AI测试 Pickle 开源 AI 桌面助手 Glass:捕捉屏幕生成结构化信息;邱锡鹏团队开源对话语音模型 MOSS-TTSD 丨日报
开发者朋友们大家好:
这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement)领域内「有话题的 技术 」、「有亮点的 产品 」、「有思考的 文章 」、「有态度的 观点 」、「有看点的 活动 」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。
本期编辑:@ 赵怡岭、@ 鲍勃
01 有话题的技术
1、邱锡鹏团队开源对话语音模型 MOSS-TTSD:百万小时音频训练打造

MOSS-TTSD 基于 Qwen3-1.7B-base 模型进行续训练,采用离散化语音序列建模方法。团队在约 100 万小时单说话人语音数据和 40 万小时对话语音数据上进行训练,实现了中英双语语音合成能力。
MOSS-TTSD 能够根据完整的多人对话文本,直接生成高质量对话语音,并准确捕捉对话中的韵律变化和语调特性,实现超高拟人度的逼真对话语音合成。团队进一步整理了更多 MOSS-TTSD 的音频样例,以展示模型的出色表现。以下是 MOSS-TTSD 生成播客片段,表现出了优秀的零样本音色克隆能力和稳定的长语音生成能力,进一步验证了其在情感表达、语调自然度和整体流畅性上的优异性能。
项目地址:https://github.com/OpenMOSS/MOSS-TTSD
在线体验:https://huggingface.co/spaces/fnlp/MOSS-TTSD
相关链接:https://www.open-moss.com/cn/moss-ttsd/(@ 机器之心)
2、Gemini CLI 更新:新增音视频处理等多项功能

Gemini CLI 近日重磅更新,新增音视频处理功能,虽然目前该功能尚未全面开启,但已经显著提升了多模态交互能力。Markdown 功能也得到增强,支持精美表格渲染与内容导入等等。
支持音视频输入:现在可以在 Gemini CLI 中直接使用音频和视频文件作为输入,极大地扩展了其多模态交互能力;
Markdown 功能增强:新版本现已支持精美的 Markdown 表格渲染,而且可以在 Markdown 文件中使用 @ 符号导入其他 。md 文件的内容;
集成 VSCodium 和 Neovim:新版本增加了直接调用 VSCodium 和 Neovim 修改内容的功能;
技术栈升级:项目底层已升级至 Ink 6 和 React 19,性能提升,也为未来的功能开发奠定了坚实的基础;
全新「Shades of Purple」主题:由知名开发者 Ahmad Awais 贡献的全新紫色系主题;
隐私管理(/privacy):新增 /privacy 命令,允许用户方便地查看和更改自己的隐私设置;
历史记录压缩重构:对历史记录的压缩算法进行了重构优化;
无限循环保护:客户端增加了无限循环保护机制,有效防止意外情况下的程序卡死;
网络支持增强:增加了对带有自定义请求头的 Http MCP 服务器的支持。(@AI 寒武纪、@ 果比 AI)
3、苹果开源全新代码生成模型 DiffuCoder-7B-cpGRPO
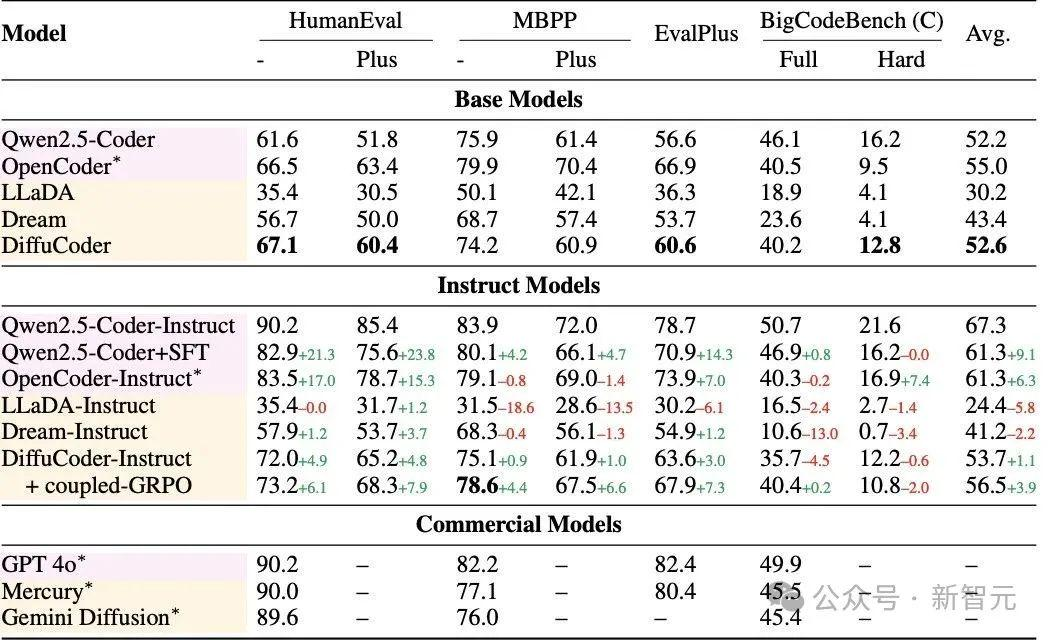
近日,苹果公司在 HuggingFace 平台悄然上线其最新大模型成果——DiffuCoder-7B-cpGRPO。
这一版本在原有 DiffuCoder-Instruct 的基础上,进一步引入了 Coupled-GRPO 强化学习算法进行微调,显著提升了在代码生成任务上的表现。根据官方说明,该模型在 EvalPlus 基准测试中性能提升 4.4%,并有效减轻了解码过程中对自回归偏差的依赖。
DiffuCoder-7B-cpGRPO 属于苹果打造的扩散式大语言模型系列,具备 76.2 亿参数,采用 bfloat16 精度训练,支持基于提示词的代码生成。其训练流程基于 DiffuCoder-7B-Instruct 初始化,并在 2.1 万条代码数据上进行一个 epoch 的后训练。
开发者可通过 HuggingFace 上的模型卡及 GitHub 页面查看详细文档与使用方法。示例代码展示了该模型如何通过扩散过程生成代码,包括提示词构建、模型加载与生成参数配置等内容,便于开发者快速上手集成。
值得注意的是,DiffuCoder 的架构和生成工具部分借鉴了开源项目 Dream,用于支持 HuggingFace 平台的部署发布。
论文链接:https://arxiv.org/abs/2506.20639
项目链接:https://github.com/apple/ml-diffucoder
HuggingFace: https://huggingface.co/apple/DiffuCoder-7B-cpGRPO(@APPSO、@ 新智元)
4、上海 AI Lab 开源持续迭代的高质量视频数据集项目 Sekai:涵盖全球 101 国家 750 多城市的 5000+ 小时第一人称视频
上海人工智能实验室、北京理工大学、上海创智学院、东京大学等机构聚焦世界生成的第一步——世界探索,联合推出一个持续迭代的高质量视频数据集项目——Sekai(日语意为「世界」),服务于交互式视频生成、视觉导航、视频理解等任务,旨在利用图像、文本或视频构建一个动态且真实的世界,可供用户不受限制地交互探索。
它汇聚了来自全球 101 个国家和地区、750 多座城市的超过 5000 小时第一人称行走与无人机视角真实世界或游戏视频,配有精细化的标签,涵盖文本描述、地点、天气、时间、人群密度、场景类型与相机轨迹等重要信息。总的来说,具有视频质量高、视频时间长、视角多样、地域丰富及多维度标签等特点。
Sekai 通过精心收集 YouTube 视频和游戏内高清影像,形成了两个互为补充的数据集:面向真实世界的 Sekai-Real(YouTube 视频)和面向虚拟场景的 Sekai-Game(游戏视频)。
为进一步提升数据质量,团队设计了综合考虑视频画质、内容多样性、地点、天气、时间、相机运动轨迹等多个维度的采样模块,优中取优提取了超过 300 小时的子集 Sekai-Real-HQ。
团队还利用 Sekai 部分数据,训练了一个初步的交互式视频世界探索模型——Yume(日语意为「梦」)。Yume 在输入图片的基础上,通过交互式键鼠操作(移动、视角转动)自回归形式地控制生成视频。
文章链接:https://arxiv.org/abs/2506.15675
项目主页:https://lixsp11.github.io/sekai-project/
数据下载:https://huggingface.co/datasets/Lixsp11/Sekai-Project
项目代码:https://github.com/Lixsp11/sekai-codebase(@ 量子位)
5、B 站开源动漫视频生成模型 AniSora V3,一键生成多种风格动漫视频
Bilibili 开源的 AniSora V3 模型在动漫视频生成领域取得了显著进步。它支持一键生成多种风格的动漫视频镜头,包括番剧片段、国创动画、漫画视频改编和 VTuber 内容等。它基于 B 站之前开源的 CogVideoX - 5B 和 Wan2.1 - 14B 模型,结合强化学习与人类反馈(RLHF)技术,提高了视频视觉质量和动态效果。 通过时空掩码模块优化和数据集扩展,V3 版本在角色一致性和动作流畅度上达到了业界顶尖水平。
此外,新增对华为 Ascend910B NPU 的原生支持,推理速度提升约 20%,生成 4 秒高清视频仅需 2-3 分钟。这一模型的发布为动漫、漫画及 VTuber 内容创作者提供了更强大的工具,进一步降低了动漫创作的门槛。
链接:https://www.aibase.com/news/19480(@OneThingAI Lab、@ 达特智维 AI)
02 有亮点的产品
1、Pickle 团队开发开源隐形 AI 桌面助手 Glass:与 Cluely 功能高度相似
7 月 3 日,自称「数字克隆工厂」的 Pickle 公司在 X 平台宣布其开发了 Glass,这款开源免费产品与 Cluely 功能高度相似。
Glass 由 Pickle 团队开发,是一款开源的隐形 AI 桌面助手,能在后台默默捕捉你的屏幕和音频活动,并将这些内容实时转化为结构化信息,生成结构化知识。它的核心理念是:让 AI 隐形驻留于你的桌面系统中,悄然记录、理解并辅助你完成任务,极其适合会议记录、知识沉淀、实时总结等需求。
核心能力:
屏幕活动捕捉:自动监听并捕捉用户当前屏幕内容(非录像,仅用于上下文解析);
音频捕捉与识别:实时监听麦克风语音(如会议、讨论),自动生成高质量字幕与摘要;
上下文理解与总结:综合视觉 + 听觉信息,生成结构化笔记、知识卡片、任务清单;
实时问答助手:用户可以基于当下内容随时提问;
真正隐形设计:工具不会出现在 Dock、菜单栏、屏幕录制中,默默工作,零干扰。
GitHub 项目地址:https://github.com/pickle-com/glass
相关链接:https://x.com/leinadpark/status/1940826326052769949(@Z Potentials、@ 码农资源汇)
2、Figma 上市:pre-IPO 估值为 125 亿美元,目标募资最高 15 亿美元

2025年7月1日,以「云端协同设计」为核心理念的 SaaS 设计公司 Figma 向美国证交会递交招股书,并计划以股票代码「FIG」登陆纽交所,目标募资最高 15 亿美元(约合人民币 108.8 亿元)。二级市场显示 Figma 的 pre-IPO 估值为 125 亿美元,市销率达到 17.9 倍。若本次 IPO 成功,虽然和 Zoom、Snowflake 等 SaaS 大热门不能相提并论,金融业还是对其赋予厚望,认为 Figma 有可能超过年初的云计算公司 CoreWeave,成为 2025 年最大科技 IPO 黑马。
截止至 2025 年,Figma 的月活跃用户数已经超过 1300 万,拥趸中不乏微软、Slack、GitHub 等知名企业。活跃的用户群体,成为了 Figma 的核心竞争力。秉持「赋能创作者」的理念,Figma 在定价与服务上也打出了长期牌:保留个人免费版,团队企业版则按人头计费。适用于不同用户组织的灵活定价政策,也让设计师可以在不迁移数据的前提下一路升级到企业版,在无形中增强了用户粘性。
除此之外,Figma 也不拘于只做一个在线协作设计平台——今年 Figma 进一步将 AI 融入设计工作流。(@APPSO)
03 有态度的观点
1、李飞飞:AI 的未来在于空间智能,三维世界理解是 AGI 的关键
近日,Y Combinator 更新了李飞飞在旧金山 AI 创业学校的访谈视频。李飞飞回顾了自己从创办 ImageNet 到推动深度学习和物体识别发展的一路历程,并重点提到她如今正攻克 AI 领域最具挑战性的前沿技术——空间智能。
她在访谈中明确表示,空间智能将是下一个人工智能革命的关键领域,只有让 AI 理解三维世界,它才能真正迈向通用人工智能(AGI)。
李飞飞解释道,与语言模型的构建相比,空间智能的挑战更为复杂,因为人类对三维世界的感知能力相对较弱,然而她坚信,通过软硬件的融合与创新,这一难题是可以解决的。
李飞飞将 ImageNet 的诞生视为计算机视觉与深度学习领域的范式转变,而她现在的目标是通过攻克空间智能,继续引领人工智能的变革。她表示,AI 必须超越生成模型,进入三维世界的理解,才能真正实现 AGI。
至于 World Labs 的具体细节,李飞飞透露,目前不便公开过多,但她强调,空间智能的应用将与当前的大语言模型(LLMs)有显著区别,尤其是在推动元宇宙等新兴技术的实现过程中,3D 世界的感知将是不可或缺的一环。(@APPSO)
2、格莱美主席:AI 已重塑音乐创作,人类艺术家不可被取代
作为一位曾与碧昂丝和贾斯汀·比伯等顶级艺人合作过的资深制作人,梅森认为,AI 并非洪水猛兽,而是一种强大的工具,可以生成鼓点、和弦,甚至完整的歌词与旋律。
他指出,AI 的出现将颠覆传统的音乐创作流程,但也为艺术家打开了全新的表达空间,比如让无法再演唱的歌手通过 AI「复活」嗓音,继续创作与演出。
面对 AI 音乐创作日渐普及的现实,梅森提出几个核心担忧:首先是音乐版权归属不清,艺术家如何在 AI 再创作中获得应有的署名和报酬;其次是,AI 若主要基于对过去音乐数据的模仿生成,是否会削弱原创性,导致音乐审美「平均化」。
他表示,「我们必须确保 AI 创作内容是可被保护、可被盈利、可被识别的,否则最具创造力的音乐人将可能被边缘化。」
对于业界未来是否会设立专门的「AI 音乐格莱美奖」类别,梅森持开放态度,但强调「音乐就是音乐」。录音学院历史上从未按合成器或真实乐器划分奖项,而是始终鼓励一切形式的音乐创新。
在他看来,AI 不仅会加速歌曲创作和推荐系统的发展,还可能重塑「粉丝」与「创作者」的关系。未来的粉丝可能不再只是被动聆听,而是能主动参与创作——修改歌词、变换伴奏、甚至让偶像的 AI 分身为母亲唱生日歌。
对于未来是否会出现「非人类歌手」走红,梅森并不否认。他预测,AI 虚拟艺人一定会流行,但真正打动人心的,依然是那些有情感、有经验、有共鸣的人类音乐人。「AI 可以模仿技巧,但无法复制经历。」(@APPSO)

更多 Voice Agent 学习笔记:
语音能否彻底取代键盘?Wispr Flow 融资 3000 万美金背后的思考丨 Voice Agent 学习笔记
11Labs 增长负责人分享:企业级市场将从消费级或开发者切入丨 Voice Agent 学习笔记
实时多模态如何重塑未来交互?我们邀请 Gemini 解锁了 39 个实时互动新可能丨 Voice Agent 学习笔记
级联 vs 端到端、全双工、轮次检测、方言语种、商业模式…语音 AI 开发者都在关心什么?丨 Voice Agent 学习笔记
a16z 最新报告:AI 数字人应用层即将爆发,或将孕育数十亿美金市场丨 Voice Agent 学习笔记
a16z 合伙人:语音交互将成为 AI 应用公司最强大的突破口之一,巨头们在 B2C 市场已落后太多丨 Voice Agent 学习笔记
ElevenLabs 33 亿美元估值的秘密:技术驱动 + 用户导向的「小熊软糖」团队丨 Voice Agent 学习笔记
端侧 AI 时代,每台家居设备都可以是一个 AI Agent 丨 Voice Agent 学习笔记
世界最炙手可热的语音 AI 公司,举办了一场全球黑客松,冠军作品你可能已经看过
写在最后:
我们欢迎更多的小伙伴参与 「RTE 开发者日报」 内容的共创,感兴趣的朋友请通过开发者社区或公众号留言联系,记得报暗号「共创」。
对于任何反馈(包括但不限于内容上、形式上)我们不胜感激、并有小惊喜回馈,例如你希望从日报中看到哪些内容;自己推荐的信源、项目、话题、活动等;或者列举几个你喜欢看、平时常看的内容渠道;内容排版或呈现形式上有哪些可以改进的地方等。

素材来源官方媒体/网络新闻