AI测试 Cursor 推出 Composer 1.5:强化学习规模扩大 20 倍,AI 编码助手迈入新阶段
2026年2月9日, AI 编程工具开发商 Cursor 正式发布其旗舰编码模型 Composer 1.5。该版本在保持快速响应的同时显著提升了智能水平,尤其在处理复杂真实世界编码任务时表现出色,被视为当前 AI 编码助手领域的重要进步。
强化学习规模扩大 20 倍
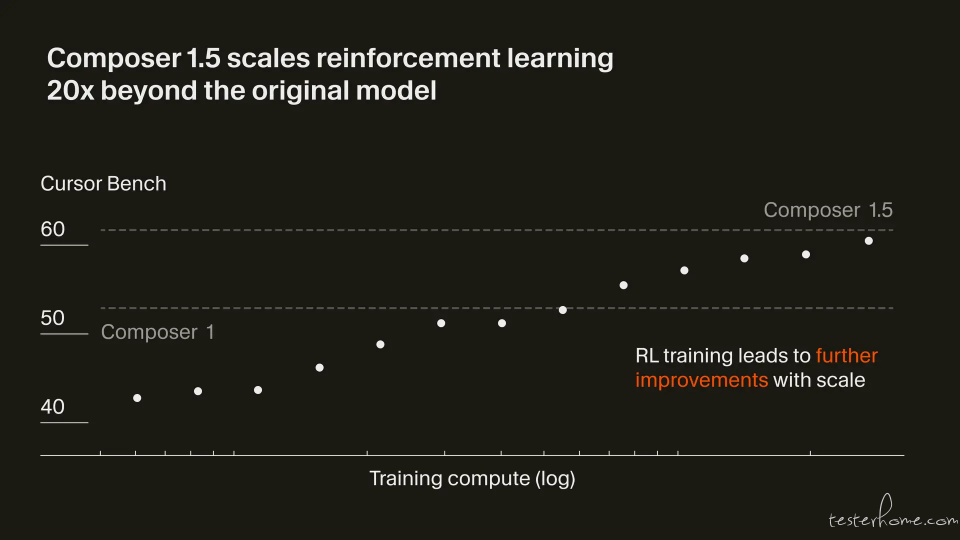
Composer 1.5 基于与前代相同的预训练基础模型,但后训练阶段的强化学习(RL)规模扩大了 20 倍。
据 Cursor 团队透露,本次后训练所投入的算力甚至超过了预训练阶段的总算力。这一举措带来了明显的性能跃升:在针对真实世界编码问题的内部基准测试中,Composer 1.5 迅速超越了去年发布的 Composer 1,并在持续训练中保持性能稳步提升,尤其在高难度任务上改进最为显著。
新版本的最大亮点在于 “思考型” 设计。模型会在响应过程中生成专属的 “思考 token”,用于深度推理代码库并规划后续步骤。为了兼顾日常使用的流畅性,Composer 1.5 被训练为在简单问题上以最少思考快速作答,而在复杂问题上则会持续思考直至得出满意答案。此外,模型还具备自我总结能力:当上下文窗口耗尽时,可自动生成有用总结并继续探索解决方案。这一能力在训练中被深度强化,甚至支持递归多次总结,从而在上下文长度受限时仍保持较高准确率。
Cursor 团队表示,Composer 1.5 相比前代是一个 “显著更强的模型”,推荐用户在交互式编码场景中优先选用。其训练过程也进一步验证了面向编码任务的强化学习具备高度可扩展性:只要持续扩大规模,就能在智能水平上获得可预期的回报。
在当前 AI 编程助手竞争日趋白热化的背景下,Composer 1.5 的发布具有标杆意义。过去一年,GitHub Copilot、Amazon CodeWhisperer、Tabnine 等主流产品均在模型能力、上下文长度和工具集成上加速迭代,而开源社区的 DeepSeek-Coder、StarCoder2 等模型也在快速追赶。Cursor 通过大幅增加强化学习投入,成功在 “速度与深度思考” 的平衡上找到新突破点,有望进一步巩固其在专业开发者群体中的领先地位。
Composer 1.5 与其他同类产品的比较
Composer 1.5 是 Cursor 于 2 月 9 日刚刚发布的编码模型,距离现在仅一两天,因此外部独立基准测试和用户大规模反馈还非常有限。目前主要信息来自 Cursor 官方内部基准,以及少量早期用户讨论。
我们基于 Cursor 官方声明、行业基准(如 SWE-Bench)和 2026 年初的整体同类 AI 编码助手进行客观比较。
同类产品主要包括:

Composer 1.5 的优势
编码特定强化学习深度优化 -- Composer 1.5 在同一预训练基础上,将强化学习规模扩大 20 倍,后训练算力甚至超过预训练。这让它在真实世界复杂编码任务上表现突出(官方内部基准显示显著超越前代 Composer 1,尤其高难度任务)。相比通用模型(如 Claude Opus 或 GPT-5),它更专注于编码场景,避免了 “泛化过度” 导致的非必要冗长。
代理能力与思考机制 -- 具备 “思考型” 设计(生成 thinking tokens 进行深度推理和规划),以及自我总结能力(上下文耗尽时自动总结并继续)。这在长上下文、迭代式、多文件修改等代理任务中优势明显,适合全流程开发(从规划到调试)。类似 Windsurf SWE-1.5 也有代理能力,但早期比较显示 Composer 在稳定性上更胜一筹。
速度与智能平衡 -- 简单任务快速响应,复杂任务深度思考。官方称这在交互式编码(如 Cursor IDE 中的 Composer 模式)中体验最佳,许多用户反馈它在实际项目中 “更可靠、一致”。
专为开发者交互优化 -- 深度集成 Cursor IDE,支持代码库全局推理,适合专业开发者日常使用。
Composer 1.5 的差距
缺乏独立公开基准验证 -- 目前 SWE-Bench Verified 排行榜(2026 年 2 月数据)领先的是 Claude Opus 4.5/4.6(约 80-81%)和 GPT-5.2(80%),Composer 1.5 尚未出现在主流榜单。官方只提供内部基准,社区反馈也指出 “没有广泛接受的标准比较”。这意味着其宣称的 “显著更强” 仍需第三方验证。
成本与可用性 -- 早期用户提到定价高于 GPT-5.3 Codex 等竞品,且必须在 Cursor 订阅体系内使用(无法像 Claude/GPT 那样灵活切换到其他平台)。相比 GitHub Copilot(更普及、价格亲民)或免费/开源选项,门槛较高。
通用性与简单任务速度 -- 虽然平衡了速度,但思考机制可能让简单补全任务稍慢于纯快速模型(如 GPT-4o/GPT-5 nano)。在非代理场景下,直接使用 Claude Opus 4.x 或 GPT-5 可能更高效(这些模型在纯编码基准上已非常成熟)。
生态锁定 -- 高度依赖 Cursor IDE,无法像 Copilot 那样无缝集成 VS Code 等主流编辑器。部分开发者更偏好多平台支持的工具。
不是绝对最强,但它可能是代理式编码场景下的顶级选手之一
在 2026 年初的行业评测中,公认编码最强的仍是 Claude Opus 4.x 系列(SWE-Bench 最高分、推理最强)和 GPT-5 系列(速度与准确平衡最佳)。Cursor 本身在 “最佳 AI 编码助手” 榜单中常位列前三,但主要是因为 IDE 体验,而非模型本身碾压。
Composer 1.5 的潜力很大(官方强调可预期持续提升),尤其适合需要深度代理的复杂项目。但由于刚发布,短期内还无法取代 Claude Opus/GPT-5 的领先地位。未来若有独立基准上榜(如 SWE-Bench 突破 80%+),才可能挑战 “最强” 宝座。
总体建议:如果你主要用 Cursor IDE 做大型项目,优先试用 Composer 1.5(官方强烈推荐);如果追求基准验证的稳定性或跨平台,Claude Opus 4.x 或 GPT-5 仍是更稳妥的选择。随着时间推移,预计会有更多真实用户对比出现。
- TesterHome 社区公众号首发,原文链接:https://mp.weixin.qq.com/s/nRsPhrhHRj9DzU32NA3Euw