本次二次开发需求:
已知项目 m 内,存在方法 mA,mB,mC 他们在 exec1 内都存在;修改代码后,删除了 mA,mC 内新增一个同级方法 mD,通过 jacoco 扫描后生成 exec2;代码对比时,由于对比结果会以 exec2 为主,忽视 mB 的代码统计。
本次修改结果需要取 exec1 和 exec2 的并集,取值结果需要 mB 的代码覆盖率也正常在 report 内展示
一、环境配置
检查下本地的 jdk 和 maven 版本,需要 JDK11+MAVEN3.6.3
二、代码拉取
jacoco 开源项目:xxx
测试用临时项目:xxx
三、项目结构
[图片]
根据代码覆盖率统计 这篇文章,我们找到本次需要修改方法是 cli 内的 report 方法。 根据这条信息,我们找到源代码:
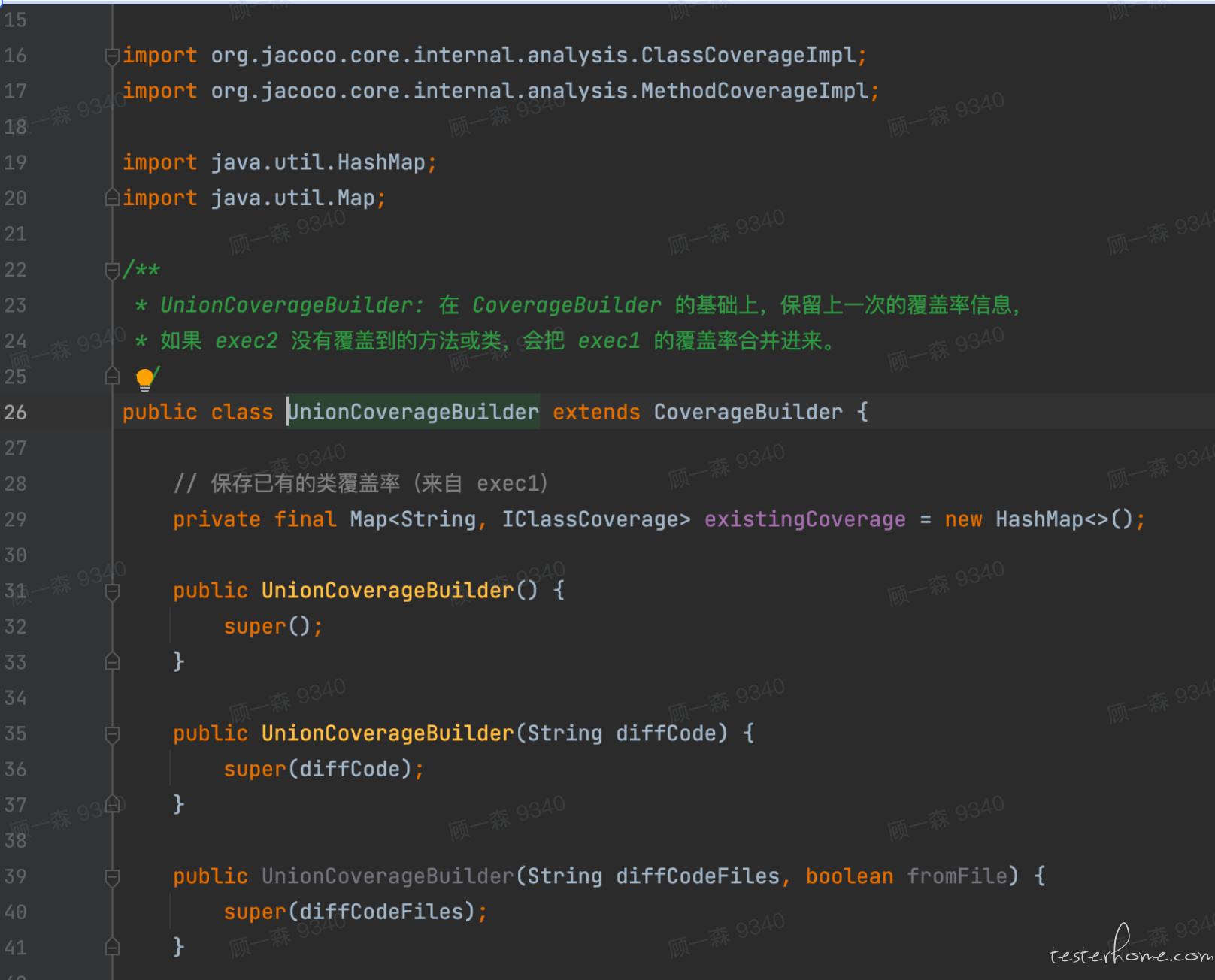
针对这段代码,我发现他的主要判断都通过 CoverageBuilder 实现报告的对比,因此我针对 CoverageBuilder 这个方法进行了重构,引申出 UnionCoverageBuilder.java
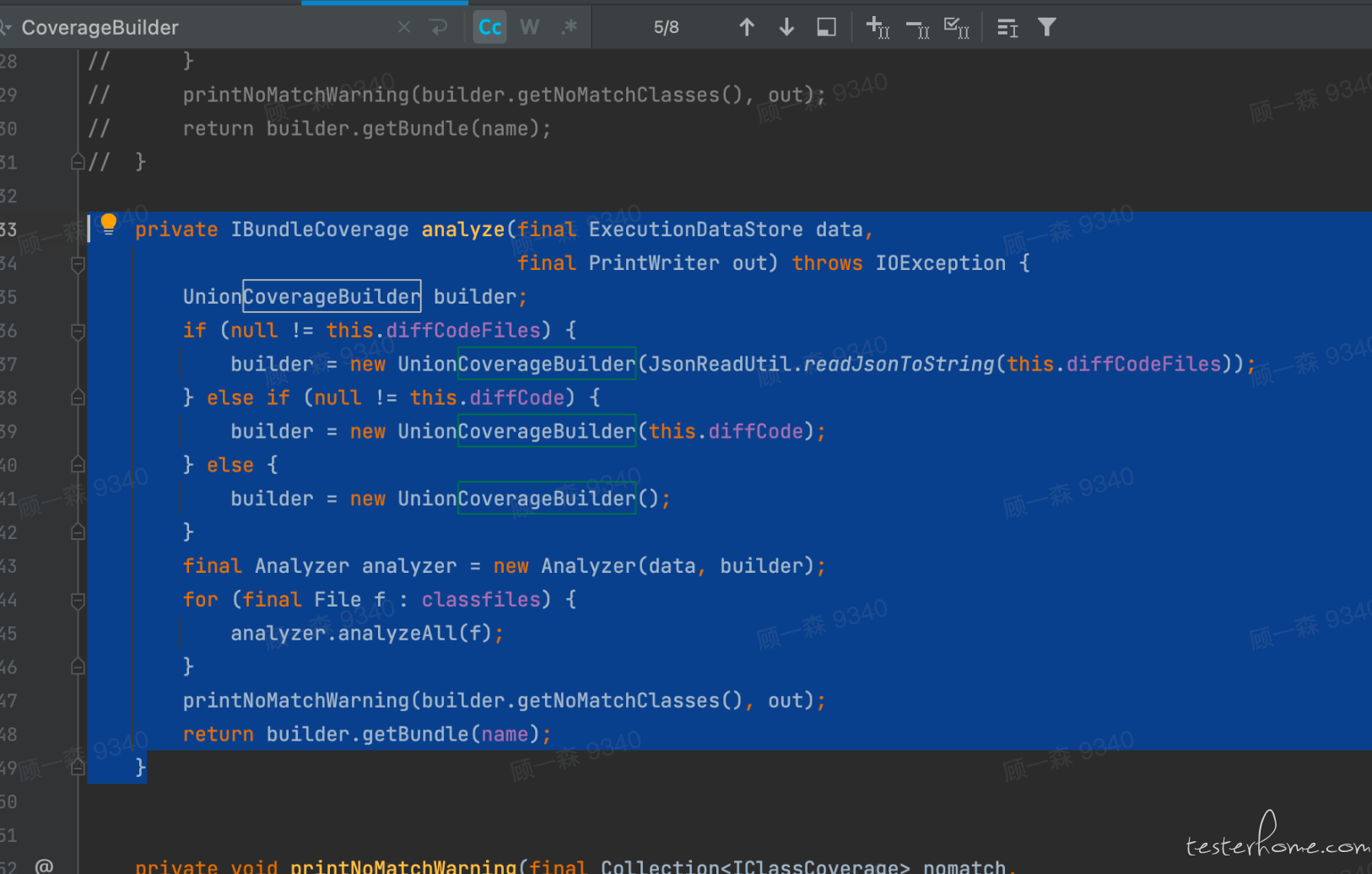
通过 java 的三大特性之一,继承,我们新产生了一个子类,同时支持父类功能。
四、代码生成
4.1 使用 AI 写代码
AI 在本次源码修改中的作用,就是在我们理清我们需要执行的需求后,通过精准表达和二次沟通,实现他为我们写代码。我这里用的 gpt5 版本直接生产代码脚本,而我们所需要做的只有两点:代码逻辑的理解和调试;当这两者都做完并通过后,这块小需求也就可以直接上线了。
AI 在写代码时,针对单个类的代码块编写能力是强于人的;而针对多个类之间的调用是弱项;针对开源代码的修改,我们可以直接告诉它代码源头在哪,然后根据实际情况描述我们的逻辑最终生成代码
4.2 生成新包
为了长期区分我们二开后的 jacoco 包与常见开源包做区分,我添加了 01lb 包标识
通过执行 mvn clean install -DskipTests 后,我们生成了可以使用的 jar 包,jar 包默认在 target 文件夹下
将这个 jar 包上传到 maven,即可正常引用;
五、新功能测试
5.1 下载测试项目
git clone xxxx
5.2 获取 master 的第一次的报告
git checkout master
mvn clean test -DargLine="-javaagent:/Users/apple/Documents/tools/jacoco/jacocoagent.jar=destfile=jacocoA.exec"
cp ./jacocoA.exec /Users/apple/Documents/workspaces/comparefile/jacocoA.exec
5.3 获取修改后的代码报告
git checkout temp-branch
mvn clean test -DargLine="-javaagent:/Users/apple/Documents/tools/jacoco/jacocoagent.jar=destfile=jacocoB.exec"
cp ./jacocoB.exec /Users/apple/Documents/workspaces/comparefile/jacocoB.exec
5.4 生成代码对比报告
java -jar /Users/apple/Documents/tools/jacoco/org.jacoco.cli-0.8.7-01lb-nodeps.jar report \
../comparefile/jacocoD.exec ../comparefile/jacocoC.exec \
--classfiles target/classes \
--sourcefiles src/main/java \
--xml ../comparefile/union-report.xml \
--html ../comparefile/union-report
生成的测试报告在 union-report 下,点开 html 即可查看
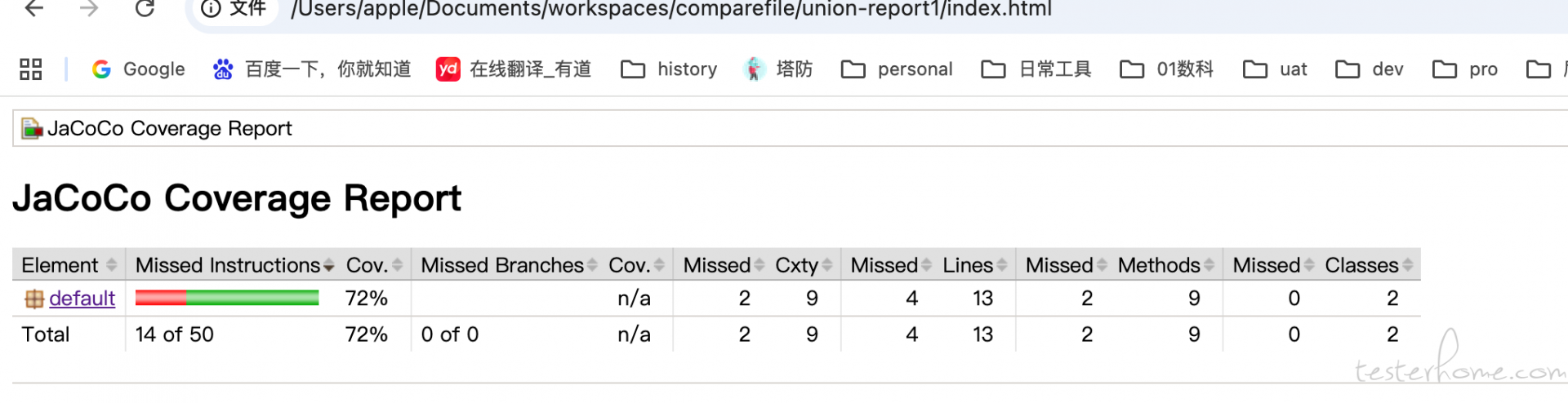
六、总结
希望通过这篇文章,能学到
1、开源的代码如何运行
2、AI 赋能代码开发的简单应用