以下内容均在Ubuntu 24.04 LTS运行成功过
还未正式落地,只是 demo,主要参考洞窝那篇文章
主要参考文章:
1 dify 安装及其相关
1.1 dify 安装
- docker 安装参照 2 docker 的安装 (centos7.9 为例)
- dify 安装参考 dify 官网dify 官网下载他的发行版并解压, 安装命令
cd dify
cd docker
cp .env.example .env
docker compose up -d
1.2 当 dify 的端口被占用时
- 部署时启动
docker compose up -d提示 nginx 的 443 端口被占用,修改相应端口
cat .env
修改下列端口即可
NGINX_SSL_PORT
EXPOSE_NGINX_SSL_PORT
EXPOSE_NGINX_PORT这个是网址的端口号默认 80,若是改了就需要加上端口号,如改为了9999则需要访问http://192.168.110.232:9999/
1.3 注册 dify 时报错(os error 13)

解决办法:
chmod 777 dify/docker/volumes/app/storage
1.3 dify 追踪
输入一个问题,答案如何从知识库被检索出来,如何传给大模型,如何得到的答案
1 可以查看工作室相应日志 路径如下图所示
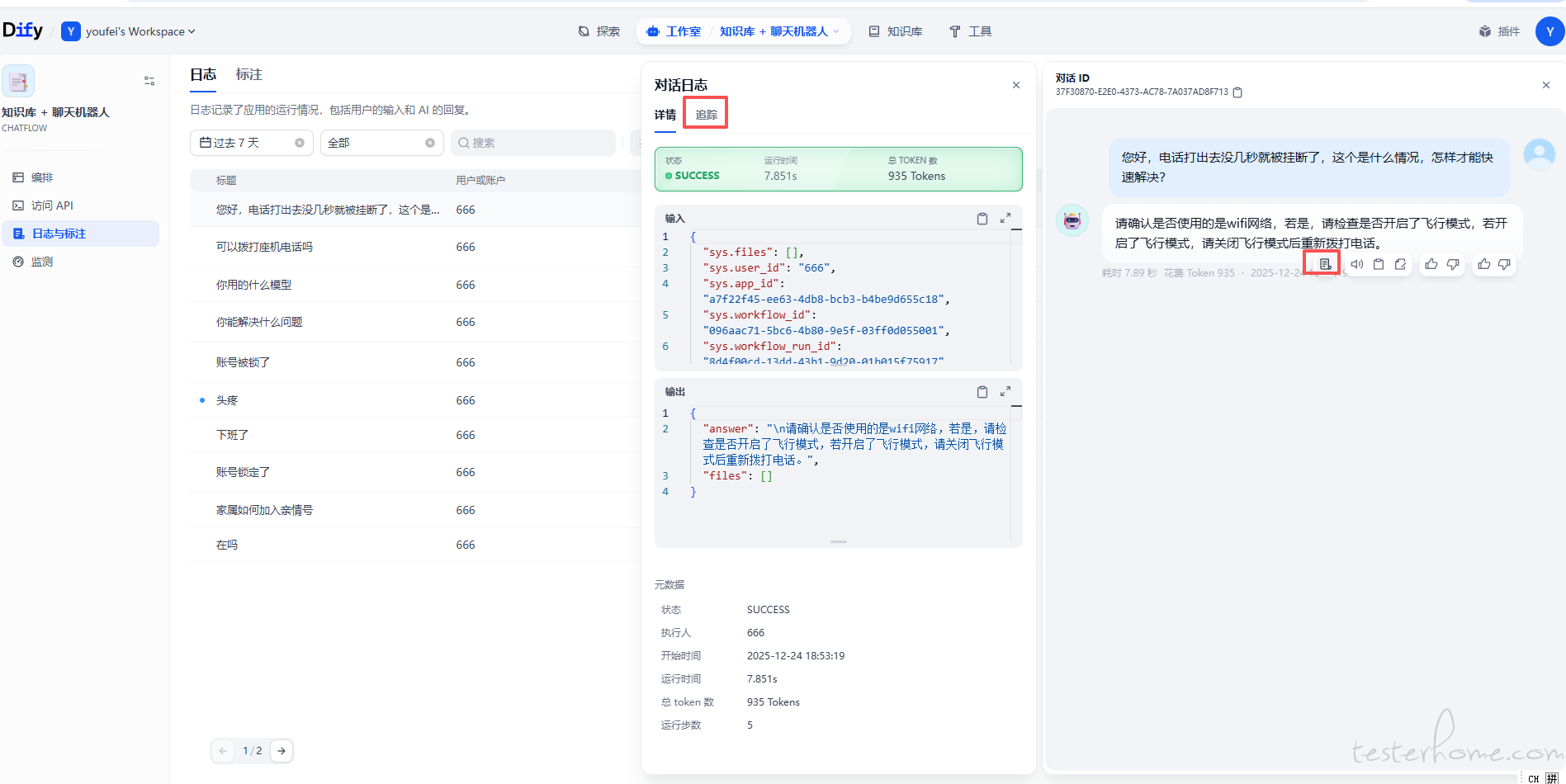
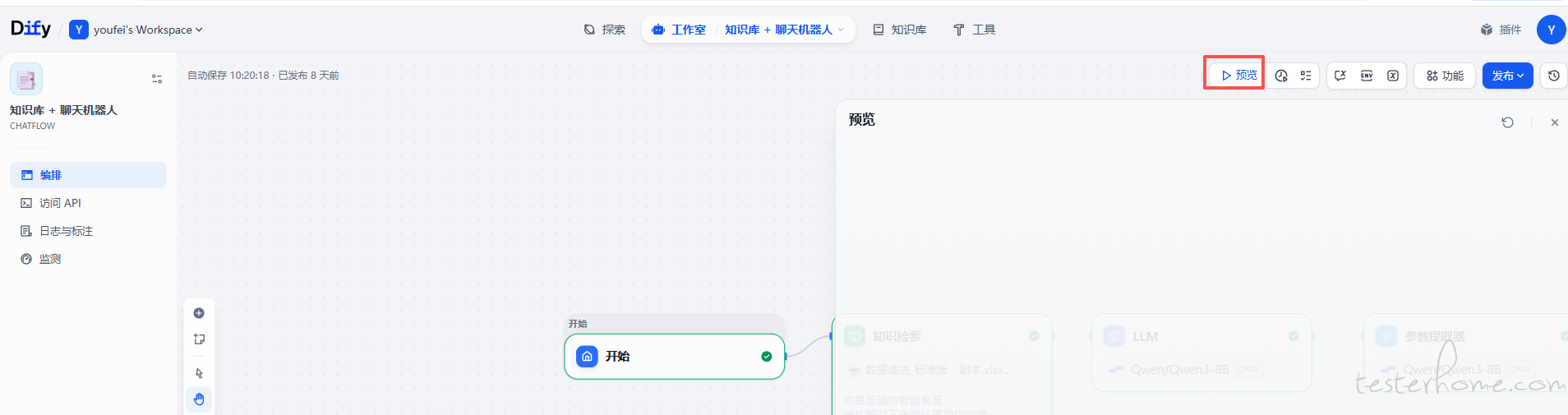
2 可以在工作室编排页面点击预览后在右侧输入答案,运行完成后也可以查看日志
1.4 dify 元数据
1.5 dify 标注
标准化业务问答:如公司的报销政策、特定产品价格等需要 100% 准确的问题
一旦启用 (默认是关闭状态) 并创建了标注,系统处理用户输入的逻辑如下:
语义搜索:用户提出问题后,系统首先在标注库中搜索语义相似的问题。
匹配判断:
命中:如果找到分值超过相似度阈值的匹配项,则直接返回标注中的答案,不再消耗 Token 调用大模型或检索知识库。
未命中:如果未找到匹配项,则进入常规的 AI 生成或 RAG(知识库检索)流程。

2 模型
2.1 模型平台模型
-
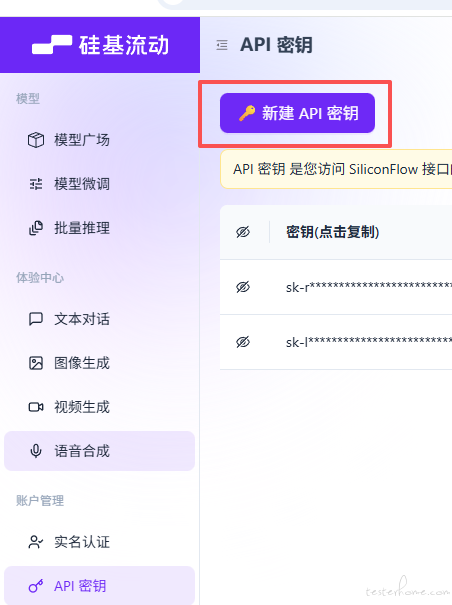
以 “硅基流动” 模型平台为例 ,访问硅基流动官网地址 生成一个密钥
- 在 dify 上 右上角 -- 设置 -- 模型供应商下载,配置在第二部拿到的密钥
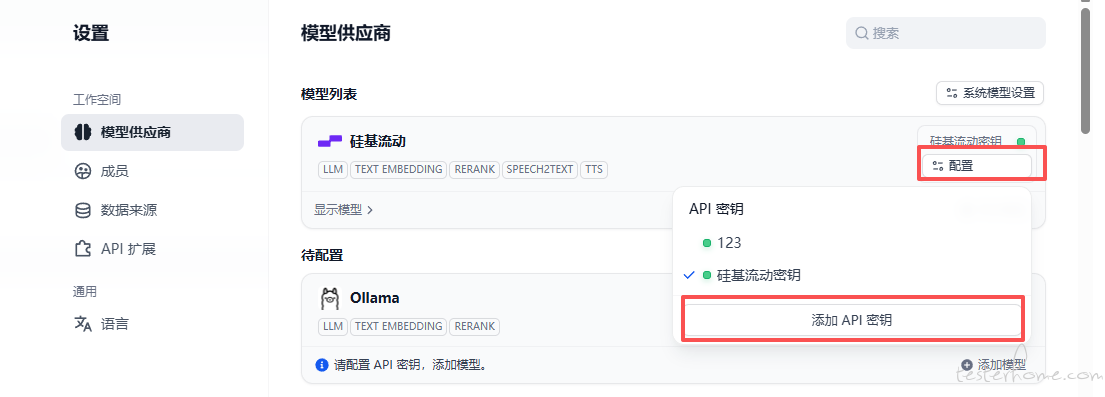
- 配置之后就可以使用硅基流动平台的模型了 注意:尽量使用免费的模型,大多模型需要收费,免费模型有 “免费字样”
- 在 dify 上 右上角 -- 设置 -- 模型供应商下载,配置在第二部拿到的密钥
2.2 手动安装模型
2.2.1 ollama 下载
ollama 用于运行和管理大模型
2.2.1 linux
linux 参考第四步
ollama 的 github 官网
2.2.2 windows
注意:要把 ollama 放在/usr/local/bin下,解压后ollama 可以在/bin下
2.2.3 ollama 服务启动(gemini3 编写 验证有效)
✅ 解决方案:手动创建 Systemd 服务文件
步骤一:创建 Ollama 用户和组(安全与规范)
为了让 Ollama 以非 root 用户的身份安全运行,我们需要创建专门的用户和组。
sudo useradd -r -s /bin/false -U -m -d /usr/share/ollama ollama
sudo usermod -a -G ollama $(whoami)
-
说明:
- 创建了一个名为
ollama的系统用户 (-r),禁止登录 shell (/bin/false)。 - 将您当前的用户名 (
$(whoami)) 加入到ollama组中,以便您有权限管理模型。
- 创建了一个名为
步骤二:创建 Systemd 服务配置文件
使用 nano 或 vi 等编辑器创建服务文件:
sudo vim /etc/systemd/system/ollama.service
将以下内容粘贴到文件中:
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
# Ollama 可执行文件的路径,根据您之前移动的位置 (/usr/local/bin) 配置
ExecStart=/usr/local/bin/ollama serve
Environment="OLLAMA_HOST=0.0.0.0:11434"
User=ollama
Group=ollama
Restart=always
RestartSec=3
[Install]
WantedBy=multi-user.target
-
注意:
ExecStart路径必须是您之前移动 Ollama 二进制文件的位置,即/usr/local/bin/ollama serve。
步骤三:重载 Systemd 配置并启动服务
保存并退出文件后,执行以下命令使配置生效,然后启动 Ollama 服务:
sudo systemctl daemon-reload # 重载 systemd 配置
sudo systemctl enable ollama # 设置开机自启动(推荐)
sudo systemctl start ollama # 启动服务
步骤四:验证状态
现在,再次运行状态检查命令:
sudo systemctl status ollama
您应该能看到类似 Active: active (running) 的输出,表明 Ollama 服务已成功启动。
2.3 嵌入模型 bge-m3
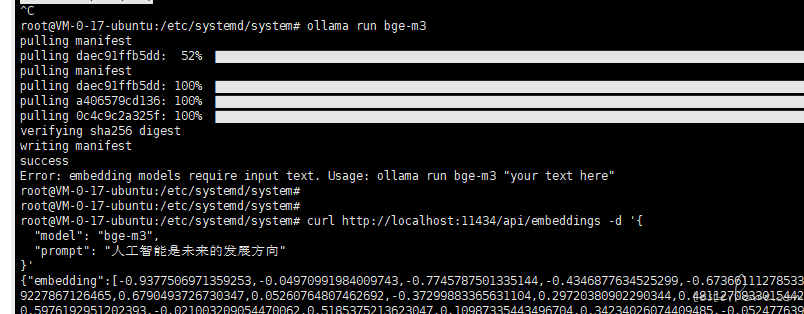
- 运行命令
ollama run bge-m3
- 检查是否生效,返回向量即生效
curl http://localhost:11434/api/embeddings -d '{
"model": "bge-m3",
"prompt": "人工智能是未来的发展方向"
}'
2.4 重排序模型 bge-reranker-v2-m3
- ollama 暂不支持 reranker 模型的 api/rerank,暂时使用硅基流动的模型
bash ollama run qllama/bge-reranker-v2-m3--- 下面是使用 xinference 安装模型
- 安装必要依赖: ```bash sudo apt update sudo apt install python3-pip python3-venv -y
2. **创建并激活虚拟环境**:
```bash
cd /home/ubuntu
python3 -m venv xinf_env
source xinf_env/bin/activate
-
安装 Xinference:
bash pip install --upgrade pip pip install "xinference[all]"
4.配置 Systemd 系统服务:
为了保证 Xinference 在后台持续运行并在重启后自动启动,需将其配置为系统服务。
4.1. 创建服务文件:sudo vim /etc/systemd/system/xinference.service
4.2. 写入以下配置(已加入国内 ModelScope 加速环境变量):
[Unit]
Description=Xinference Service
After=network.target
[Service]
Type=simple
User=root
# 核心环境变量:强制使用 ModelScope 国内镜像加速下载
Environment="XINFERENCE_MODEL_SRC=modelscope"
ExecStart=/home/ubuntu/xinf_env/bin/xinference-local -H 0.0.0.0 -p 9997
WorkingDirectory=/home/ubuntu
Restart=always
RestartSec=3
[Install]
WantedBy=multi-user.target
4.3. 启动服务:
sudo systemctl daemon-reload
sudo systemctl enable xinference
sudo systemctl start xinference
- 加载 Reranker 模型
启动 Xinference 引擎后,需要手动 “指令” 它加载具体的重排序模型。
5.1. 执行 Launch 命令(需指定 endpoint 以连接正在运行的服务):
source /home/ubuntu/xinf_env/bin/activate
xinference launch \
--endpoint http://127.0.0.1:9997 \
--model-name bge-reranker-v2-m3 \
--model-type rerank \
--model-uid bge-reranker-v2-m3
5.2. 验证模型状态:
xinference list --endpoint http://127.0.0.1:9997
-
Dify 接入配置
在 Dify 的 “设置 -> 模型供应商 ->
Xorbits Inference” 中添加模型 -
模型类型:
Rerank -
模型名称:
bge-reranker-v2-m3 -
服务器 URL:
http://你的服务器公网或内网IP:9997
* 模型 UID:bge-reranker-v2-m3
7.安全加固
由于 Ollama 和 Xinference 默认不带身份验证,直接暴露公网会导致 GPU 被盗用,使用内网访问。
配置 UFW 防火墙白名单:
- 以 9997 接口为例
# 1. 默认拒绝所有公网访问 9997 端口
sudo ufw deny 9997/tcp
# 2. 仅允许 Dify 服务器 IP 访问 (假设 Dify IP 为 1.2.3.4)
sudo ufw allow from 1.2.3.4 to any port 9997 proto tcp
# 3. 如果 Dify 在本机 Docker 内,允许 Docker 网桥访问
sudo ufw allow from 172.17.0.1 to any port 9997 proto tcp
查看服务日志:sudo journalctl -u xinference -f
查看已加载模型:xinference list --endpoint http://127.0.0.1:9997
重启 Xinference:sudo systemctl restart xinference
2.5 向量数据库 Weaviate
安装 dify 自动安装的向量数据库
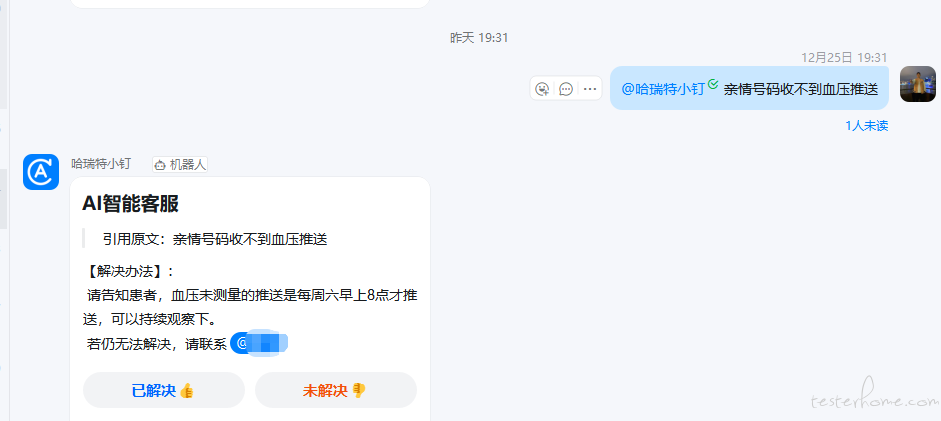
3 结合钉钉
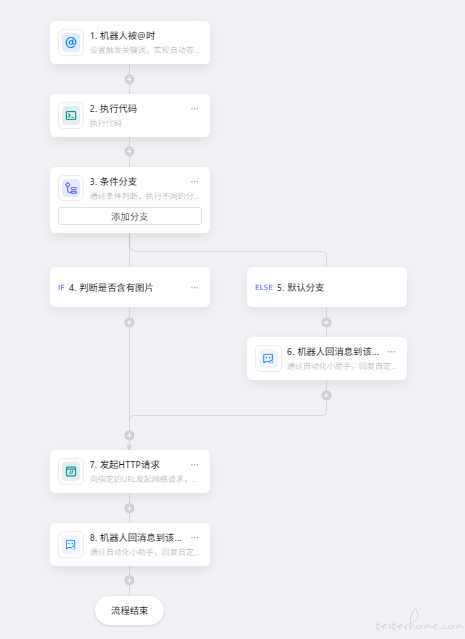
- 效果如下
- 自动化助手流程如下