AI测试 阶跃星辰开源端到端语音模型 Step-Audio 2 mini:理解、推理与生成统一建模;苹果发布可在浏览器运行的视觉模型丨日报

开发者朋友们大家好:
这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement)领域内「有话题的技术」、「有亮点的产品」、「有思考的文章」、「有态度的观点」、「有看点的活动」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。
本期编辑:@ 子禾、@ 鲍勃
01 有话题的技术
1、阶跃星辰发布开源端到端语音大模型 Step-Audio 2 mini
阶跃星辰(StepFun)近日正式开源了其端到端语音大模型 Step-Audio 2 mini,该模型在多项国际基准测试中取得了领先(SOTA)成绩。它将语音理解、音频推理与生成统一建模,能够处理包括语音识别、跨语种翻译、情感解析、语音对话等多种任务,其综合性能已超越 GPT-4o Audio 及其他主流开源模型。这款模型的一大亮点是原生支持 Tool Calling 能力,可实现联网搜索等高级操作,赋予其强大的知识增强和多场景应用能力。
Step-Audio 2 mini 的核心技术优势在于其创新的「真端到端」架构。与传统的「ASR+LLM+TTS」三级结构不同,它实现了从原始音频到语音响应的直接转换,显著降低了时延,并能有效理解音频中的「弦外之音」,如情绪、语调和非人声信号。此外,该模型首次在端到端语音领域引入了思维链(Chain-of-Thought, CoT)推理与强化学习的联合优化,使其具备更强的逻辑推理和自然回应能力,解决了以往语音模型「智商情商双低」的问题。
在性能上,Step-Audio 2 mini 在多个关键基准测试中表现卓越。它在通用音频理解测试集 MMAU 上得分位居榜首,在口语对话能力 URO Bench 上获得最高分。尤其在语音翻译和识别任务上,表现出压倒性优势,其英中互译、多语言与多方言识别的错误率均大幅领先其他开源模型 15% 以上。目前,该模型已在 GitHub、Hugging Face 和 ModelScope 等平台开源,欢迎开发者下载和体验。
相关链接:
https://github.com/stepfun-ai/Step-Audio2
(@ 阶跃星辰)
2、苹果发布实时视觉语言模型 FastVLM:速度提升 85 倍,体积缩小 3.4 倍
苹果公司近日在 Hugging Face 平台发布了 FastVLM 一系列支持 WebGPU 的实时视觉语言模型(VLM),参数量级分别为 0.5B、1.5B 和 7B。
其速度比同规模 VLM 快 85 倍,模型体积小 3.4 倍。
对于更大模型,其首字符生成时间(TTFT)快 7.9 倍。
该模型经专门设计,可减少输出令牌(output tokens)数量,并降低高分辨率图像的编码时间。
额外亮点:得益于 transformers.js 和 WebGPU 驱动,该模型可直接在浏览器中实时运行。
体验链接:
https://huggingface.co/spaces/apple/fastvlm-webgpu
( @Vaibhav (VB) Srivastav )
3、腾讯 ARC 实验室开源长时叙事音频生成模型 AudioStory
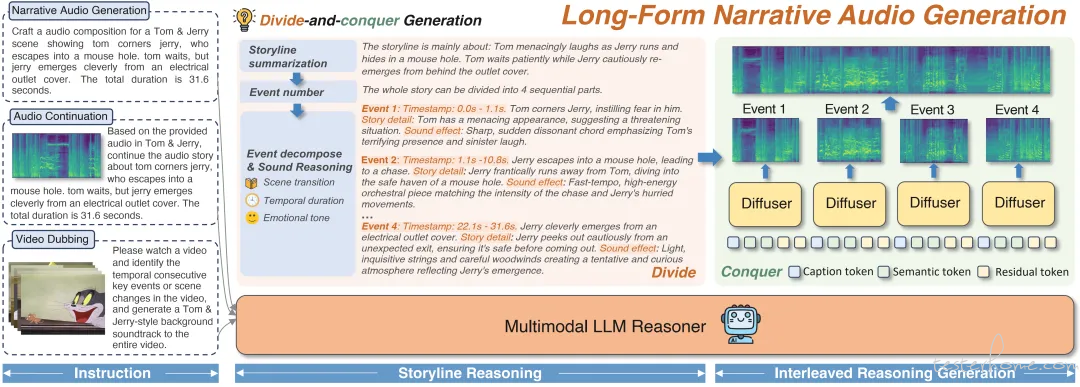
腾讯 ARC 实验室公开了 AudioStory 项目,实现了基于大语言模型(LLM)的长时叙事音频生成。该系统通过 LLM 将复杂指令拆解为带时间顺序的子任务,在视频配音、音频续写、长音频合成等应用中保持情节的连贯性与情感的一致性。
其架构采用「桥接查询」来对齐事件内的语义,并通过「一致性查询」保持跨事件的连贯性,同时支持端到端训练。官方同步放出了 AudioStory-10K 基准、推理代码、演示视频与训练脚本,支持 Python 3.10、PyTorch≥2.1.0 及 NVIDIA GPU 部署。实测结果显示,在单条音频与叙事音频生成任务上,AudioStory 均优于现有的 TTA 基线模型。
相关链接:
https://github.com/TencentARC/AudioStory
(@ 橘鸭 Juya )
02 有亮点的产品
1、腾讯元宝上线 AI 口语陪练功能
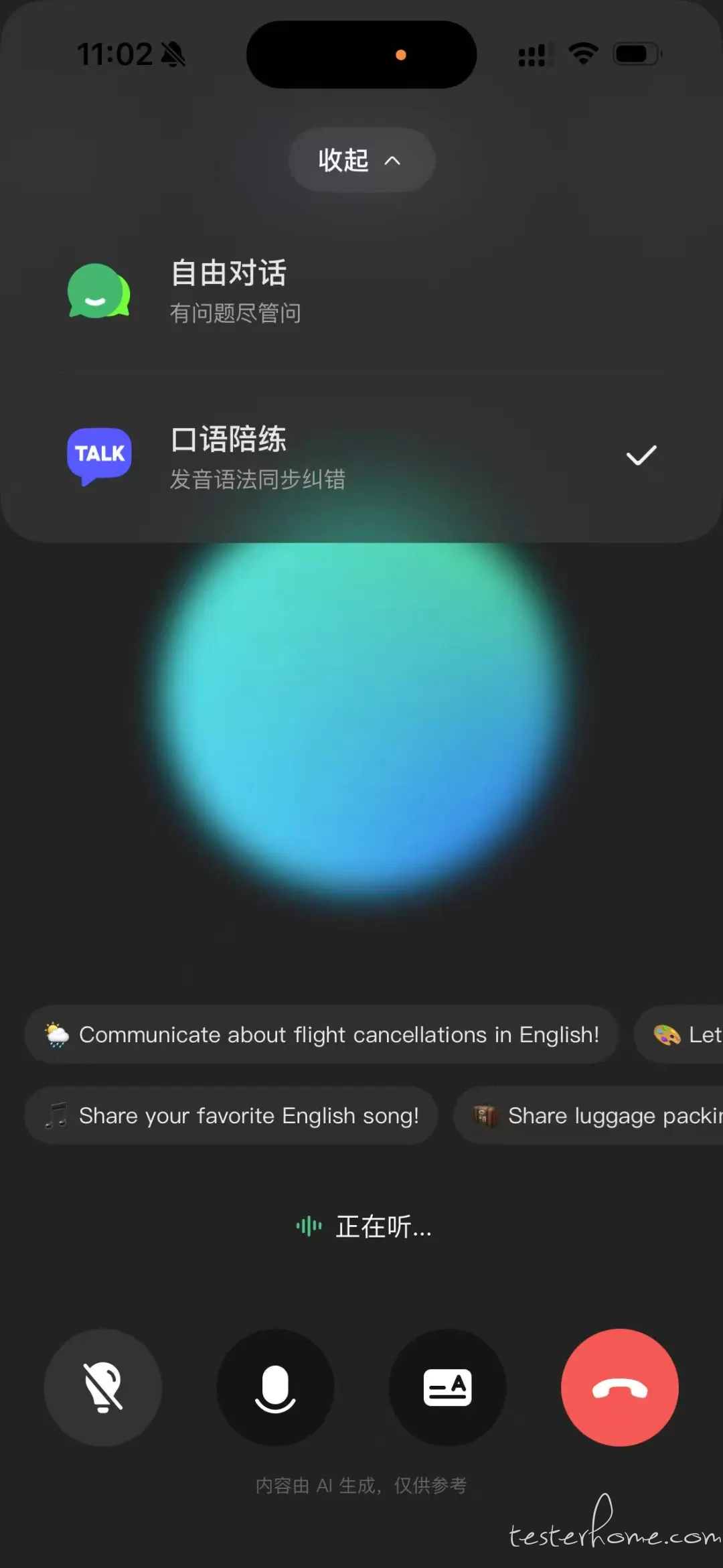
8 月 29 日,腾讯元宝正式上线 AI 口语陪练功能。该功能为用户提供了一个 24 小时在线的私人外教,通过中英对照、口语评测针对性跟读等模式,帮助用户随时随地提升英语口语能力。目前,该功能已在腾讯元宝手机端全面上线,用户点击首页电话图标,切换至口语陪练模式,即可免费开启对话。
功能入口:首页点右下角「电话」按钮,切换成「口语陪练」模式,直接开口就能和 AI 练对话,24 小时都有「私人外教」,想什么时候开口就什么时候开口。
(@36 氪)
2、苹果新款 AI 聊天机器人 Asa 曝光,帮助零售员工销售 iPhone
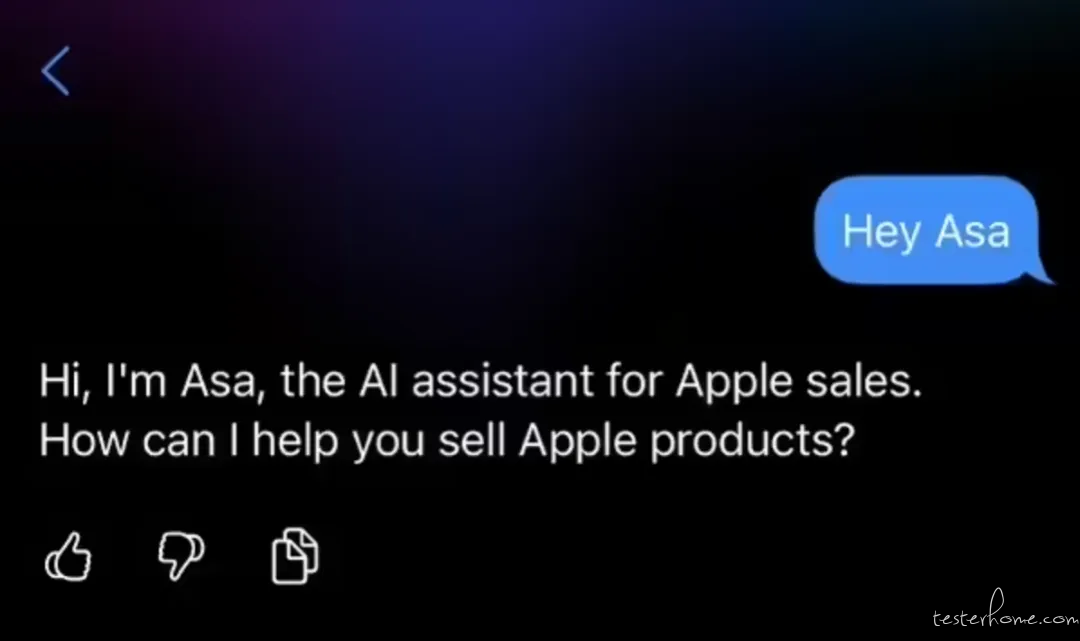
根据 MacRumors 分析师 Aaron Perris 今日提供的截图,苹果向旗下零售员工推出了一款新的 AI 聊天机器人——Asa。
该聊天机器人可以帮助员工了解更多关于苹果的优势,了解 iPhone 的不同使用案例等。员工也可以自由地向它提出任何他们想问的问题。目前,该工具仍在测试中。
分析师称,该工具将很快在苹果内部的「SEED」应用中广泛提供,帮助员工学习更多关于苹果及其产品,提升他们的销售能力。
(@ 极客公园)
03 有态度的观点
1、a16z 合伙人:AI 的下一个突破口在于硬件
Andreessen Horowitz(a16z)的合伙人 Bryan Kim 指出,尽管当前的 AI 技术已十分强大,但其潜力因被局限于网页文本框中而受到限制。为了让 AI 真正融入日常生活,它需要一个物理载体——硬件。Bryan Kim 认为,这与移动互联网的兴起类似,硬件的根本性改变能催生出全新的用户行为和应用场景。硬件设备能够被动地、持续地收集用户的行为和环境数据,为 AI 提供更丰富的语境信息,使其变得真正智能和有用。
然而,AI 硬件的成功需要克服三大挑战:形态因子必须被社会大众接受、功能价值必须足够吸引人,以及应用场景必须精确且有价值。目前,许多类似谷歌眼镜的设备仍显得过于科幻和侵扰。因此,成功的 AI 硬件需要找到一种隐形、有吸引力且具有明确价值主张的产品形态,就像为工厂工人设计的 AI 眼镜那样,它解决了一个具体而有价值的问题。只有当硬件能找到精确的切入点时,AI 才能真正从文本框中解放出来,发挥其巨大潜力。
(@ Z Potentials )
2、《人工智能生成合成内容标识办法》今日起施行
今年 3 月,国家互联网信息办公室、工业和信息化部、公安部、国家广播电视总局制定了《人工智能生成合成内容标识办法》,本办法自2025年9月1日(即今日)起施行。
《标识办法》明确,人工智能生成合成内容标识主要包括显式标识和隐式标识两种形式:
显式标识是指在生成合成内容或者交互场景界面中添加的,以文字、声音、图形等方式呈现并可以被用户明显感知到的标识;
隐式标识是指采取技术措施在生成合成内容文件数据中添加的,不易被用户明显感知到的标识。
依据《人工智能生成合成内容标识办法》规定:
用户在发布或传播 AI 生成合成内容时,不得以任何方式删除、篡改、伪造或隐匿平台添加的 AI 标识。
同时不得利用 AI 技术制作传播虚假信息、侵权信息以及从事任何违法违规活动。对于违反法律法规及平台规范的行为,平台将视违规情况进行处罚。
( @APPSO )


写在最后:
我们欢迎更多的小伙伴参与 「RTE 开发者日报」 内容的共创,感兴趣的朋友请通过开发者社区或公众号留言联系,记得报暗号「共创」。
对于任何反馈(包括但不限于内容上、形式上)我们不胜感激、并有小惊喜回馈,例如你希望从日报中看到哪些内容;自己推荐的信源、项目、话题、活动等;或者列举几个你喜欢看、平时常看的内容渠道;内容排版或呈现形式上有哪些可以改进的地方等。

素材来源官方媒体/网络新闻