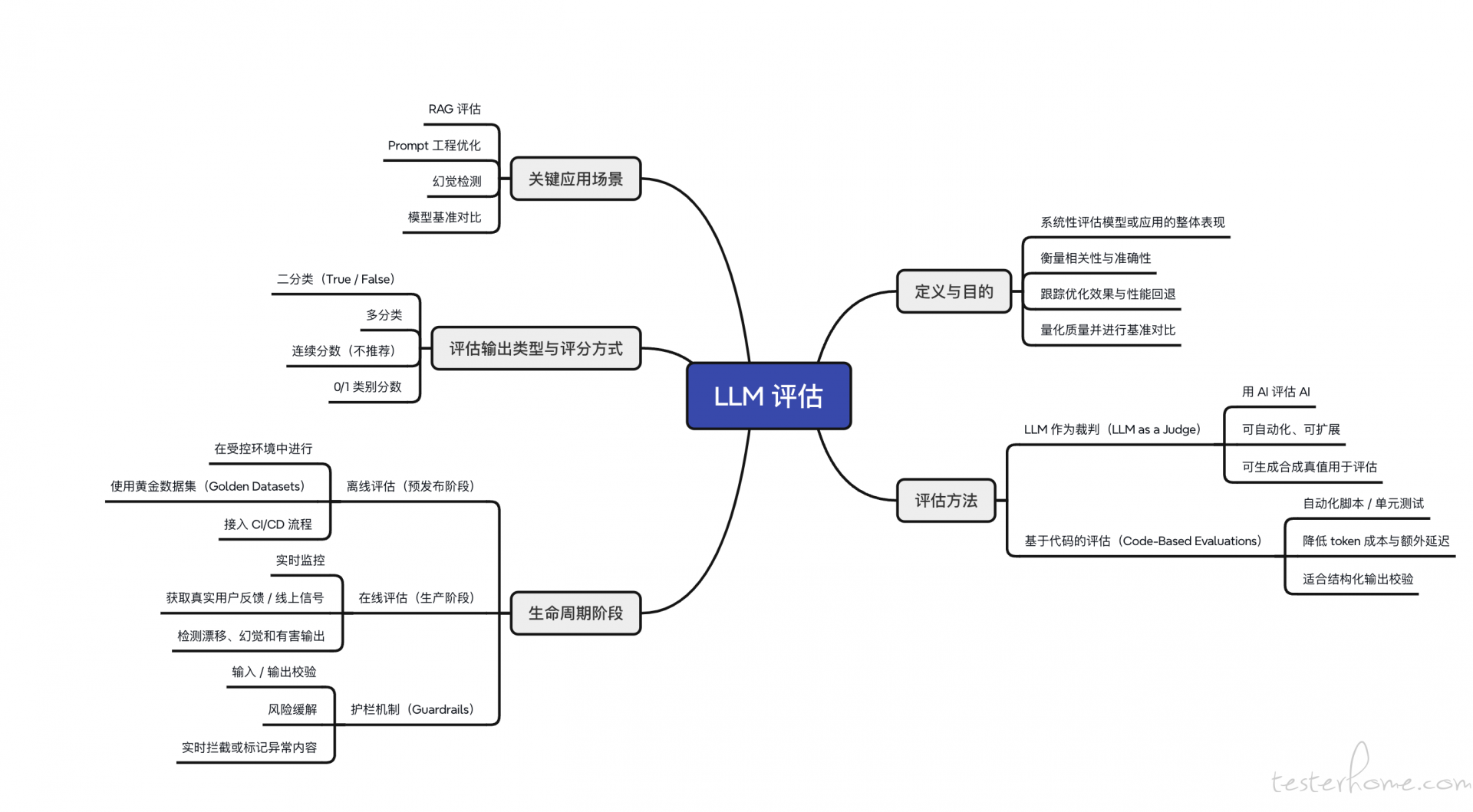
这说明,AI 时代的测试重点,已经不再只是 “功能是否正常”,而是 “输出是否可靠”。这也是 LLM 评估这类文章真正想解决的问题。
一、为什么传统测试方法到了大模型这里不够用了
传统软件测试的核心,是验证系统行为是否符合预期。
核心验证内容
- 接口返回码是不是 200
- 页面元素是否正常展示
- 订单提交流程是否闭环
- 字段格式是否正确
- 异常场景有没有正确报错 这些都没有错,而且在 AI 应用里依然需要。 ### AI 应用中的新问题 即使系统接口和页面没有问题,AI 问答系统仍可能出现:
- 回答和用户问题不相关
- 表达流畅但内容是编造的
- 这次回答正确,下次同类问题却出错
- 对边界输入、模糊问题理解很差
- 遇到对抗式输入时输出不安全内容 结论:传统测试关注 “系统能不能运行”,LLM 测试还要关注 “系统答得好不好”。这是一个本质性的思维变化。
二、测试对象变了:从 “功能正确” 变成 “输出质量”
LLM 评估的本质是:系统性衡量一个 AI 应用输出质量的过程。
过去:验证 “有没有错”,现在:验证 “是不是好”。
输出质量的核心维度
- 相关性:回答是否围绕用户问题
- 正确性:内容是否基本准确
- 幻觉率:是否编造事实、引用不存在的信息
- 完整性:是否遗漏关键点
- 安全性:是否有违规/危险输出
- 一致性:同类问题下表现是否稳定
- 延迟:响应是否及时
三、只靠传统断言,已经测不准大模型应用了
常见误区:继续写自动化断言就能完成 AI 测试。
答案是: 可以,但只能覆盖一部分。
1. 代码式评估:AI 时代的 “传统自动化测试”
适用于确定性强的输出:
- 输出是否合法 JSON
- 是否包含指定字段
- 字段类型是否正确
- 是否命中关键词
- 是否遵守特定格式
- 工具调用结果是否符合预期 优点:快、成本低、稳定、适合持续回归 问题:很多大模型问题无法规则判断,例如:
- 回答有没有真正理解用户意图
- 总结是否忠于原文
- RAG 回答是否基于检索内容
- 回答是否 “虽然没错,但没用”
四、为什么现在会出现 “用 LLM 来评估 LLM”
核心方法:LLM-as-a-Judge
让另一个模型评估当前模型输出:
- 是否相关
- 是否存在明显幻觉
- 是否完成任务目标
- 是否有帮助
- 是否忠于参考资料 对应测试体系:
- 代码断言:检查确定性规则
- LLM Judge:检查主观质量
- 人工评审:最终校准标准 流程:
- LLM Judge 批量筛选
- 高风险/低分/异常样本
- 人工重点复核 本质:把原本只能人工判断的质量问题,尽量自动化。
五、测试数据集,会成为 AI 测试最核心的资产之一
传统测试强调测试用例设计,到了大模型测试阶段,更重要。
Eval Dataset ≈ 大模型应用的测试用例库
好的评估集应覆盖:
- 正常场景
- 高频场景
- 边界场景
- 模糊表达场景
- 对抗场景
- 高风险场景
- 历史故障场景 对比: 传统测试:
- 输入
- 操作步骤
- 预期结果 LLM 测试:
- 用户问题
- 上下文信息
- 参考答案或评价标准
- 风险标签
- 通过/失败判定条件 核心能力:设计高质量、贴近真实业务的评估集。
六、Prompt、模型、RAG 变更,本质上都应该跑回归测试
常见误区:
- 改 Prompt → 人工试 → 上线
- 换模型 → 看起来不错 → 发布
- 改检索逻辑 → 简单抽查 → 上线 每次变更可能影响:
- Prompt → 旧场景退化
- 模型 → 风格与稳定性变化
- RAG → 幻觉增加
- 工具链 → 成功率下降 意识:Prompt、模型、RAG 变更属于 “发版变更”,必须跑评估。 结论:AI 应用同样需要 CI/CD 思想。
七、AI 应用上线后,监控的不只是 “有没有报错”
传统线上监控指标:
- 错误率
- 超时率
- 成功率
- 崩溃率
- CPU / 内存 / 服务状态 对 LLM 应用还要关注:
- 幻觉增加
- 回答偏离用户问题
- 知识库引用不准确
- 不安全内容输出
- 回答虽流畅但任务完成率下降 解决方案:实时 Guardrails(护栏)
- 拦截敏感输出
- 阻断不安全内容
- 识别幻觉
- 对高风险场景降级处理 延伸职责:
- 评估规则设计
- 风险场景识别
- 线上质量监控指标定义
- 护栏策略验证
八、测试人员如何理解 “AI 测试工程师” 的能力升级
未来测试人员不仅验证功能,还要参与定义和保障 AI 输出质量。
能力升级方向
- 从功能验证,升级到质量评估:关注回答相关性、正确性、稳定性、安全性
- 从脚本编写,升级到评估设计:会设计评估维度、标准和数据集
- 从确定性断言,升级到混合评估:规则断言 + LLM Judge + 人工复核
- 从测试执行,升级到持续回归:Prompt、模型、RAG 变更纳入流水线
- 从线下验证,升级到线上质量治理:关注生产环境中的幻觉、不安全内容、任务退化
本文主要内容源自 “What is LLM Evaluation?“一文, 文章链接: https://arize.com/llm-evaluation/?utm_source=chatgpt.com
「原创声明:保留所有权利,禁止转载」
暂无回复。