AI测试 大家有在实际运用 playwright-mcp 与大模型结合的 AI 自动化测试吗?
最近试试了都在说这个 AI 自动化,怎么感觉好脑残,连一个登录都过不去,是我姿势不对?
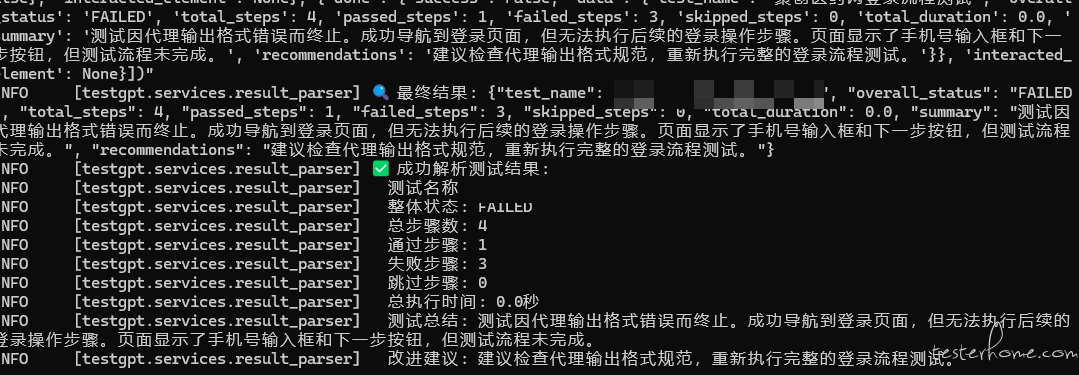
我用过 chrome-mcp-server 插件,可以用已登录的浏览器,免登录。但是搞测试还是不太行。
我使用 claude 4.5 来跑,可以生成一些简单的用例,比如登录后进行点击操作后 assert 提示框是否正确这种用例,更加复杂的没试过
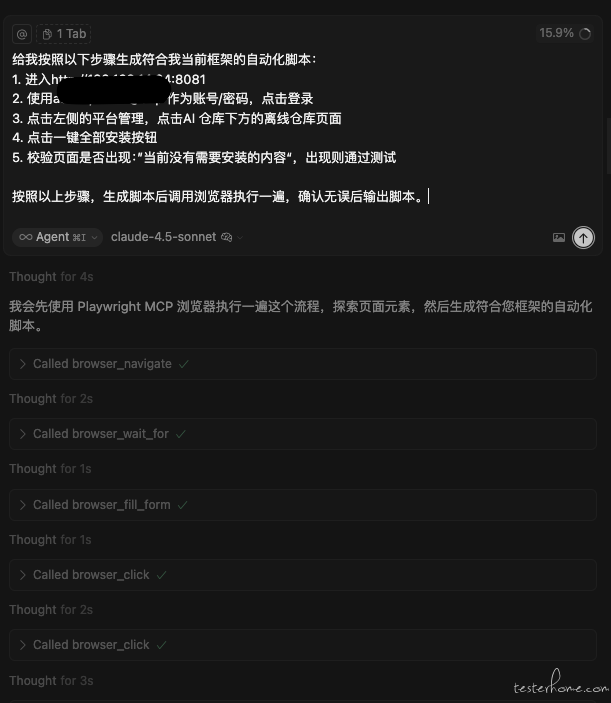
Prompt 如下
我在 cursor 上跑了这个 跑是可以跑 但是速度特别慢,比手工慢,比传统元素定位方式也慢,能集成自己跑吗
目前这个阶段,慢先不说,最主要是的对于元素的智能识别似乎很不稳定,我尝试过 cursor、自己编写代码、git 上开源的代码,都是同样的问题,看起来底层的实现逻辑应该是一样,目前想要实际落地运用到生产上还有很长的路要走
最近在搞这个,AI 生成 UI 自动化测试框架(5 分钟),人工跳转下元素选择器(20 分钟),1 个小时内完成框架搭建,就可以进行自动化跑测
研究过一段时间,和要你命三千差不多,你不给定位器,它就会出幺蛾子,10 次执行 3-4 次出现不同结果,给定位器,都要定位器了,为啥不自己写,手工写的还快准稳。agent 这个玩意目前还需要发展。

在 Trae 或者 cursor 上跑过,感觉就是慢,还有就是不稳定,消耗 token 那些都还没统计过,目前看来还不太行。不稳定是不能落地最主要的因素
已经做了一个平台了,使用 langgraph + qwen3-max + playwright mcp,langgraph 提供大模型接入的能力同时又能做编排,同时也可以自主配置上下文长度和对话的长度,如果用 trae 或者 cursor 执行太长的 case 会触发限制进行不下去,qwen3-max 是目前用的比较精准的模型了,deepseekv3.1 也可以,kimi2 也可以,反正要用好的模型;系统提示词要限制大模型的动作,要严格按照步骤执行,不能随意联想,然后用户提示词的描述要足够精准,如果文字描述不够精准的话就用 id 或者 class 来描述,目前还没有考虑成本问题,但肯定比人力要便宜,只要 case 写的够精准,稳定性还是有保障的,代码里也可以配置失败重试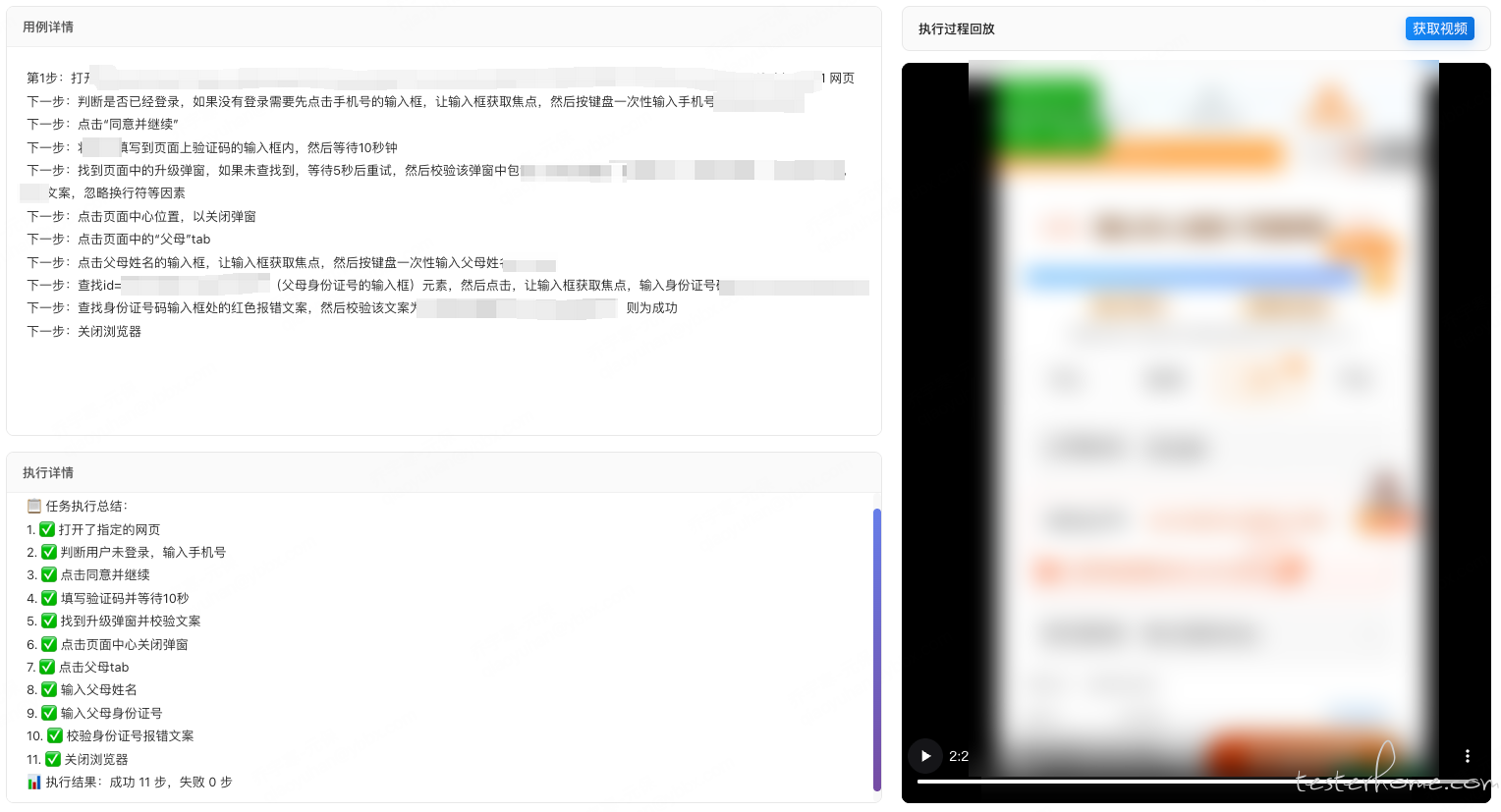
一次让他执行很多步可能有幻觉,每次让他只执行一步幻觉不就少了,每次执行都把页面快照给他看下不是就幻觉更少了