AI测试 300 毫秒生成情感 AI 视频,Nuance Labs 获千万美元融资;AirPods Pro 3 将集成实时语音翻译丨日报

开发者朋友们大家好:
这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement)领域内「有话题的技术」、「有亮点的产品」、「有思考的文章」、「有态度的观点」、「有看点的活动」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。
本期编辑:@Jerry fong,@ 鲍勃
01 有话题的技术
1、Google AI Edge Gallery 上架 Play Store,Gemma 3n 新增音频模态,拓展边缘 AI 应用
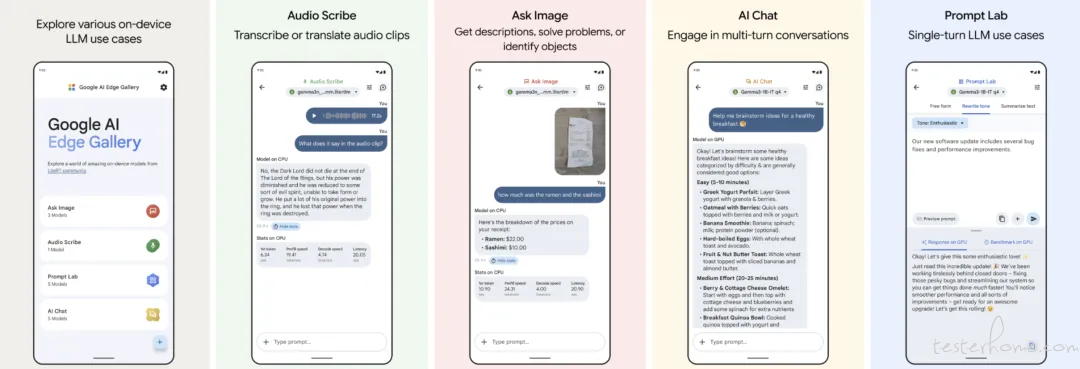
Google 近日宣布将旗下用于展示设备端 AI 能力的「Google AI Edge Gallery」应用正式上架 Google Play Store,并为「Gemma 3n」模型及整个 Google AI Edge 技术栈新增了音频模态支持。这意味着开发者和用户现在可以更容易地体验和构建基于私密、强大的设备端生成式 AI 应用,从而赋能高品质的离线语音转文本和多语言翻译功能,进一步推动边缘 AI 的普及和创新。
关键亮点
「Gemma 3n」新增音频模态: 通过「MediaPipe LLM Inference API」,「Gemma 3n」模型现已支持高质量语音转文本和语音翻译成文本功能,且能够在设备端无需网络连接运行。初期版本支持最长 30 秒的音频批处理推理,流式音频支持已列入未来路线图。
「Google AI Edge Gallery」进驻 Play Store: 这款交互式应用已在 Google Play Store 上架开放 Beta 版本,极大提升了开发者的可访问性,方便其直接体验设备端 AI 模型,其代码将继续在 GitHub 保持开源。
核心演示「Audio Scribe」: Gallery 应用中新增了「Audio Scribe」功能,用户可直接上传或使用设备麦克风录制音频,并实时观看「Gemma 3n」在手机上进行离线转录。
开发者社区反响热烈: 自在 GitHub 发布以来,「Google AI Edge Gallery」的 APK 下载量在短短两个月内已突破 50 万次,充分展示了开发者社区对强大、私密的设备端生成式 AI 的高度热情。
发布计划
「Google AI Edge Gallery」应用已在 Google Play Store 上架开放 Beta 版本,其代码持续在 GitHub 开源。「Gemma 3n」的音频能力通过「MediaPipe LLM Inference API」为 Android 和 Web 平台提供,目前支持最长 30 秒的音频批处理推理。
Google 计划在未来数月内将应用推广至 iOS 用户,展示更多基于「Google AI Edge Generative AI Tasks」(如 RAG 和设备端函数调用)的示例,并计划将应用从「MediaPipe LLM Inference API」迁移至全新的完全开源 LLM 运行时「LiteRT-LM」。
相关链接:
https://developers.googleblog.com/en/google-ai-edge-gallery-now-with-audio-and-on-google-play/
Github:
https://github.com/google-ai-edge/gallery/releases( @Google AI Blog)
2、JHU CLSP 推出 mmBERT:超越 XLM-R,解锁 1800+ 语言的 SOTA 编码器

约翰霍普金斯大学计算语言处理中心(JHU CLSP)近日发布了「mmBERT」,一款最先进的大规模多语言编码器模型。该模型在超过 1800 种语言的 3T+ tokens 文本数据上进行训练,首次在性能上超越了「XLM-R」,并在效率上实现了显著提升。此外,「mmBERT」还创新性地提出了有效学习低资源语言的新策略,为多语言自然语言处理(NLP)领域树立了新标杆。
关键亮点
性能超越业界标准:「mmBERT」是首个在多语言基准测试(如 XTREME)上全面超越「XLM-R」的模型。在英文 GLUE 和 MTEB v2 任务上,其性能与专为英文设计的模型相当,甚至在代码检索(CoIR)方面也表现出色。
大规模语言覆盖与数据透明: 模型在 1800 多种语言的 3T+ tokens 数据集上进行训练,并完全公开了所有训练数据。数据集包含 DCLM、FineWeb2 及其 HQ 版本,以及 StarCoder、ArXiv 等专业语料。
创新的三阶段训练策略: 采用渐进式语言纳入策略,通过三个阶段(预训练、中期训练、衰减阶段)逐步增加语言数量(60 → 110 → 1833),并配合逆向掩码比率调度和退火语言学习,优化低资源语言的学习效率。
高效架构与处理能力: 基于「ModernBERT」架构,结合「Gemma 2 tokenizer」,并利用 Flash Attention 2 和非填充(unpadding)技术,使「mmBERT」的吞吐量比现有模型高出 2-4 倍。同时,它能高效处理长达 8192 个 tokens 的序列。
低资源语言的快速学习: 验证了在训练的短「衰减阶段」引入低资源语言(如 TiQuaD 和 FoQA)能实现显著的性能提升,甚至超越了更大型的 LLM,证明了其基于强大多语言基础快速适应新语言的能力。
「mmBERT」提供了两种尺寸的模型:
「mmBERT-small」(总参数 140M,非嵌入参数 42M)
「mmBERT-base」(总参数 307M,非嵌入参数 110M)
相关链接:
https://huggingface.co/blog/mmbert
Github:
https://github.com/JHU-CLSP/mmBERT
( @JHU CLSP)
3、ElevenLabs v0 Podcast Generator Starter 上线
ElevenLabs Developers 推出了 v0 Podcast Generator Starter
aisdk 生成任何主题的播客脚本
supabase 将脚本存储在数据库中
Eleven v3 生成多个说话人对话
相关链接:
https://x.com/elevenlabsio/status/1965326679758524499(@elevenlabsio)
02 有亮点的产品
1、Mistral AI 完成 17 亿欧元融资

Mistral AI 宣布完成 17 亿欧元的 C 轮融资,由荷兰半导体公司 ASML 领投,投资额为 13 亿欧元,获得 11% 的股份并取得董事会席位。这家 2013 年由前 DeepMind 和 Meta 研究人员创立的法国 AI 初创公司,计划利用这笔资金推动前沿 AI 研究,特别是在芯片制造等关键产业领域。ASML 作为全球领先的光刻设备供应商,其参与体现了双方在技术上的协同潜力。这轮融资标志着 Mistral 在 AI 领域的重要进展,旨在解决战略性行业的核心挑战。
此前,Mistral 推出了首个开源音频模型家族 Voxtral。Voxtral 最长可转录 30 分钟的音频内容。由于集成了 Mistral Small 3.1 大模型,它还能理解长达 40 分钟的语音。这意味着 Voxtral 不仅仅是转录,还能深入理解语音内容,甚至能回答相关问题、支持直接针对音频内容生成结构化摘要,无需串联独立的自动语音识别(ASR)和语言模型。
相关推文:
https://x.com/MistralAI/status/1965311339368444003(@ Mistral AI)
2、Nuance Labs 获千万美元融资,打造首个情感 AI(Emotional AI)

由两名前 Apple Vision Pro 团队博士创立的初创公司「Nuance Labs」,已完成由 Accel 领投的 1000 万美元种子轮融资。他们正在构建一个新型 AI 模型,旨在通过实现实时、富有情感的视频互动,解决当前 AI 交互中的「僵硬感」和「延迟」问题,创造出真正自然的 AI 伴侣。
关键亮点
创新的模型架构:Nuance 并未依赖通用 LLM,而是开发了一种能够直接处理情感信号的新型模型。该模型使用专门的「视觉 token」(visual tokens)来高效解析语音韵律、面部表情和手势,从而在 0.3 至 0.4 秒内生成第一帧视频,实现了对实时交互至关重要的低延迟。
顶尖创始团队与投资机构:创始人 Fangchang Ma 和 Edward Zhang 是前 Apple 博士,曾在 Vision Pro 项目中负责数字虚拟人(digital personas)的研发。本轮融资由顶级风投 Accel 领投,South Park Commons 和 Lightspeed Venture Partners 参投,显示出资本市场对其技术路径的认可。
最终产品愿景:AI 伴侣与开放 API:Nuance 的首要目标是推出一款面向消费者的 AI 伴侣应用,类似电影《Her》中的「Samantha」。未来,他们还计划通过 API 将其情感模型开放给其他开发者,用于虚拟治疗师、AI 导师和互动游戏角色等场景。
差异化竞争优势:与 OpenAI 等巨头先生成文本再转换为视频的多步流程不同,Nuance 的模型旨在直接生成富有情感的互动视频。这种端到端的方法可以绕过传统流程带来的延迟,创造更真实、无缝的交互体验,直接挑战 AI 交互领域的「恐怖谷」难题。
目前,Nuance Labs 仍处于早期研发阶段,团队正在积极利用新资金招聘研究人员。公司计划在未来一年内发布一个面向公众的互动式 Demo。
详细访谈:
https://www.upstartsmedia.com/p/nuance-labs-emotional-ai-model( @Upstarts Media)
3、Apple AirPods Pro 3:AI 实时语音翻译功能
今天凌晨的苹果秋季新品发布会,率先登场的是全新的 AirPods Pro 3。作为苹果这些年开创的最成功的硬件品类,AirPods Pro 系列一直都有良好的用户口碑。不过这一次,苹果在 AirPods Pro 3 上带来的一些新特性,似乎预示着这款产品已经不再只是一款单纯的「TWS 耳机」了。
这次 AirPods Pro 3 主要的升级点首先是音质和降噪。
本体采用了新的多孔声学架构,官方表示能够让低音更沉、音场更广。这主要是因为新的声学结构可以更精准地控制气流,通过直指耳道的内向式麦克风传送声音,带来更深沉的低音和清晰生动的人声表现。
AirPodsPro 3 还具备新一代自适应均衡功能,可根据你的耳形和佩戴贴合度,适应声音效果。个性化音量功能则会运用机器学习技术,了解你的聆听习惯,然后逐渐匹配你的偏好。
为了提升主动降噪效果,苹果还采用了新的耳塞设计,其内旋设计能够让佩戴更稳更贴合。苹果还在耳塞材料上新增了泡沫材料微粒填充层。AirPods Pro 3 这次还提供了多达 5 种尺寸的耳塞可供选择,包括 XXS 号,能够更好满足更多人群的佩戴需求。
全新的设计配合苹果先进的计算音频技术,AirPods Pro 3 能够消除更多的环境噪声,带来更强悍的主动降噪能力。官方表示,主动降噪对比上一代效果提升了 1 倍,比初代则提升了 3 倍。
与此同时,AirPods Pro 3 这次还升级了防尘防水的能力,首次支持 IP57 级别防水标准。这意味着它可以轻松应对日常生活中的泼溅、雨淋,甚至意外掉入水盆、马桶等短暂浸泡情况。不管是大汗淋漓的训练,还是突如其来的大雨,都没有问题。
健康功能的加入是 AirPods Pro 3 这次最大的亮点。
苹果在 AirPods Pro 3 上加入了全新心率传感功能,耳机可在你锻炼时,帮你测量心率和卡路里消耗。只需 AirPods Pro 3 和 iPhone 搭配,就能在健身 App 中开启全新的运动体验。借助每秒 256 次非可见光脉冲的 LED ,以及基于多个加速感应器的传感器融合技术,AirPods Pro 3 可为你的各类体能训练提供精准的测量数据,健身 App 中的 50 多种项目都适用。
这是之前盛传了多年的 AirPods 功能,如今终于落地。
海外版本的 AirPods Pro 3 还加入了 AI 翻译功能。
借助 Apple intelligence 的能力,AirPods Pro 3 搭载了 AI 实时语音翻译功能,耳机可以将听到的声音实时翻译为其他语言。用户可以使用一个手势激活实时翻译,说话人的声音会变得更小,翻译的声音会更大,甚至短语的意思也会被翻译。(@ 电脑报)
03 有态度的观点
1、The Verge:AI 编程最有用的是理解代码
日前,《The Verge》发布了一篇名为《Is AI the end of software engineering or the next step in its evolution?》(人工智能是软件工程的终结还是其进化的下一步?)文章,分析了当下热门的 AI 编程、「Vibe Coding」(氛围编程)发展方向。
作者 Sheon Han 在文中直言,这些 AI 辅助工具让其觉得最有用的不是编写代码,而是理解代码。Sheon 举例:当自己遇到一个陌生的代码库时,AI 能够为自己解释主要组件是怎么组合在一起,并且能够节省摸索陌生代码的时间。
据悉,时下火热的「Vibe Coding」(氛围编程)是一种新兴的软件开发实践,它能够让 AI 根据用户给出的自然语言提示词进行代码生成,并号称「加快开发速度,让应用构建变得更加容易」。
而 Sheon 进一步指出,氛围编程固然能够减轻写代码的负担,但它会如同「建筑师没见过施工现场」一样,只能观察到 AI 交付的结果,却浑然不知里面的结构如何。
同时,Sheon 还提到了软件结构的「品味」:「优秀的软件架构并非一蹴而就,而是由无数合理且具品味的微观决策逐渐形成,这是模型无法零样本学习的。」
关于「AI 辅助编程是否能真正提高工作效率」这一话题,Sheon 认为「会减慢效率,但 AI 也需要成为生产力方程式中的真正代表」。同时其也指出,我们要养成一种快速区分并脱离依赖 AI 的心:要适度使用 AI 以克服障碍,然后切换回运用我们的大脑。否则,你将失去理解任务目的核心要义的能力。(@ APPSO)
04 社区黑板报
招聘、项目分享、求助……任何你想和社区分享的信息,请联系我们投稿。(加微信 creators2022,备注「社区黑板报」)
1、社区项目分享:3 Times Meet 告别跑题会议
3 Times Meet 是一款 AI 驱动的会议辅助工具,主要目的在于帮助会议保持节奏,不偏离主题,有效避免时间浪费。它提供实时语音引导、会议进度控制,以及即时资源检索等功能 。
X 自我介绍强调:这可能是「全球首个 AI 会议促成者」,主打 real-time voice guidance(实时语音指导)、live resource retrieval(实时资源获取)、和 meeting pace control(会议节奏控制)。
3 Times Meet 已集成 Google Workspace、Zoom、Perplexity,并在 200+ 场会议中测试。
功能亮点
主动干预:不仅是记录会议内容,更会实时参与,提醒并纠正会议偏离主题或无效率的部分。
语音交互:使用者可以通过语音与系统互动,让会议更自然、顺畅。
动态节奏调整:根据会议进度自动调整议程节奏,比如加速或提示时间剩余。
官网链接:https://3xmeet.net/


阅读更多 Voice Agent 学习笔记:了解最懂 AI 语音的头脑都在思考什么
写在最后:
我们欢迎更多的小伙伴参与 「RTE 开发者日报」 内容的共创,感兴趣的朋友请通过开发者社区或公众号留言联系,记得报暗号「共创」。
对于任何反馈(包括但不限于内容上、形式上)我们不胜感激、并有小惊喜回馈,例如你希望从日报中看到哪些内容;自己推荐的信源、项目、话题、活动等;或者列举几个你喜欢看、平时常看的内容渠道;内容排版或呈现形式上有哪些可以改进的地方等。

素材来源官方媒体/网络新闻