一、获取 Gatling
官网下载即可。

目录结构如图。简单来说:
bin: gatling 也就两种组件 - 录制的组件和运行的组件;这个目录里面有两种脚本,一个是运行 recorder 的,也就是录制组件启动脚本;一个是运行组件的启动脚本;
conf: 放配置文件的目录。一般情况下你想要修改一些运行参数,都可来这里搞定;
lib: 里面是一些 jar 包,gatling 的运作全靠他们了;我们仅作为使用者暂时不必去理会;
results: 测试报告目录;
target: 你启动运行组件后,gatling 会为你编译好所有的.scala 脚本,而编译后的 class 文件就会在这里;
user-files: 存放你录制后的.scala 脚本;
总的来说,用 gatling 做一次简单的测试步骤如下(忽略细节):

- 在 bin 里打开 recorder.bat(GUI)
- 录制 3.在 user-files 里针对刚录制好的.scala 文件作你想要的修改
- 在 bin 里打开 gatling.bat(控制台)
- 选择你要运行哪一个脚本,并运行 6.运行完成后,在 results 目录下查看结果
二、简单实践
1.打开 recorder
刚拿到这个工具,你肯定不会想要自己去写一个脚本,起码先录制看一下脚本是啥样。所以打开了 recorder
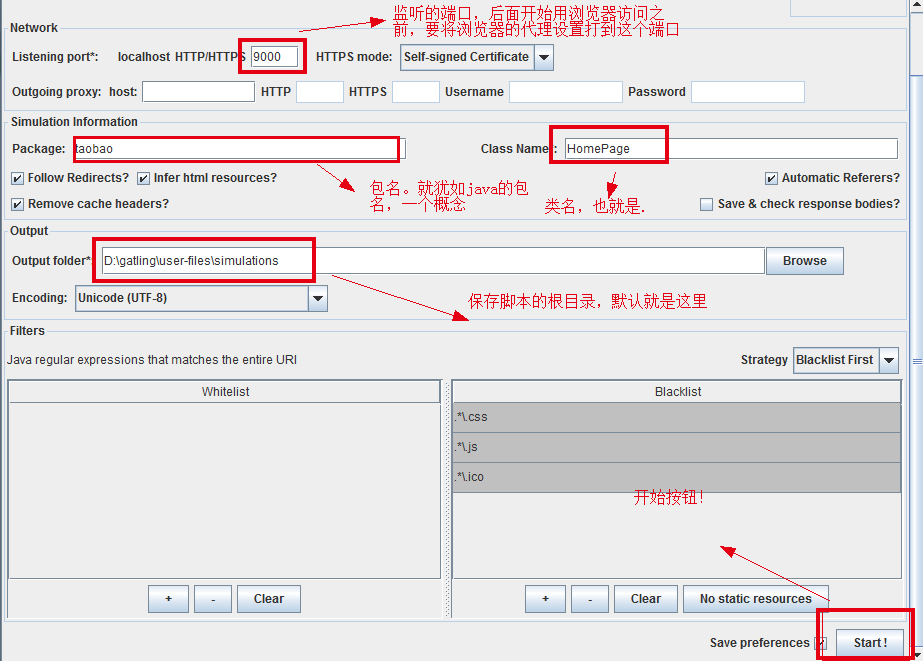
第一次实践过程中,除了上面图片中标出的这些,其他都暂时不用管。
2. 设置一下浏览器代理
打开你的浏览器。这里我用 FF。在 FF 的高级网络设置中,配置 “FireFox 如何连接至国际互联网"。
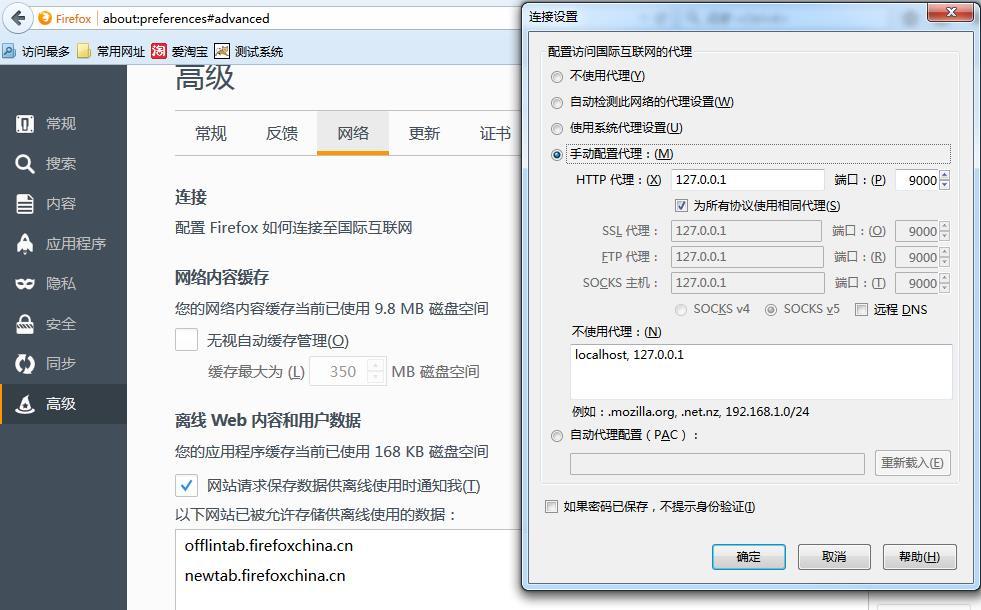
按照这样配置下就行了,因为 recorder 只会监听本地的 9000 端口。
3. 开始录制
回到 recorder 中,点一下 Start,随后在 FF 中访问http://www.sina.com.cn/FF 发出其他 HTTP 请求(比如导航页面什么的)。你就看得到 gatling 开始录制了。,期间不要从
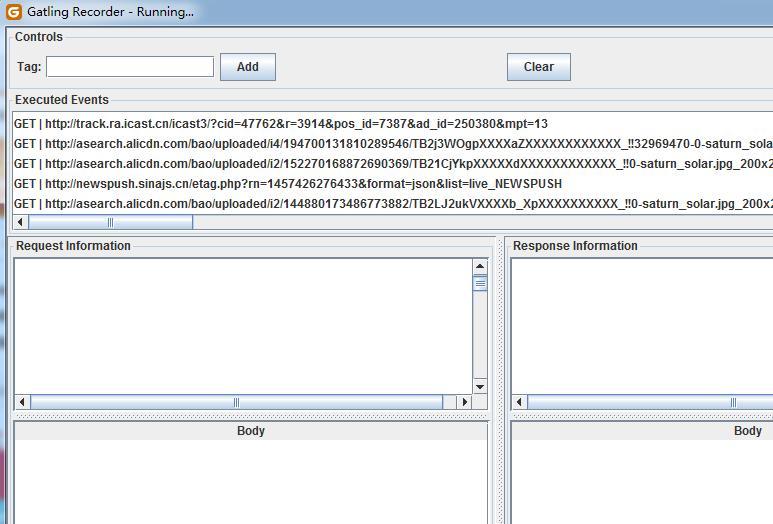
4. 查看脚本
刚才的录制就归结为这样一个.scala 脚本
package sina
import scala.concurrent.duration._
import io.gatling.core.Predef._
import io.gatling.http.Predef._
import io.gatling.jdbc.Predef._
class HomePage extends Simulation {
val httpProtocol = http
.baseURL("http://asearch.alicdn.com")
.inferHtmlResources(BlackList(""".*\.css""", """.*\.js""", """.*\.ico"""), WhiteList())
val headers_0 = Map("Accept" -> "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8")
val headers_4 = Map("Accept" -> "*/*")
val headers_284 = Map(
"Accept" -> "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Pragma" -> "no-cache")
val uri01 = "http://d6.sina.com.cn/pfpghc2"
val uri02 = "http://idigger.qtmojo.com/s"
val uri03 = "http://ifs.tanx.com/ifs"
val uri04 = "d9.sina.com.cn"
val uri05 = "http://www.sina.com.cn"
val uri06 = "http://i.mmcdn.cn/simba/img"
val uri07 = "d7.sina.com.cn"
val uri08 = "http://log.mmstat.com/tanx.709"
val uri09 = "http://i0.sinaimg.cn"
val uri10 = "http://d2.sina.com.cn/pfpghc2"
val uri11 = "http://rm.sina.com.cn/bj-icast/mv/cr/2016/03/250380/47762"
...... //此处省略好几十个uri
val scn = scenario("HomePage")
.exec(http("request_0")
.get(uri05 + "/")
.headers(headers_0)
.resources(http("request_1")
.get("http://" + uri45 + "/hm.gif?cc=0&ck=1&cl=24-bit&ds=1360x768&ep=77626%2C77626&et=3&fl=20.0&ja=0&ln=zh-CN&lo=0<=1457426038&nv=0&rnd=227026994&si=dd4738b5fb302cb062ef19107df5d2e4&st=4&su=http%3A%2F%2Fofflintab.firefoxchina.cn%2F%3Fcachebust%3D20150714&v=1.1.22&lv=2"),
http("request_2")
.get(uri13 + "/data.html?1457426259080")
.headers(headers_0),
http("request_3")
.get(uri13 + "/ckctl.html")
.headers(headers_0),
http("request_4")
.get("http://" + uri80 + "/get_ad_list/PG_514AC419D66F33?callback=lejuDataCallback")
.headers(headers_4),
http("request_5")
.get(uri09 + "/home/main/index2013/0403/icon.png"),
http("request_6")
.get(uri25 + "/dy/deco/2013/0329/logo/LOGO_1x.png"),
http("request_7")
.get(uri25 + "/dy/main/icon/photoNewsLeft2.gif"),
http("request_8")
.get(uri29 + "/home/2014/1030/jb5.jpg"),
http("request_9")
.get(uri09 + "/home/main/index2013/0719/bg2.png"),
http("request_10")
.get(uri16 + "/www/index/12377app.png"),
http("request_11")
.get(uri29 + "/dy/deco/2013/0321/bg1px.png"),
....
//此处省略好几百个request。门户网站请求就是多啊。
setUp(scn.inject(atOnceUsers(1))).protocols(httpProtocol)
}
对稍微懂点代码的测试人员,这个脚本都是简单易懂的:
1). httpProtocol 中的 BlackList 描述了你将不会录制针对 css,js 和 ico 文件的请求。
2). 录制到了几个请求头 header。
3). scenario("HomePage") 定义了这个场景的名称。默认以你的类名来命名,当然你可以改,比如改成 SinaHomePage。修改这个名字只会影响你运行该脚本后在报告中看到的名字。
4). 这个庞大的场景 “HomePage” 赋给了变量 scn。当然,你也可以把他赋值给另一个变量叫做 SinaUsers,看起来更为贴切,代码更易懂。
5). setUp(scn) 就是运行这个场景的主函数。
6). inject 为这个场景注入一些用户。这里 atOnceUsers 代表一次性一个用户来做这个操作——因为刚才录制时就是这种情况.
此时你作为初次使用者,不需要去修改其他,改下注入用户就行了。
setUp(scn.inject(atOnceUsers(10))).protocols(httpProtocol)
或者
setUp(scn.inject(rampUsers(10) over (10 seconds))).protocols(httpProtocol)
前者表示 10 个用户直接并发;后者表示 10 秒钟内线性并发 10 个用户。inject 的注入方法很多,使用的时候把
http://gatling.io/docs/2.1.7/general/simulation_setup.html
当作手册查查,一目了然。
这里就选择第二种方式继续测试。
5. 运行脚本
bin\gatling.bat
运行后短暂等待一下,gatling 会编译 user-files\simulation 里存在的所有脚本:

可以看到已经编译成功。前面 6 个是 gatling 自带的脚本。编号 6 是我们刚才查看并修改的脚本。cmd 中敲入 6,然后回车三下(后面的 simulation id 和 description 留空,所以直接回车)。可以看到 gatling 开始运行。
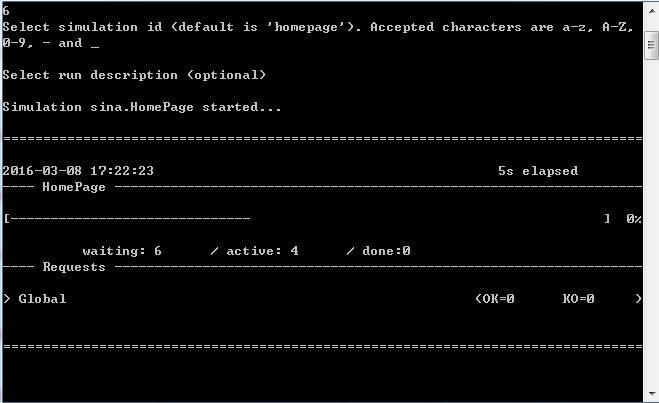
图中可以看到目前有 4 个用户已经开始运作,6 个在等待。完成后会提示报告已经生成
6. 报告一览
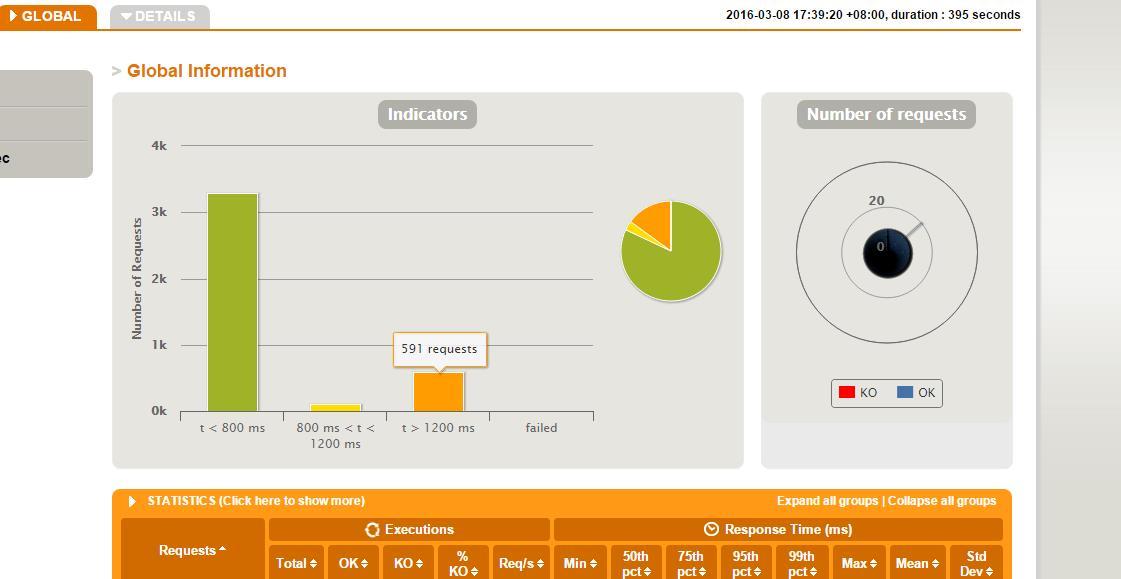
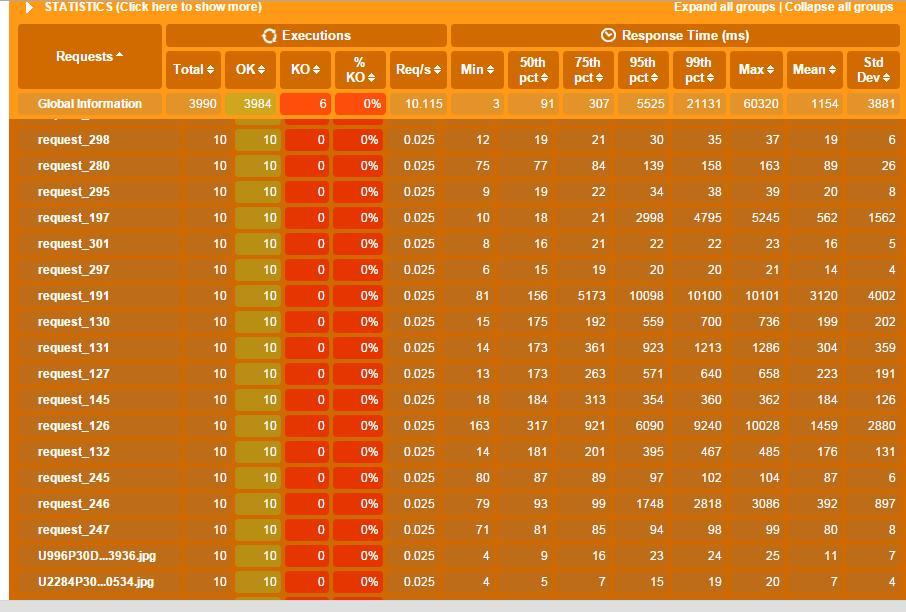
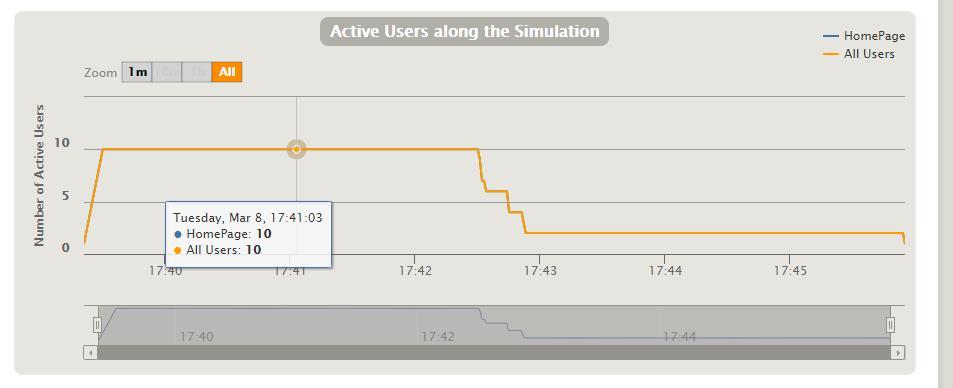
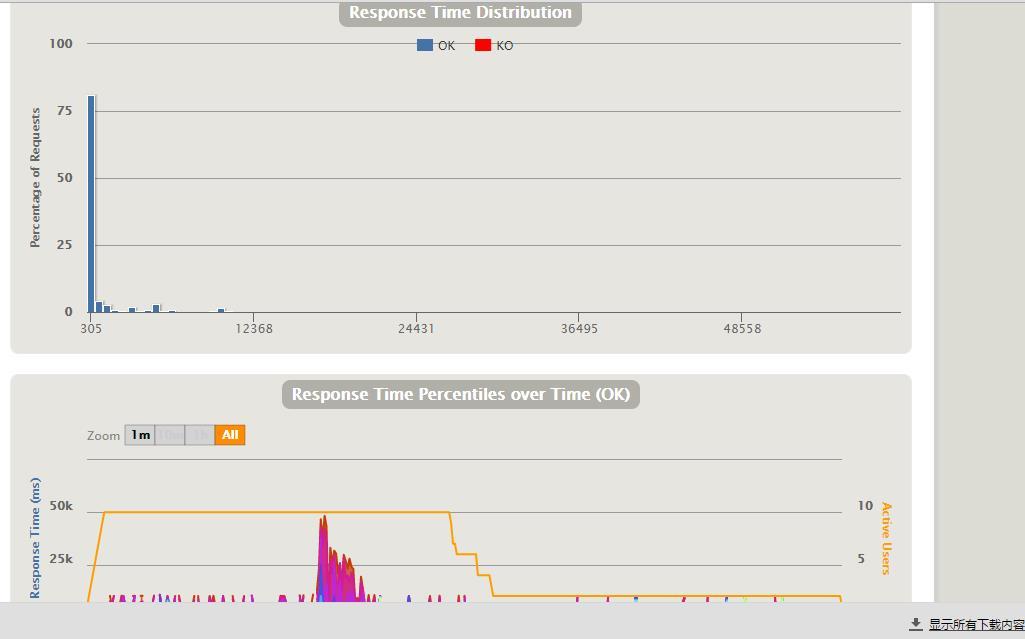
要针对 gatling 的 report 进行详尽透彻的分析,并正确评价系统,甚至找出性能瓶颈,这个可能要些功底 (我还不够),此处我也就不班门弄斧了,以后再把我能理解的一些东西单独发文。
从这个报告中可以看出:
1). 其实并不是录制出来的所有请求都要执行——脚本需要维护和修改。
2). 每一个 request 可以在脚本中修改为易懂的通俗表示从而方便报告的阅读和分析,而不是 request_1,2 3 这样
7. 文件结构
在这份笔记中还想提一下文件的结构。如果所有的.scala 脚本都放置在\user-files\simulations 中某一个包的根目录下,一旦项目变得庞大,自然是不好维护。所以我想要尝试像 java 那样,将脚本以包的形式放置,比如 com.sina.uitest, com.sina.apitest ....
尝试把刚才的脚本放到\user-files\simulations\sina\pages 下,看编译后会不会命名为 sina.pages.HomePage
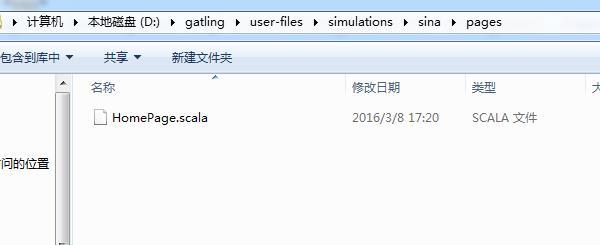
在 target 目录查看,事与愿违,编译后都是放在根目录下了:

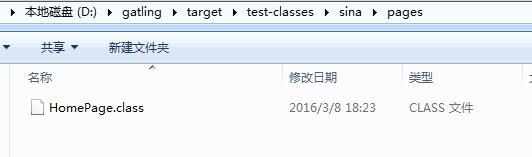
继续尝试,在文件中改包名 package sina 改为 package sina.pages
清空 target 文件夹重新编译,果然成功。

看来 gatling 不会在意你本身的目录结构,包名是在脚本中定义的。如果有一个类似于 Eclipse 的 SCALA IDE,那将会非常便于性能测试脚本的开发和维护: 可以在 conf\gatling.conf 中修改配置
directory {
#data = user-files/data # Folder where user's data (e.g. files used by Feeders) is located
#bodies = user-files/bodies # Folder where bodies are located
#simulations = user-files/simulations # Folder where the bundle's simulations are located
#reportsOnly = "" # If set, name of report folder to look for in order to generate its report
#binaries = "" # If set, name of the folder where compiles classes are located: Defaults to GATLING_HOME/target.
#results = results # Name of the folder where all reports folder are located
}
将 simulations 前方的 # 去掉,然后定义你自己项目的位置。gatling 就会从你指定的地方去编译你的项目并执行了
本文只是个人的学习记录,并非教程。分享也只是为了尽可能的帮助刚接触这个工具的同行入门;也希望有擅长性能测试领域的朋友能够提点一二。