大家好!我是新人唱跳 rap 打篮球,是一个立志 2025 年开始每周都能水一篇文章的人
前面我们讲了机器学习的前两个步骤:定义问题、收集数据和预处理
定义问题中,我们定义了要处理的问题,也就是根据点赞数和转发数等指标,估计一篇文章能实现多大的浏览量。
我们把它归类为回归问题。
收集数据和预处理,我们做好了数据的预处理工作,还把数据集拆分成了这四个数据集:
特征训练集(X_train)、特征测试集(X_test)、标签训练集(y_train)、标签测试集(y_test)
有了数据集后,我们就可以开始考虑选什么算法,然后建立模型了。
现在来看后面三个步骤:选择算法并建立模型、训练拟合模型和评估并优化模型性能,来把这个项目做完。
第三步 选择算法并建立模型
这一步,我们需要先根据特征和标签之间的关系,选出一个合适的算法,并找到与之对应的合适的算法包,然后通过调用这个算法包来建立模型。
上次说过,这个数据集里的某些特征和标签之间,存在着近似线性的关系。
这个数据集的标签是连续变量,因此,适合用回归分析来寻找从特征到标签的预测函数。
所谓回归分析(regression analysis),就是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析。
当自变量变化的时候,研究一下因变量是怎么跟着变化的,它可以用来预测客流量、降雨量、销售量等。
回归分析的算法有很多种,比如说线性回归、多项式回归、贝叶斯回归等
那么我们该选哪个呢?根据特征和标签之间的关系来决定的
在可视化过程中,推测特征和标签可能存在线性关系,并且用下面这个散点图简单做了验证。
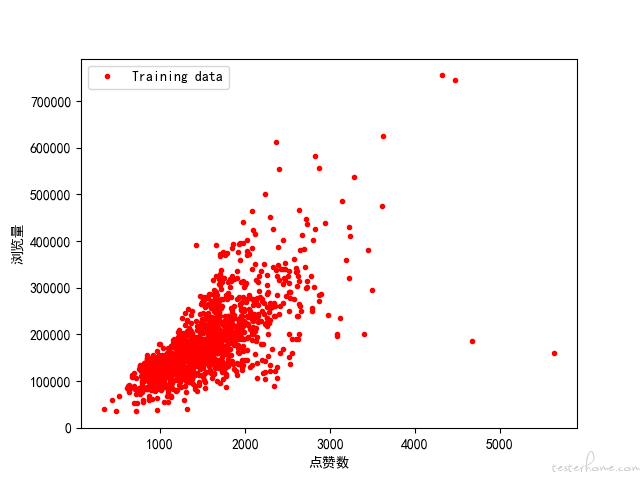
所以这里我们就选择用线性回归算法来建模。
线性回归算法是最简单、最基础的机器学习算法,它其实就是给每一个特征变量找参数的过程。
这个是我们很熟悉一元线性回归的公式:
y = a * x + b
对于一元线性回归来说,它的内部参数就是未知的斜率和截距。
只不过在机器学习中,我们把斜率 a 叫做权重(weight),用英文字母 w 代表,把截距 b 加做偏置(bias),用英文字母 b 代表。
所以机器学习中一元线性回归的公式也写成
y = w * x + b
而在我们这个项目中,数据集中有 4 个特征,所以就是:
y = w1x1 + w2x2 + w3x3 + w4x4 + b
我们的模型就会有 5 个内部参数,也就是 4 个特征的权重和一个偏置(截距)需要确定。
这些公式的具体代码实现,都不用我们自己完成,它们全部封装在工具包里了。
我们只需要对算法的原理有个印象就行了
现在我们需要看一下调用什么样的算法包建立模型比较合适
对于机器学习来说,最常用的算法工具包是 scikit-learn,简称 sklearn,它是使用最广泛的开源 Python 机器学习库,堪称机器学习神器。
sklearn 提供了大量用于数据挖掘的机器学习工具,涵盖数据预处理、可视化、交叉验证和多种机器学习算法。
虽然我们已经选定使用线性回归算法,但是在 sklearn 中又有很多线性回归算法包
比如说基本的线性回归算法 LinearRegression,以及在它的基础上衍生出来的 Lasso 回归和 Ridge 回归等。
怎么选择项目的算法包呢?一般选算法包的方法是从能够解决该问题最简单的算法开始尝试,直到得到满意的结果为止。
对于这个项目,我们选项 LinearRegression,它也是机器学习中最常见、最基础的回归算法包。
如何调用呢?
from sklearn.linear_model import LinearRegression
linereg_model = LinearRegression() # 使用线性回归算法创建模型
上面的代码我们已经建立一个基础的模型了,我们开始训练它了。
有一点需要指出,建立模型时,你通常还需要了解它有哪些外部参数,同时指定好它的外部参数的值。
模型的参数有两种:内部参数和外部参数。
内部参数是属于算法本身的一部分,不用我们人工来确定,刚才提到的权重 w 和截距 b,都是线性回归模型的内部参数;
而外部参数也叫做超参数,它们的值是在创建模型时由我们自己设定的。
对于 LinearRegression 模型来讲,它的外部参数主要包括两个布尔值
- fit_intercept,默认值为 True,代表是否计算模型的截距。
- normalize,默认值为 False,代表是否对特征 X 在回归之前做规范化。
对于比较简单的模型来说,默认的外部参数设置也都是不错的选择,所以,我们不显式指定外部参数而直接调用模型,也是可以的。
在上面的代码中,我就是在创建模型时直接使用了外部参数的默认值。
我们已经创建好线性回归模型 linereg_model,接下来就可以进入机器学习的核心环节 “训练拟合机器学习模型” 了。
今天就到这里了,晚安了
我是新人唱跳 rap 打篮球,是一个立志 2025 年开始每周都能水一篇文章的人,希望我的文章可以给你带来好心情!