自动化工具 接口自动化测试平台的迭代是一个关于成长的故事
作者简介
- 王满足,来自货拉拉/技术中心/质量保障部,从事质量效能平台方面的开发多年,目前主要负责部门基础设施平台与单元测试流程&精准测试的开发与建设工作。
- 钱振涛,来自货拉拉/技术中心/质量保障部,目前主要负责质量部门的效能工具和内部平台能力的建设工作。
前言
接口自动化测试平台的迭代是我们迈向技术成熟和高效开发的必经之路。在如今高速发展的互联网公司中,接口自动化测试平台已成为质量保障的核心支撑,特别是随着业务复杂度和规模的急剧增长,自动化测试成为保障项目稳定性和快速迭代的重要基石。本篇文章将重点讲述平台在迭代过程中遇到的挑战及我们是如何逐步攻克这些技术难题的。从应对多环境部署的难题,到显著提升测试效率和质量反馈,小标题均来自苏轼,分别来自苏轼不同人生时期的创作。当眉间少年走出大山,当平台诞生之后经历周遭变革,成长是永恒的主题,整体内容分为九章:
- 第一章 迭代背景:此生初饮庐山水
- 第二章 方案采集:当年踏月走东风
- 第三章 平台借力:自驾飞鸿跨九州
- 第四章 任务运行:浩浩长江赴沧海
- 第五章 稳定治理:魂惊汤火命如鸡
- 第六章 拆分提速:不问秋风强吹帽
- 第七章 报告呈现:觉来满眼是湖山
- 第八章 过去未来:人生所遇无不可
- 第九章 初心回归:此心安处是吾乡
第一章 迭代背景:此生初饮庐山水
有了自动化平台之后,我们陆续发现平台一些功能虽然有,但是如果优化之后,提效会很明显。之前虽然有水可以解渴,但是初次尝过庐山水之后,就对原来的水有更高的标准。我们在初次尝试过通过将接口自动化项目进行 Jar 包改造提速效果明显后,就对之前先构建再运行的模式感到焦急;初次体验过 Klov+ExtentReport 的自动化报告的现代化管理模式后,就对之前 Jenkins+TestNG 的组合感到哀伤;初次见识过自动化测试结合精准测试的受影响接口推荐和被测业务的链路图所展示的更为广阔的图景之后,就对之前孤立的自动化测试感到无助。
经过我们的迭代后,目前接口自动化平台的主要功能如下:
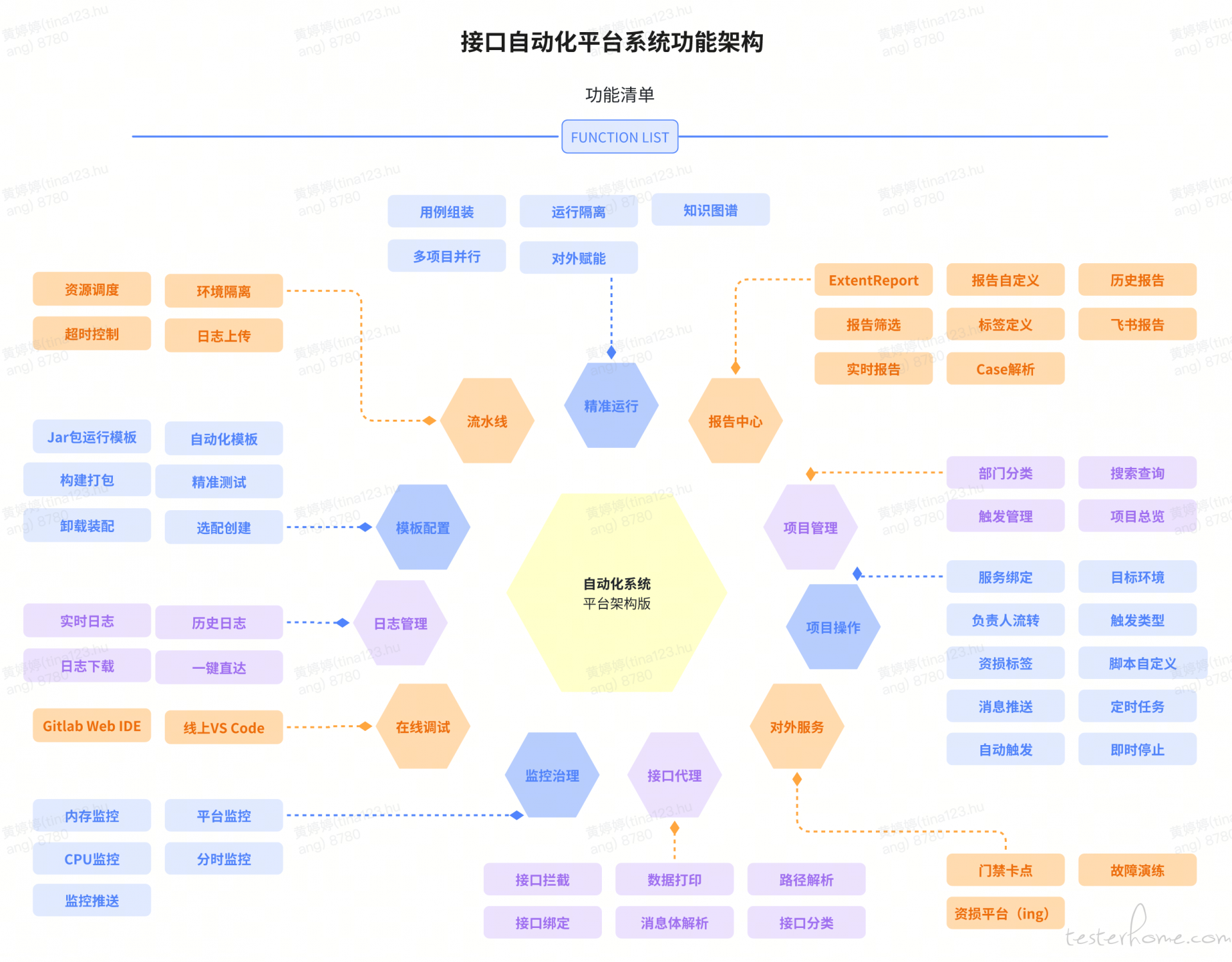
第二章 方案采集:当年踏月走东风
2.1 环境隔离问题:
在我们的项目中,需要同时支持两个完全不同的环境。第一个环境是与现有环境完全隔离的测试环境,网络被严格分割,无法直接打通。第二个环境是国外云提供的环境,涉及跨云部署。这种网络隔离对日常工作流造成了严重影响:
- 团队协作困难:测试团队无法在同一个环境中进行协作,导致工作流断裂,信息同步困难,很多问题在一个环境中解决后,还需要重新部署到另一个环境中进行重复测试,耗时耗力。
- 部署复杂性增加:跨云和网络隔离的问题导致现有的自动化平台无法轻易扩展到这些新环境中,团队需要耗费大量时间手动配置环境,重复部署工作,增加了部署的复杂性和出错率。
2.2 自动化运行提速的需求:
随着测试项目的规模扩大,自动化测试用例的数量激增,测试的运行时间也随之大幅增加。自动化测试项目原本设计用于较小规模的应用,但随着业务的扩展,测试任务的执行时间从原来的几十分钟延长到几个小时。这对生产发布的影响尤为严重:
- 上线延误:自动化测试逐渐成为项目上线的瓶颈,每次发布前都需要等待漫长的测试结果,导致发布周期不断延长,项目无法及时响应市场需求。
- 测试资源浪费:大量的冗余测试执行浪费了宝贵的测试资源,特别是在峰值时期,自动化测试结果迟迟无法反馈,严重影响了整个团队的工作进度。
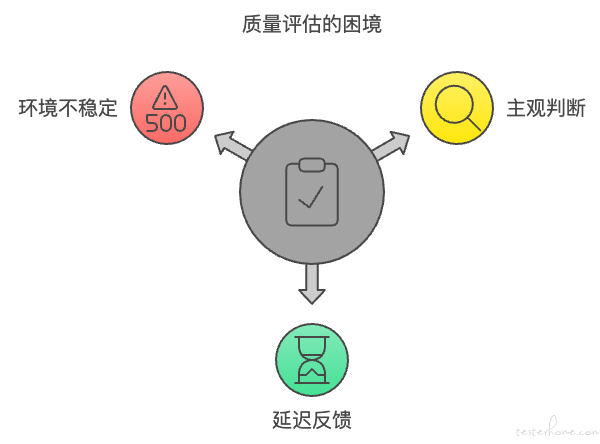
2.3 质量判定的困境:
自动化测试的质量评估成为了项目成功的关键之一。然而,随着测试用例的数量不断增加,如何准确、快速地评估测试的质量成为了一大难题:
- 主观性判断增加风险:过去依赖开发和测试人员通过手动分析测试结果来判断质量,这种方式不仅主观性强,而且容易出现误判,特别是在业务复杂度增加时,潜在的问题常常被忽视,直至问题影响到生产环境。
- 延迟反馈导致问题升级:由于没有实时反馈机制,测试完成后才能发现问题,这种延迟反馈的方式使得有时在上线后才会发现重大问题,进而导致紧急回滚和修复,增加了生产中的不稳定性。 通过深入分析这些问题,我们认识到,不解决这些根本性的瓶颈问题,自动化平台的有效性和效率就无法真正发挥作用。
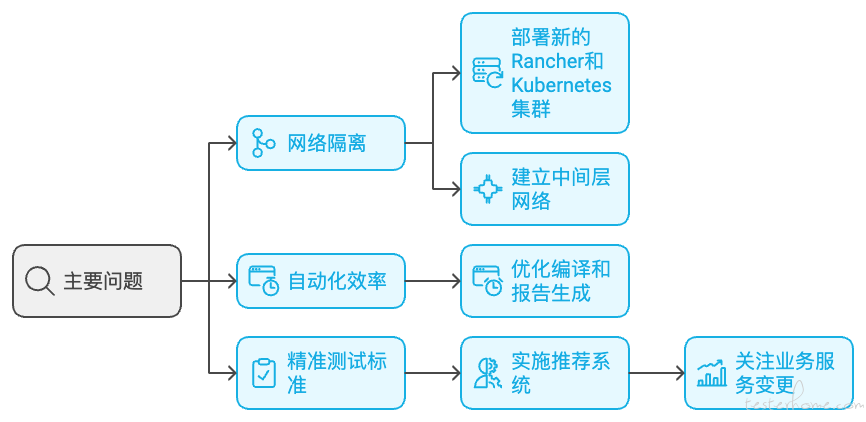
针对上述三个主要问题,我们根据自身情况进行了深入分析,通过方案调研、工具对比以及跨部门协作,最终确定了以下解决方案:
- 网络隔离问题的解决:对于无法打通网络的环境,我们部署了新的 Rancher 和 Kubernetes 集群,并将各类服务集成到新集群中。对于可以打通网络的环境,我们推动运维部门打通网络连接,随后将集群节点部署到主 Rancher 系统中,实现统一管理和调度。
- 自动化运行提速:原有的自动化流程包括编译构建、运行用例和报告生成三步。我们在编译构建和报告生成两个阶段进行了优化,通过并行化和资源调度,将这两个环节的耗时从分钟级大幅缩短至秒级,显著提升了测试运行效率。
- 精准测试标准的建立:我们引入精准测试理念,通过分析代码变动,自动推荐受影响的接口,并要求对这些接口进行全量覆盖。精准测试的核心在于基于业务服务的变更范围进行覆盖,从而有效减少冗余测试,并确保自动化用例的精准性与及时性。此外,测试结果会在每次触发后即时生成并推送,大幅提高了反馈速度。
第三章 平台借力:自驾飞鸿跨九州
3.1 通过搭建集群扩展自动化平台受众:
由于货拉拉业务的多样性,我们在国内货运、国际化以及小拉等多个业务板块中,涉及到不同的业务环境,这些环境都是相互独立的。为了快速支持这些不同的业务,我们需要一种高效的方式来将现有集群能力快速复制到新环境中。
3.1.1 环境独立性与挑战:
货拉拉的业务线广泛,包括国内货运、国际化业务和小拉等独立板块。每个板块都有独立的业务需求、数据存储和 API 接口。这种独立性带来了部署和维护的复杂性,尤其在集群能力扩展时,如何快速在新业务环境中实现现有集群的能力是一个关键问题。
3.1.2 集群能力快速复制的需求:
为了更好地支持不同业务的独立发展,我们需要一种方法,可以将一套经过验证的集群架构和配置快速部署到其他业务环境中,以确保稳定性和高效性。目标是:
- 快速复制:能够在短时间内将现有的基础架构复制到新的环境。
- 一致性:确保不同环境中集群配置的稳定性和一致性,避免人为差异导致的故障。
- 弹性扩展:能够根据业务需求,灵活调整每个环境的集群资源,确保不同业务的资源利用最优。
3.1.3 整体效果:
通过这种集群能力的快速复制方案,我们可以大幅缩短新环境的部署时间,并确保每个业务线都能享受到一致的集群架构和性能支持。无论是国内货运、国际化还是小拉业务,集群能力的复制都能够快速响应业务扩展需求,确保系统的高效稳定运行。
3.2 使用准入准出流程提高自动化有效性:
在当前的准出阶段中,设置了严格的卡口机制,确保业务服务对应的接口自动化测试用例必须全部通过,才能进入发布流程。这种做法将编译打包和部署后的质量检查前置,利用准出阶段的自动化测试结果作为发布的硬性标准。通过这种方式,确保每次发布的服务版本都经过严格的自动化验证,从而大幅提升了发布的质量和稳定性,减少了潜在的生产问题和风险。

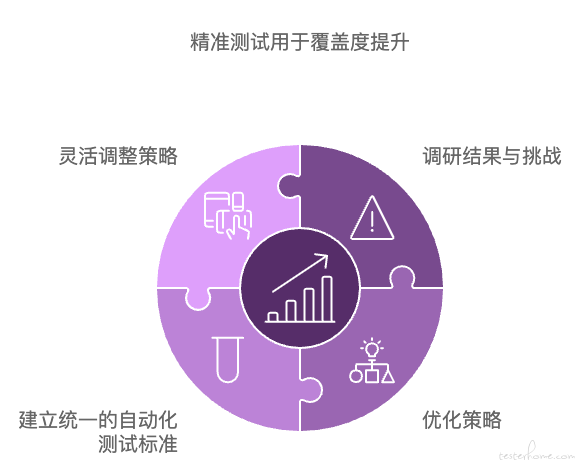
3.3 利用精准测试提高接口自动化覆盖度:
在经过广泛的调研和与一线公司的同行深入交流后,我们针对自身的情况进行了深入思考,并决定迭代优化接口自动化覆盖度,具体通过精准测试技术和思想进行提升。
优化思路:
- 调研结果与挑战:在一些公司中,精准测试的应用范围较为有限,主要用于缩短自动化测试的运行时间。这种方式往往适用于测试用例可以覆盖所有接口的场景,或用例之间关联性较低。然而,面对货拉拉所有业务线,各个部门的自动化建设进度和水平参差不齐。部分项目中,自动化用例的关联性较高,使用精准测试运行时,由于接口推荐的独立性,导致运行结果不理想。
- 优化策略:鉴于上述挑战,我们决定不完全照搬其他公司精准测试的方式,而是结合自身的需求,采用精准测试的技术和思想。首先,我们要建立统一的自动化测试标准,将各部门的自动化建设水平拉齐,确保所有业务线的基础自动化能力一致。其次,在面对用例关联性较高的项目时,我们灵活调整策略,避免单纯依赖推荐接口的独立性,而是根据实际情况优化测试用例的关联性处理。
3.4 凭借任务管理平台跟进用例完成:
通过任务管理平台对未覆盖接口的精准拦截与任务跟进,我们大大提升了接口自动化测试的闭环管理。当系统检测到某个接口未被测试用例覆盖时,平台会自动生成一条待办任务,提示测试人员需要补充该接口的自动化测试用例。该任务将列入工作流,确保及时跟进。
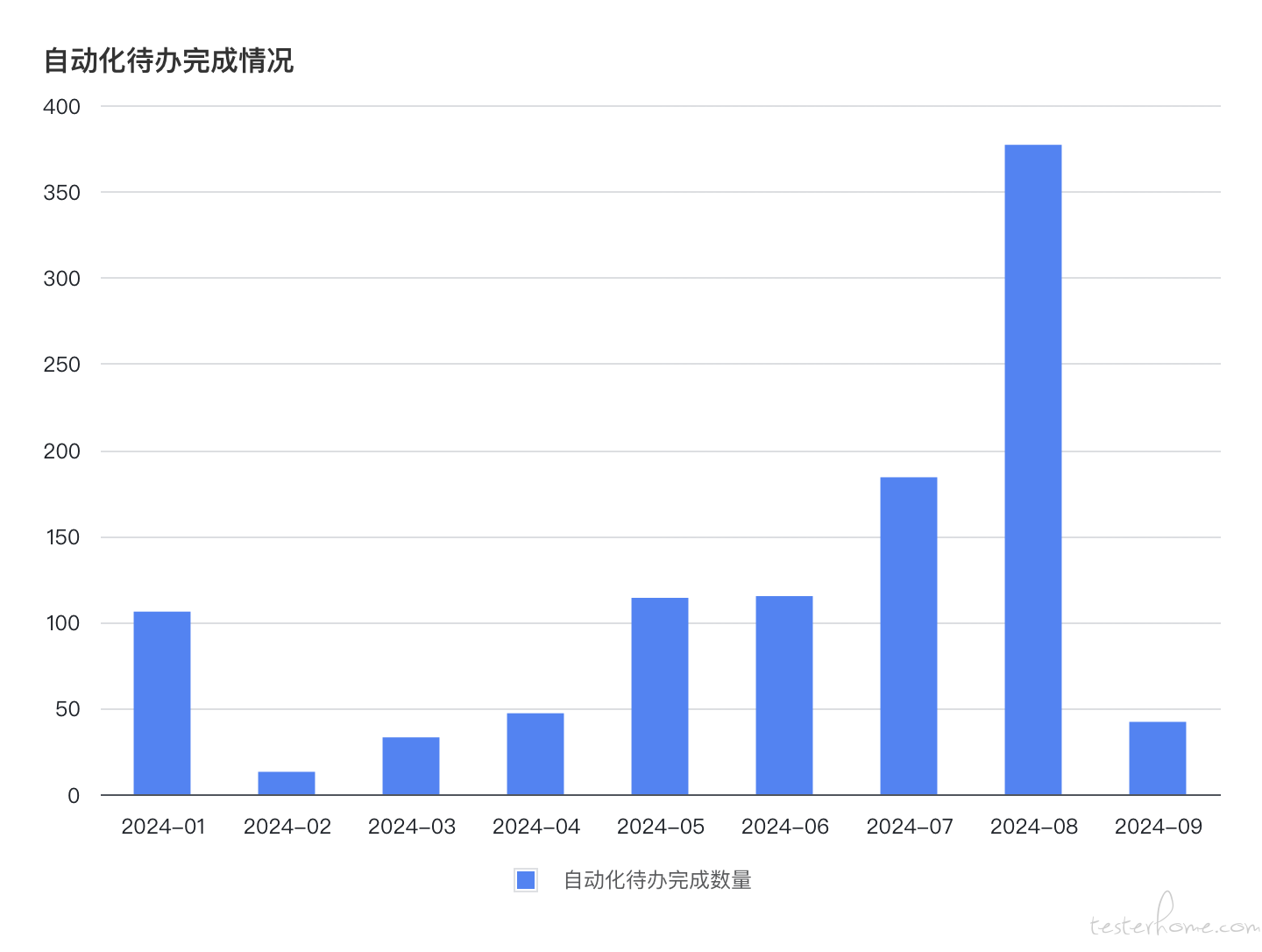
补充用例的过程也实现了自动化管理。当新的自动化测试用例补充完毕并提交后,平台会自动扫描该接口的状态,验证是否已覆盖到位。一旦确认覆盖,该待办任务将自动标记为完成,无需人工干预。这一流程不仅实现了任务跟踪的全自动化,还确保了测试覆盖的全面性和及时性,为自动化测试的高效管理奠定了坚实的基础。
最终,这种机制确保了每个接口的自动化用例都能快速补充并完成,2024 年度已累计完成 1000+ 自动化用例待办,极大地减少了人为疏漏的可能性,同时大幅提升了团队的工作效率和测试覆盖率。
第四章 任务运行:浩浩长江赴沧海
4.1 通过免构建的任务模板分发运行:
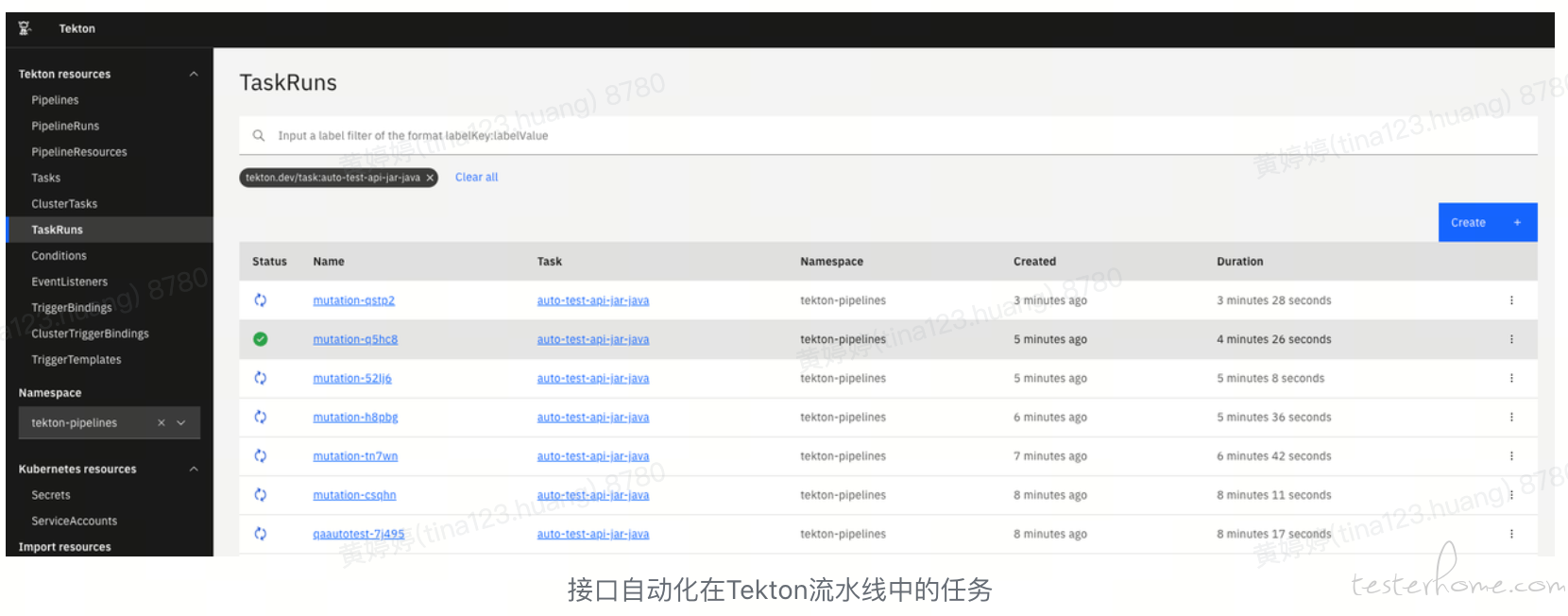
通过 Kubernete 的资源调度与 Tekton 的流水线任务分发,可以将自动化运行在相对隔离的容器环境中。相比于之前的自动化任务,新的任务模版如下,省去了构建步骤,从内部 OSS 快速 download 下另一个流水线任务准备好的构建产物,直接使用。
apiVersion: tekton.dev/v1beta1
kind: Task
metadata:
annotations:
name: "免构建版接口自动化-java"
name: auto-test-api-jar-java
namespace: tekton-pipelines
spec:
params:
- default: '#{gitId}'
description: gitId
name: gitId
type: string
- default: '#{commitId}'
description: commitId
name: commitId
type: string
- default: '#{appId}'
description: appId
name: appId
type: string
- default: '#{tektonId}'
description: tektonId
name: tektonId
type: string
resources:
inputs:
- name: maven-test
type: git
steps:
- image: 'harbor.xxxx.com/basic/maven-mitmproxy:api-jar-24070101'
script: |
#!/usr/bin/env bash
su -
start=`date +%s`
python3 /home/downloadJar.py $(params.repo) $(params.revision) | tee /workspace/maven-test/testNG.txt
python3 /home/transJar.py '$(params.script)' $(params.repo) $(params.revision) $(params.tektonId) | tee -a /workspace/maven-test/testNG.txt
end=`date +%s`
runtime=$((end-start))
if [ "$runtime" -gt 1199 ]
then echo "Job run more then 20min,please check your job" >> testNG.txt
fi
name: mvn-test
resources: {}
volumeMounts:
- mountPath: /root/.m2
name: m2
workingDir: /workspace/maven-test
- image: 'harbor.xxxx.com/basic/alpine:curl-jar-2024080701'
script: |
#!/usr/bin/env sh
python3 /run.py $(params.tektonId) $(params.appId)
python3 /upload_log.py $(params.tektonId)
name: klov-qaci
volumeMounts:
- mountPath: /root/.m2
name: m2
resources: {}
workingDir: /workspace/maven-test
volumes:
- hostPath:
path: /home/data/.m2
name: m2
workspaces:
- name: maven-test
日常的免构建版的接口自动化流水线任务运行场景如下:
4.2 用例的解析落库与灵活组装运行:
接口自动化用例原本自身是写在不同的仓库和分支中的,并非是由接口自动化平台数据库来存储。这样好处是各部门定制开发的自由,这样的坏处是在需要灵活运行场景中的不自由。如何继续保有原有的优势,又同时支持未来更多的运用场景,我们做了两个功能:
用例的解析落库:
通过在 ExtentTestNGIReporterListener 配置如下
public class ExtentTestNGIReporterListener implements IReporter, ITestListener {
private ExtentReports extent;
private List<TestData> testDataList = new ArrayList<>();
private String listenerName = getClass().getName();
private String suiteName;
private Integer tektonId;
private Integer switchNum;
private Date getTime(long millis) {
return new Date(millis);
}
@Override
public void onTestStart(ITestResult iTestResult) {
printTimeStamp("[START] " + iTestResult.getName());
System.out.println("Instance: " + iTestResult.getInstanceName());
testDataList.add(new TestData(
iTestResult.getName(),
iTestResult.getTestClass().getName(),
new Date(),
new Date(), // 初始化时,startDate 和 endDate 相同
listenerName,
suiteName,
tektonId
));
}
@Override
public void onTestSuccess(ITestResult iTestResult) {
printTimeStamp("[SUCCESS] " + iTestResult.getName());
String testName = iTestResult.getName();
testDataList.stream()
.filter(testData -> testData != null && testData.caseTestName.equals(testName))
.findFirst()
.ifPresent(testData -> testData.endDate = new Date().getTime());
}
@Override
public void onStart(ITestContext iTestContext) {
suiteName = iTestContext.getSuite().getName();
tektonId = Integer.parseInt(System.getProperty("tektonId", "0"));
switchNum = Integer.parseInt(System.getProperty("switchNum", "0"));
}
@Override
public void onFinish(ITestContext iTestContext) {
if (switchNum == 1) {
sendDataToBackend(testDataList);
}
}
private void sendDataToBackend(List<TestData> testDataList) {
System.out.println("将测试数据发送到后端:");
try {
HttpURLConnection conn = (HttpURLConnection) new URL("http://xxxxxx/exact/case/api/save/auto/case").openConnection();
conn.setDoOutput(true);
conn.setRequestMethod("POST");
conn.setRequestProperty("Content-Type", "application/json");
try (OutputStream os = conn.getOutputStream()) {
os.write(JSON.toJSONString(testDataList).getBytes());
}
} catch (Exception e) {
System.out.println(e.getMessage());
}
}
}
通过将以上 ExtentTestNGIReporterListener 引入到各个自动化项目中,可以在每次自动化运行时,可以将每个 Case 发送到自动化平台,对于我们的项目,通过 caseClassName 和 caseTestName 可以区分出不同的 Case,所以存储一份这样数据的过程,就实现了自动化用例的解析存储。
XML 配置文件动态生成
数据库中有了自动化 Case 数据,接下来就支持灵活的运行,我们的做法是:通过传入的 Case 数据,将其组装成为一个 XML 文件,然后指定运行此 XML 文件的 Case,生成的 XML 如下
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE suite SYSTEM "http://testng.org/testng-1.0.dtd">
<suite name="【乐高】自动化" verbose="1" parallel="classes" thread-count="10">
<test name="组装case重跑">
<classes>
<class name="com.huolala.qaautotest.TestCase.BfeCustomerApplicationQuerySvc.CommodityPriceFacade.ConfirmEvaluate">
<methods>
<include name="ConfirmEvaluate_001_001"/>
</methods>
</class>
</classes>
</test>
<listeners>
<listener class-name="com.huolala.qaautotest.utils.ExtentTestNGIReporterListener"/> </listeners>
</suite>
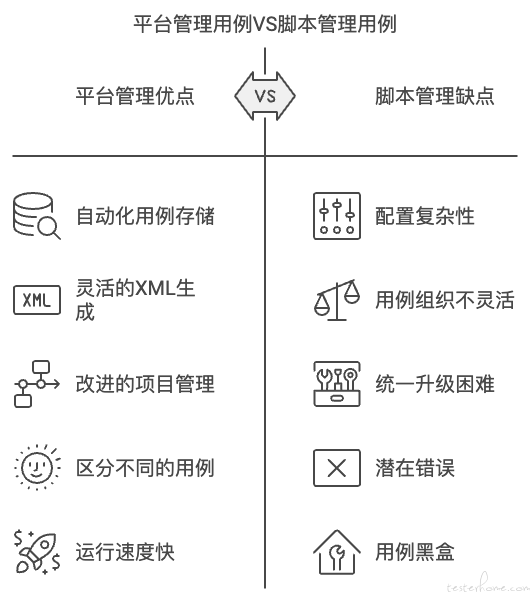
通过以上两块功能,就将原本自动化的代码仓库项目转换为一个平台管理项目。这样既有代码仓库的优点,又具有了类似其他公司完全在自动化平台上创建维护 Case 的优点。
这样改造之后,在故障演练平台的强弱依赖验证有了使用,应用如下:
在故障演练平台,需要配置对应验证流量 -- 找对应领域测试同学支持(可以由测试同学配置好,开发同学进行复用)
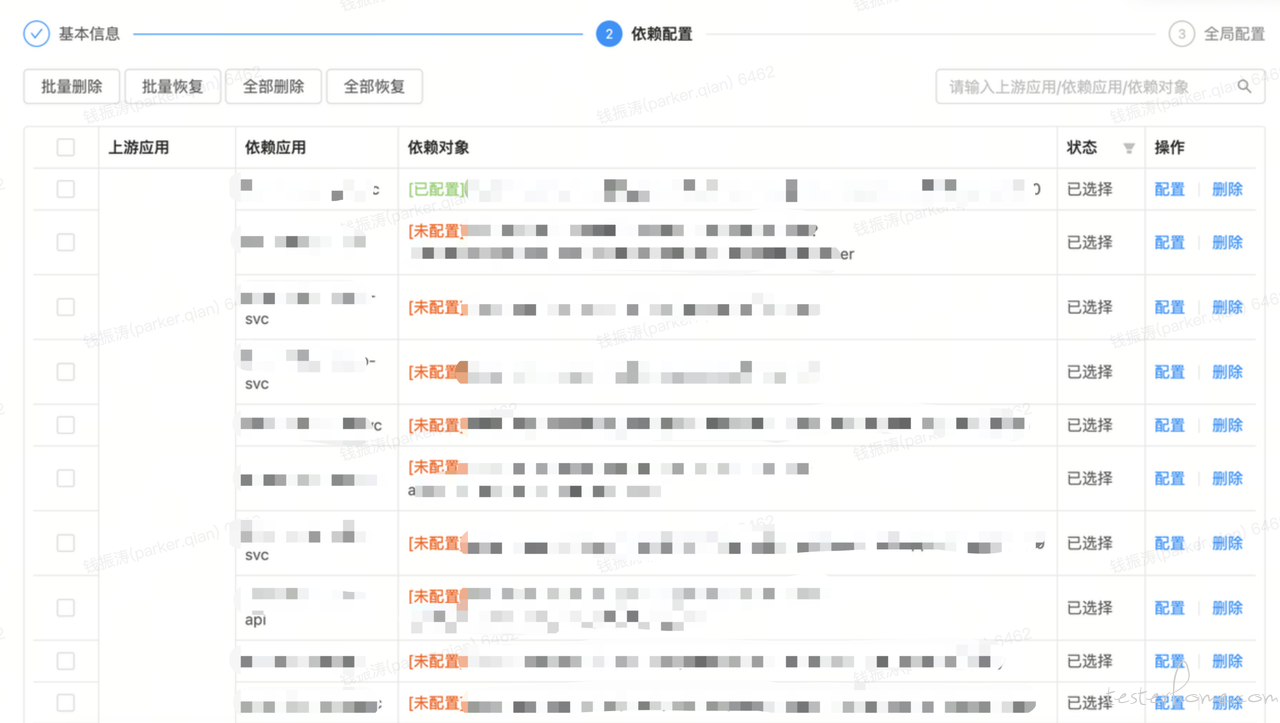
在其中的配置如下,通过搜索自动化用例的 ClassName 与 TestName 来灵活的组装成对应应用的用例集。
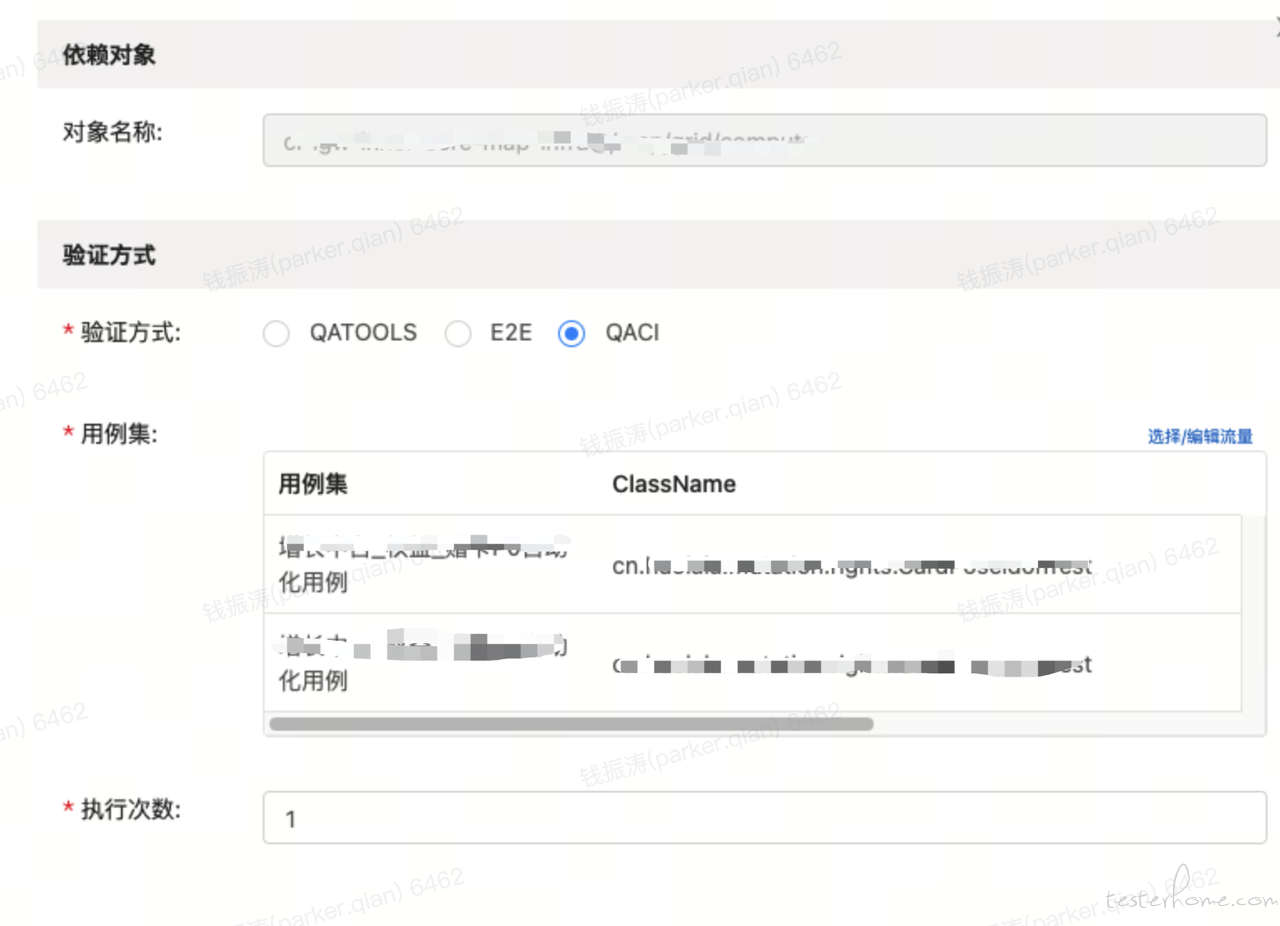
第五章 稳定治理:魂惊汤火命如鸡
在接口自动化测试的迭代过程中,问题响应是决定整个测试框架能否持续推进的关键。在此章中,将聚焦在历史过程中我们针对接口自动化所运行的 k8s 集群应急处理情况。
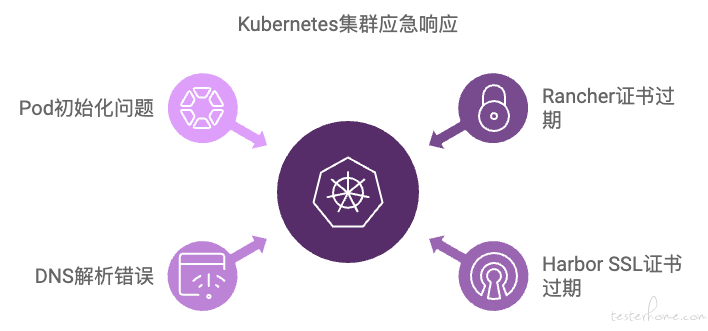
5.1 Rancher 证书过期导致集群不可用
- 问题描述:Rancher 的 UI 证书过期,导致整个集群无法使用,阻碍了自动化任务的正常运行。
- 解决方案:通过 Rancher 文档指导,轮换和更新证书,包括执行 OpenSSL 命令检查证书到期时间以及重新生成动态证书,并重启相关服务。具体参考Rancher Server 证书更新
5.2 Harbor 镜像仓库的 SSL 证书过期
- 问题描述:Harbor 服务的 SSL 证书过期,导致无法推送镜像。
- 解决方案:通过 OpenSSL 重新生成证书并重新配置 harbor-ingress 和 harbor-core 的密文内容 ,登录到各节点机器,替换 /etc/docker/certs.d/your.domain.com 下的 ca.crt 证书,确保镜像仓库恢复正常 具体证书命令生成参考如下:
openssl req -newkey rsa:4096 -nodes -sha256 -keyout ca.key -subj "/C=CN/ST=HB/O=QC/CN=your.domain.com" -x509 -days 3650 -out ca.crt
openssl req -x509 -new -nodes -key ca.key -subj "/C=CN/ST=HB/O=QC/CN=your.domain.com" -sha256 -days 100000 -out ca.crt
openssl req -newkey rsa:4096 -nodes -sha256 -keyout tls.key -subj "/C=CN/ST=HB/O=QC/CN=your.domain.com" -out tls.csr
openssl x509 -req -days 3650 -in tls.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out tls.crt
5.3 K8s 集群 DNS 解析错误
- 问题描述:由于节点机器网络重启导致集群内部 DNS 解析错误,影响了集群内的服务调用。
- 解决方案:禁用受影响节点的调度功能,重启 k8s 的 CoreDNS 服务,确保 CoreDNS 服务恢复正常后重新将问题节点机器加入到集群
5.4 Pod 状态异常,集群无可用 IP 分配
- 问题描述:Pod 启动之后一直处于初始化的状态,显示无可用 IP 分配。
- 解决方案:由于集群运行了很多定时任务的 pod,没有做及时的清理。通过脚本定时清理超过 10 小时 & 状态为 Completed& 名称以 trigger 开头的 pod
这些应急响应的实践证明了快速、有效的问题处理是保持系统稳定性和测试连续性的核心所在。同时,每次问题的解决也为后续集群的稳定性保障提供了宝贵的经验积累。
第六章 拆分提速:不问秋风强吹帽
6.1 执行方式的改造
随着项目代码量和测试用例的不断增加,传统的自动化测试执行方式在效率上遇到了瓶颈,尤其是在代码编译阶段,耗时过长成为制约测试速度的主要因素。针对这一问题,我们对自动化项目的执行方式进行了全面改造,以提升整体测试效率。
问题背景:
原先的执行流程是每次通过 Maven 拉取代码并进行编译,这种方式在项目初期可以满足需求,但随着项目代码的逐渐增多,编译时间不断增加,导致自动化测试的整体运行时间显著变长。
改造方案:
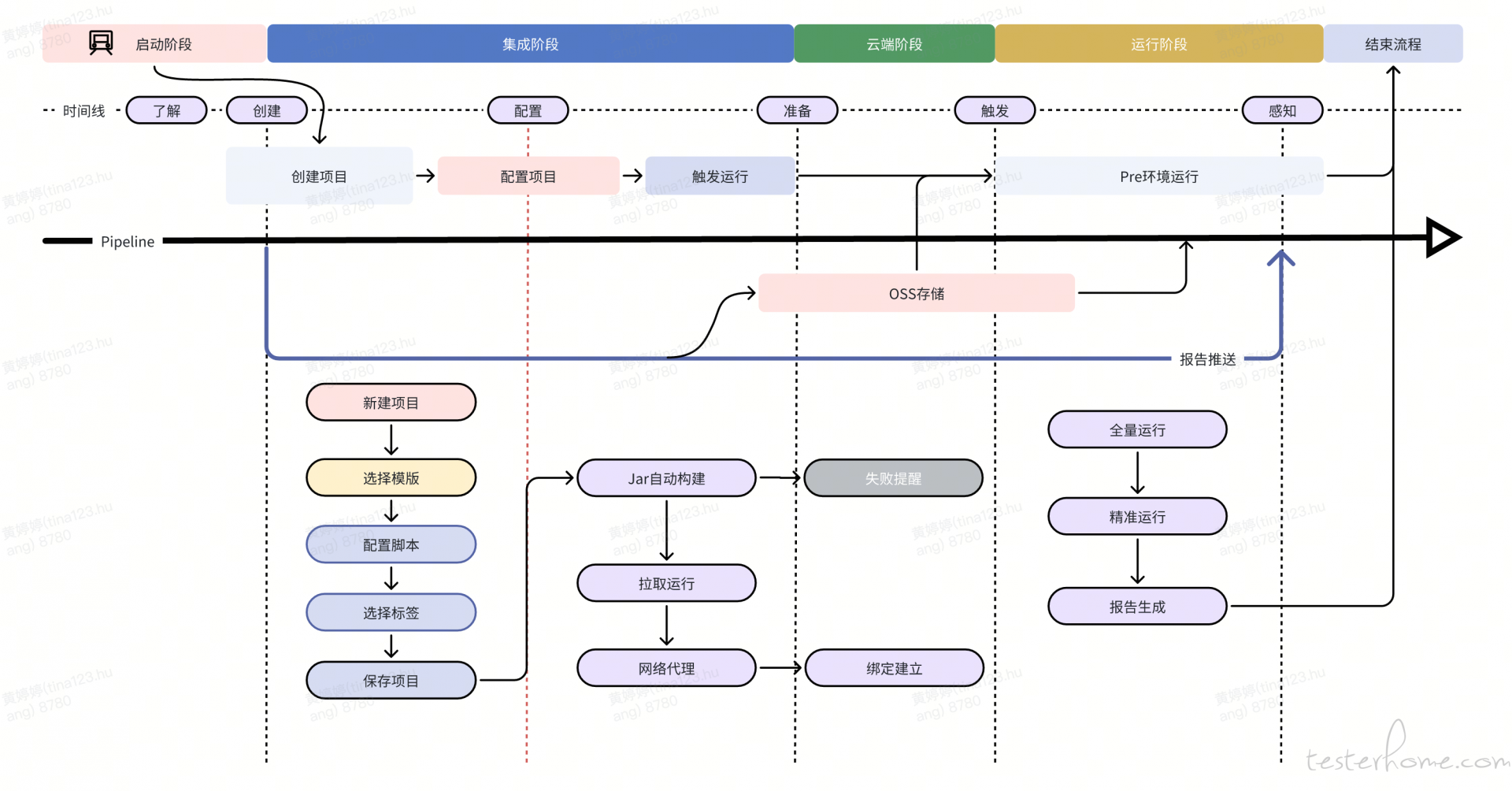
为了提高执行速度,我们对整个自动化项目的执行流程进行了重构,主要措施包括:
- 分支管理:所有自动化测试代码集中在一个 Git 仓库中,通过不同分支管理不同业务的自动化代码。
- Webhook 自动触发:配置 Webhook 监听代码提交,一旦有新的代码提交,立即触发自动化编译打包流程。
- 提前编译与打包:通过 CI/CD 流水线自动编译和打包代码,生成的 Jar 包根据项目和分支名进行命名,并上传到阿里云 OSS 进行存储。
- 拉取 jar 包并执行:在实际的接口自动化执行时,系统直接从阿里云 OSS 拉取已编译的 Jar 包,下载时间不超过 10 秒,从而跳过了运行时的编译步骤,直接执行已打包的测试代码。
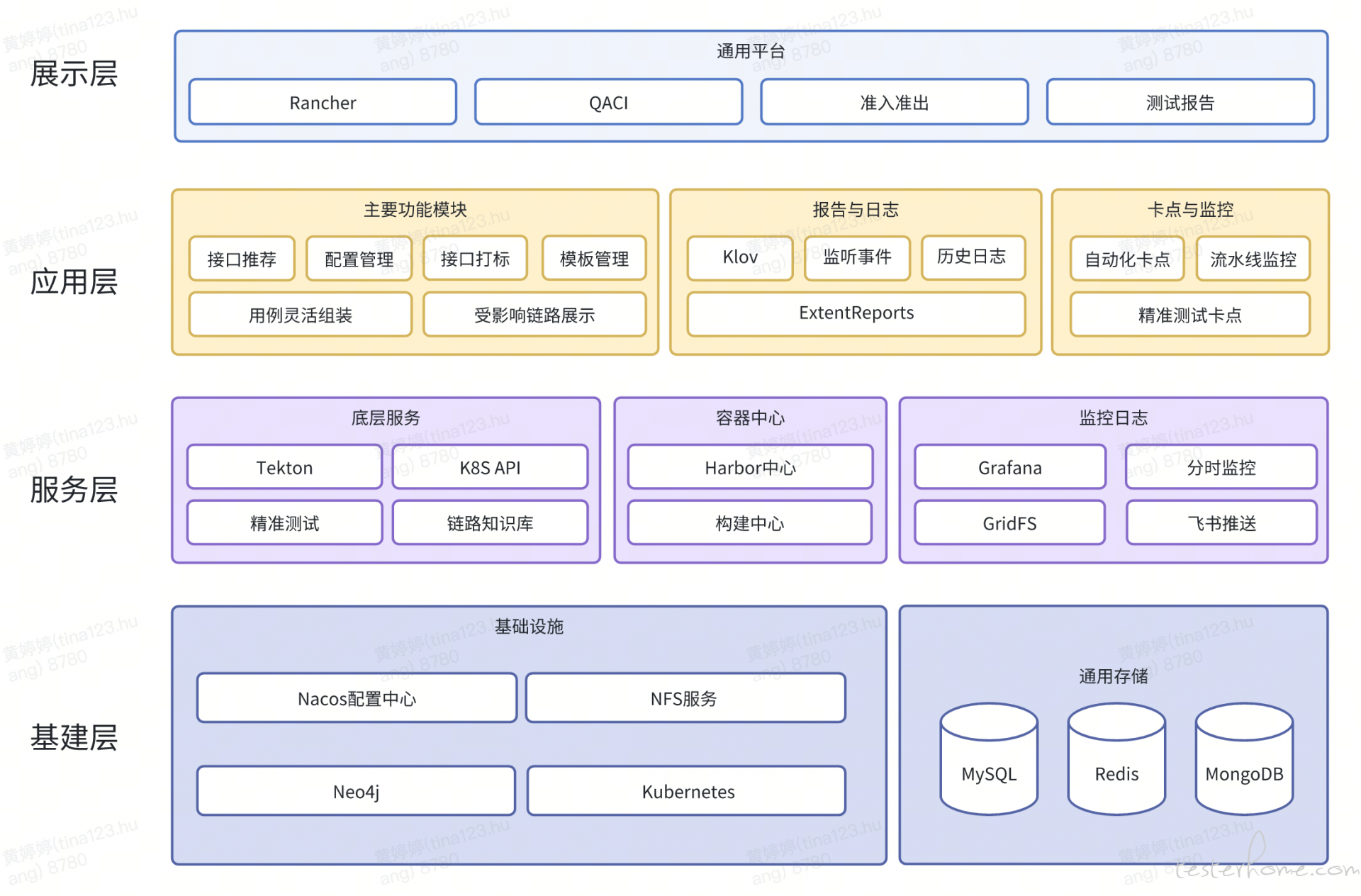
总体架构如图:
核心改动项:
a. 启动类和 manve 配置文件的修改
import org.testng.TestListenerAdapter;
import org.testng.TestNG;
import org.testng.xml.XmlClass;
import org.testng.xml.XmlInclude;
import org.testng.xml.XmlSuite;
import org.testng.xml.XmlTest;
import java.lang.reflect.InvocationTargetException;
import java.util.*;
public class QaautotestApplication {
public static void main(String[] args) {
try {
String xmlFilePath = System.getProperty("xmlFile");
TestNG tng = new TestNG();
// 如果指定了 XML 文件路径,则直接使用
if (xmlFilePath != null && !xmlFilePath.isEmpty()) {
tng.setTestSuites(Collections.singletonList(xmlFilePath));
} else {
// 动态构建测试套件
String tests = System.getProperty("test");
if (tests == null || tests.isEmpty()) {
System.out.println("No tests specified.");
return;
}
XmlSuite suite = new XmlSuite();
suite.setName("DynamicSuite");
XmlTest test = new XmlTest(suite);
test.setName("DynamicTest");
// 构建类和方法的映射
Map<String, XmlClass> classMap = new HashMap<>();
Arrays.stream(tests.split(",")).forEach(testInfo -> {
String[] parts = testInfo.split("#");
classMap.computeIfAbsent(parts[0], XmlClass::new)
.getIncludedMethods().add(new XmlInclude(parts[1]));
});
test.setXmlClasses(new ArrayList<>(classMap.values()));
tng.setXmlSuites(Collections.singletonList(suite));
}
tng.addListener(new TestListenerAdapter());
tng.run();
} catch (Exception e) {
e.printStackTrace();
Optional.ofNullable(e.getCause()).ifPresent(Throwable::printStackTrace);
}
}
}
b. 所有的测试用例需要存放在 src/main/java 下面 ,否则就打不进 jar 包,执行会报错
c. 相关的数据文件比如.json .yaml .csv 等需要放到 src/main/resources 目录下
d. 读取文件的时候使用 DataProviderXX.class.getClassLoader().getResourceAsStream(fileName) 的方式获取测试数据文件信息,使用这种读取测试数据文件的方式,是为了适应 Jar 包运行时的文件存储结构,确保文件可以被正确读取,提升了跨平台的兼容性,解决了在 Jar 包中无法直接通过文件路径读取资源的问题,并且提供了一种更加高效的文件加载方式。
提效成果:
通过这次改造,将原本运行时的编译过程前置,极大地缩短了测试运行时间。整体测试速度提升了 30%,这显著加快了反馈速度,提升了项目的迭代效率,确保了自动化测试的及时性和高效性。同时也支持指定用例的执行(单个或多个)

6.2 Klov 报告管理
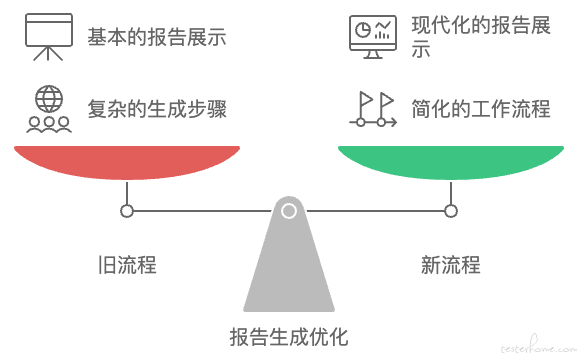
在早期的接口自动化测试中,测试报告的生成流程是基于当时的技术和需求设计的。采用 Jenkins 集成 TestNG 的插件生成报告,具有一定的优势:
- 优点:首先,Jenkins 作为成熟的 CI/CD 框架,TestNG 插件已经内置集成,操作简便。其次,报告管理集中,所有的测试报告都可以通过 Jenkins 统一管理。 然而,随着项目规模的扩大和时间的推移,原有的报告生成流程逐渐暴露出了一些问题:
- 生成流程繁琐:原先的流程要求先生成 TestNG 报告,再打包上传到 MinIO 服务器,随后触发 Jenkins 下载压缩文件并解析,整体步骤繁琐且耗时。
- TestNG 报告展示不美观:TestNG 自带的 HTML 报告相对简单,前端界面不够现代化,缺乏丰富的展示和数据分析功能。 由于这些问题,团队成员对这种繁琐的报告生成流程提出了许多改进建议。因此,我们对接口自动化测试报告的生成和管理进行了优化:
- 提升报告生成速度:在新的方案中,报告生成流程大幅简化。测试结束后,数据直接上传到 MongoDB,省去了原有的打包、上传下载、Jenkins 任务执行等中间环节,显著提升了生成速度。同时,不再生成 TestNG 的 HTML 报告,避免了文本文件的生成开销。
- 现代化的前端展示:通过 Klov 报告管理系统,直接从 MongoDB 中读取测试数据,并以现代化的前端界面展示,提供更美观、交互性更强的报告视图,使得测试结果更易于理解和分析。 综合来看,这次优化不仅简化了报告生成流程,提升了效率,还显著改善了报告的可视化效果,为团队提供了更高效、直观的测试反馈和管理工具。
核心 ExtentTestNGIReporterListener 改造
package com.huolala.qaautotest.utils;
import com.alibaba.fastjson.JSON;
import com.aventstack.extentreports.ExtentReports;
import com.aventstack.extentreports.ExtentTest;
import com.aventstack.extentreports.Status;
import com.aventstack.extentreports.reporter.KlovReporter;
import org.testng.*;
import org.testng.xml.XmlSuite;
import java.text.SimpleDateFormat;
import java.util.*;
public class ExtentTestNGIReporterListener implements IReporter, ITestListener {
private ExtentReports extent;
private String listenerName = getClass().getName();
private SimpleDateFormat dateFormat() {
return new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");
}
private void printTimeStamp(String desc) {
System.out.println("[" + dateFormat().format(new Date()) + "] " + desc);
}
@Override
public void generateReport(List<XmlSuite> xmlSuites, List<ISuite> suites, String outputDirectory) {
suites.forEach(suite -> {
Map<String, ISuiteResult> result = suite.getResults();
String docTitle = suite.getName();
String reportName = result.keySet().stream().findFirst().orElse("reportName");
init(docTitle, reportName);
int[] suiteStats = {0, 0, 0}; // {passSize, failSize, skipSize}
result.values().forEach(r -> {
ITestContext context = r.getTestContext();
ExtentTest resultNode = extent.createTest(suite.getName() + " : " + context.getName())
.assignCategory(suite.getName(), context.getName());
updateTestNode(resultNode, context, suiteStats);
buildTestNodes(resultNode, context.getFailedTests(), Status.FAIL);
buildTestNodes(resultNode, context.getSkippedTests(), Status.SKIP);
buildTestNodes(resultNode, context.getPassedTests(), Status.PASS);
});
if (suiteStats[1] > 0) {
extent.createTest(docTitle).log(Status.FAIL, String.format("Pass: %s ; Fail: %s ; Skip: %s", suiteStats[0], suiteStats[1], suiteStats[2]));
}
});
extent.flush();
}
private void init(String doc, String reportName) {
KlovReporter klovReporter = new KlovReporter();
klovReporter.initMongoDbConnection("auto-mongo.auto-qaci", 27017);
klovReporter.setProjectName(doc);
klovReporter.setReportName(reportName);
extent = new ExtentReports();
extent.attachReporter(klovReporter);
extent.setReportUsesManualConfiguration(true);
}
private void updateTestNode(ExtentTest resultNode, ITestContext context, int[] suiteStats) {
int passSize = context.getPassedTests().size();
int failSize = context.getFailedTests().size();
int skipSize = context.getSkippedTests().size();
suiteStats[0] += passSize;
suiteStats[1] += failSize;
suiteStats[2] += skipSize;
resultNode.getModel().setStartTime(context.getStartDate());
resultNode.getModel().setEndTime(context.getEndDate());
resultNode.getModel().setDescription(String.format("Pass: %s ; Fail: %s ; Skip: %s", passSize, failSize, skipSize));
if (failSize > 0) resultNode.getModel().setStatus(Status.FAIL);
}
private void buildTestNodes(ExtentTest extentTest, IResultMap tests, Status status) {
tests.getAllResults().forEach(result -> {
ExtentTest test = extent.createTest(result.getTestClass().getName() + "." + result.getMethod().getMethodName())
.assignCategory(result.getMethod().getGroups());
if (result.getThrowable() != null) {
test.log(status, result.getThrowable());
} else {
test.log(status, "Test " + status.toString().toLowerCase() + "ed");
}
Optional.ofNullable(result.getParameters())
.ifPresent(params -> test.log(status, "Parameters: " + JSON.toJSONString(params)));
Reporter.getOutput(result).forEach(test::debug);
test.getModel().setStartTime(new Date(result.getStartMillis()));
test.getModel().setEndTime(new Date(result.getEndMillis()));
});
}
@Override
public void onTestFailure(ITestResult iTestResult) {
printTimeStamp("[FAILURE] " + iTestResult.getName());
}
@Override
public void onTestSkipped(ITestResult iTestResult) {
printTimeStamp("[SKIPPED] " + iTestResult.getName());
}
@Override
public void onTestFailedButWithinSuccessPercentage(ITestResult iTestResult) {
// No-op
}
}
第七章 报告呈现:觉来满眼是湖山
原本的报告是 Jenkins+TestNG 的组合,这样的方式一方面比较慢,另一方面报告的呈现方式比较原生。我们做的迭代是:通过引入 Klov + ExtentReports,不仅优化了报告生成的流程,显著提升了效率,同时通过现代化的报告呈现与集中管理,使得测试反馈更加及时、直观,极大地提升了开发和测试人员的体验。

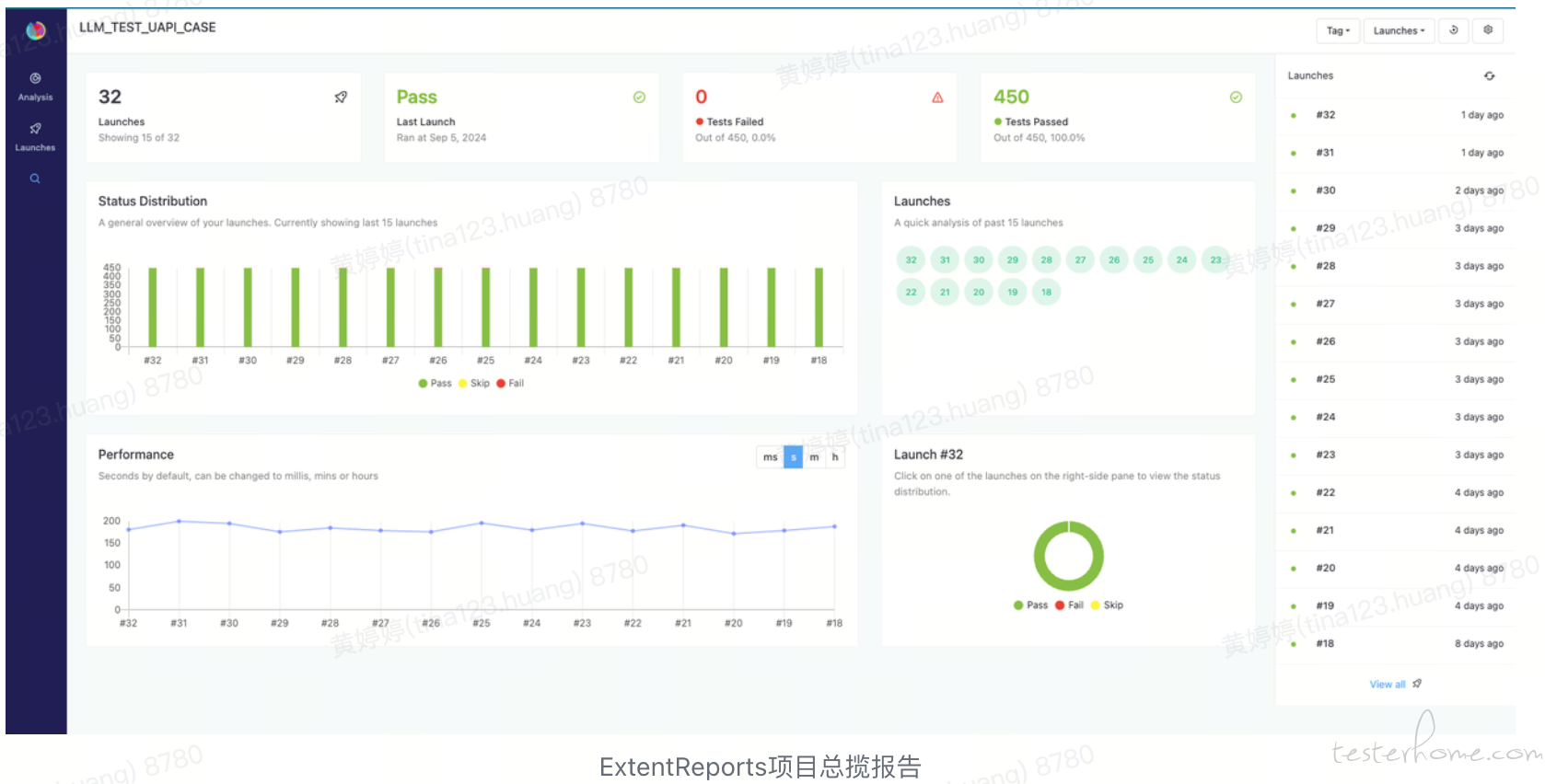
从设计语言和用户界面 (UI) 的角度来看,ExtentReports 的报告页面与 Jenkins+TestNG 原生报告相比具有几个明显的优势:
视觉层次感:ExtentReports 使用清晰的分区和颜色编码来增强报告的可读性和易用性。
-
信息可视化:
- 图表使用:ExtentReports 在展示测试数据时广泛使用图表和图形,如柱状图、饼图和线图。这些图表不仅美观,还使得趋势分析、性能度量和状态分布一目了然,提供了更高层次的数据摘要。
-
动态交互性:用户可以交互式地探索数据,比如点击某个图表获取更多详细信息,这种交互性在许多基本的 Jenkins+TestNG 报告中通常是缺乏的。
-
布局和结构:
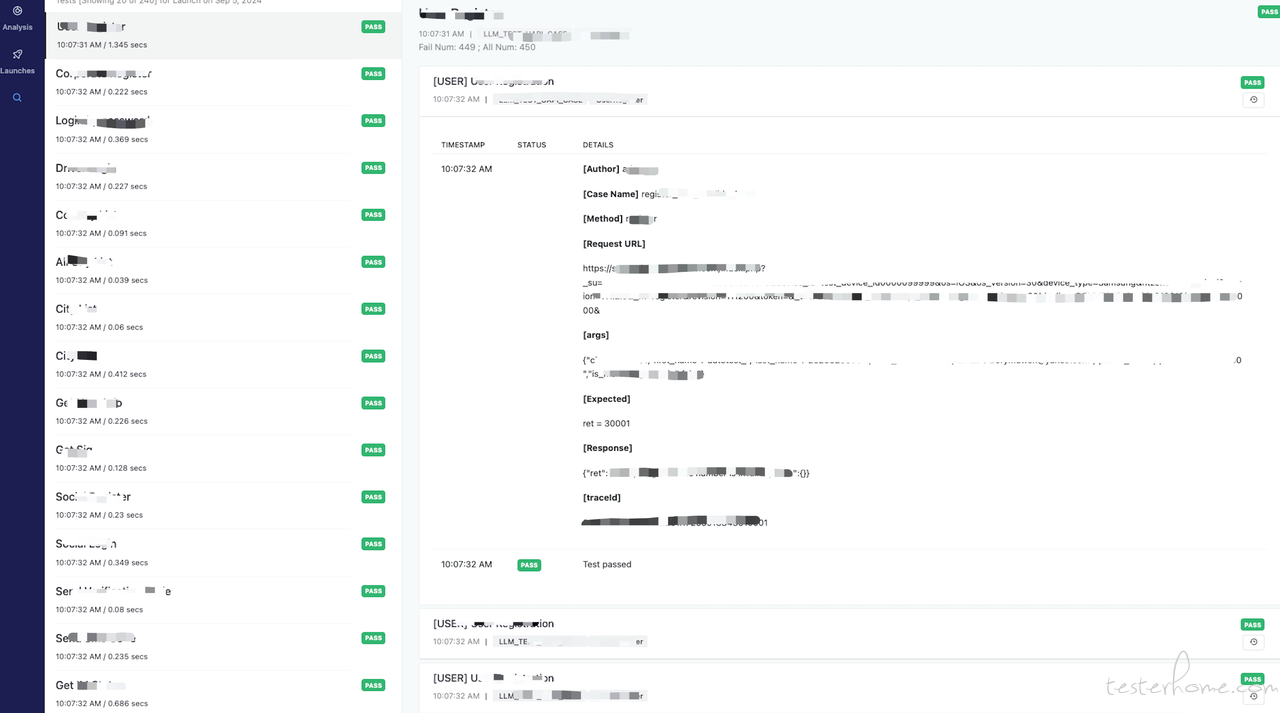
- 清晰的导航:界面顶部的导航和侧边栏清晰地展示了不同的分析和日志选项,用户可以轻松切换查看不同的视图和数据,而 Jenkins+TestNG 的报告通常更为静态和线性,没有这样的导航功能。
-
信息分组:通过有效地分组展示信息,如将启动统计、状态分布和性能数据分开展示,帮助用户避免信息过载,更快捷地找到他们需要的数据。
-
美学和用户体验:
- 现代化的界面设计:ExtentReports 提供一个现代化、响应式的界面设计,使用了平滑的动画和过渡效果,这提升了整体的用户体验。
总体来说,ExtentReports 通过其高度优化和用户友好的设计,提供了一个不仅美观而且功能强大的环境,以视觉和结构上优于传统 Jenkins+TestNG 的报告方式。这种设计改进使得报告不仅仅是信息的展示,更是一个交互式的分析工具,能够帮助团队更有效地理解和使用他们的测试数据。
第八章 过去未来:人生所遇无不可
自动化平台自诞生以来,经历了无数寒冬与酷暑,它的发展历程宛如位于上海原法租界的悬铃木,这些古老的树木见证了中国近现代的风云变迁。年复一年,无论是严冬还是盛夏,悬铃木都能按时抽枝发芽,繁叶成荫,持续而稳定的成长,正如自动化平台在技术潮流中不断进化。
以前所遇:
思维难点:
如何在有历史包袱的背景下既要又要?
我们原有的自动化项目已经很多,都是在通过代码仓库来管理脚本,而且通过此种方式已经运行了很长一段时间。之前平台的演化方式也是针对脚本类的自动化项目的方向去设计的。所以如何在有巨大的历史惯性下进行转型,相比于从一张白纸上进行设计,要难很多。相比于通过数据库来管理自动化,通过脚本来管理自动化的方式主要的劣势在于,自动化运行速度与用例组织的灵活性。我们针对自己已经存在的现状,想出了如下两步,并进行了实施,既保有了原有的通过脚本来管理自动化的方式的开源框架自带的功能的丰富性和本地调试方便,又具有了通过数据库来管理自动化用例类平台相同的优势。
编译提速改造:之前 mvn -U clean test 自身包含的先 compile 在 test 步骤,转换为了在 test 之前就直接获取 compile 好的产物,所以在自动化过程中就省去了之前每次都需要的 compile 耗时操作
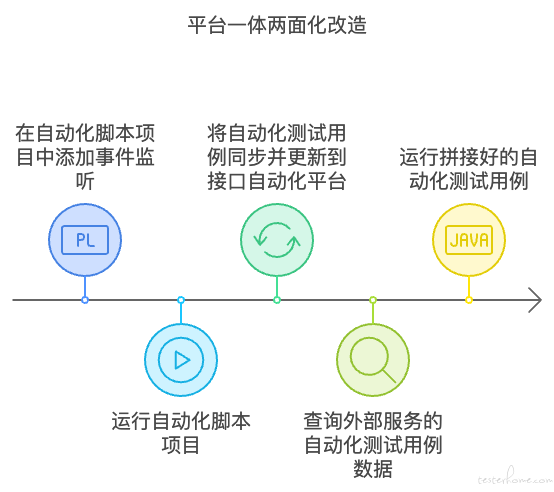
一体两面化改造:
无需重新在平台创建用例,只需要在自动化脚本中增加监听事件,用例在运行期间会在自动化平台自动落库并更新,实现了用例的平台化。此时可以支持外部服务查询自动化用例数据,同时运行灵活拼接好的自动化用例。
技术难点:
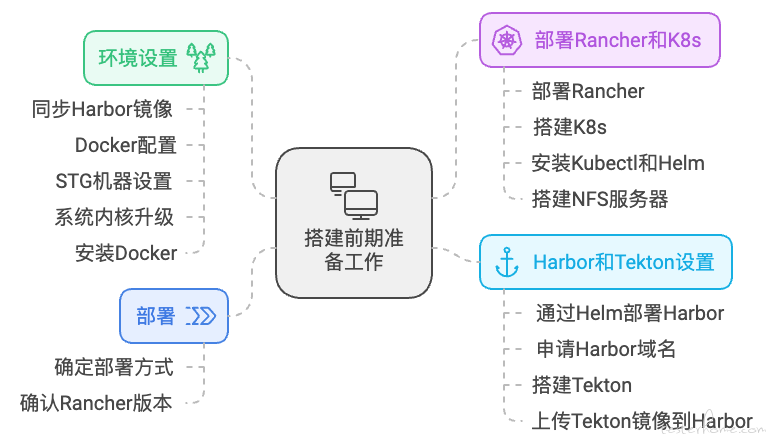
小拉集群搭建步骤复杂,环环相扣,分为了前、中、后三期来完成的搭建。
搭建前期:前期主要搭建 Kubernetes 集群,同时包含了 Rancher、Harbor、NFS 等相关底层基础设施的搭建。
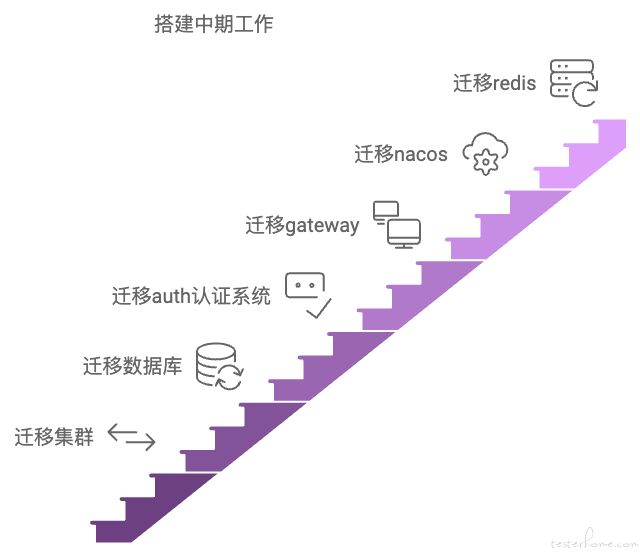
搭建中期:搭建中期主要对接口自动化测试平台中的微服务集群进行了搭建,接口自动化平台服务基于 Spring Cloud 来进行的微服务设计,涉及了多种微服务中的中间件。
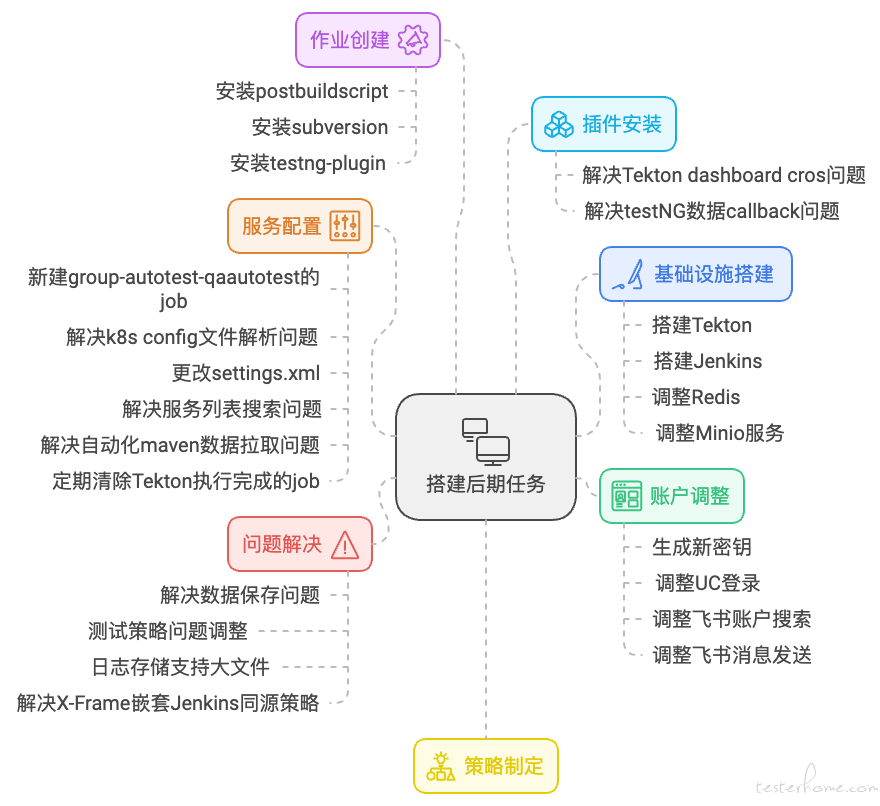
搭建后期:底层基础设施和微服务搭建好之后,若干的流水线任务,和服务配置信息需要调,都需要进行配置以及问题的解决。
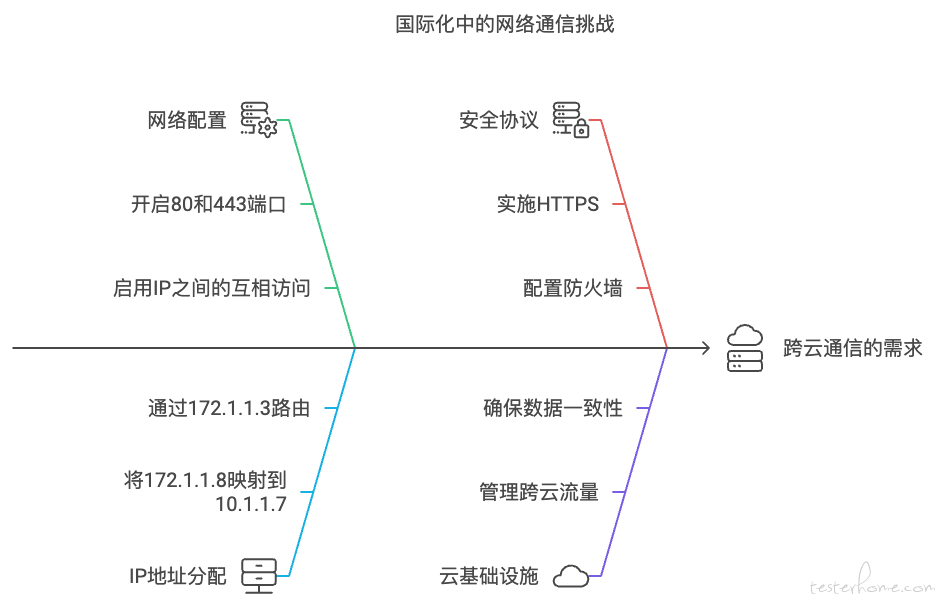
针对国际化的问题,需要设计一台中间的跳板机,作为跳板进行网络的跨云的通信:
治理难点:
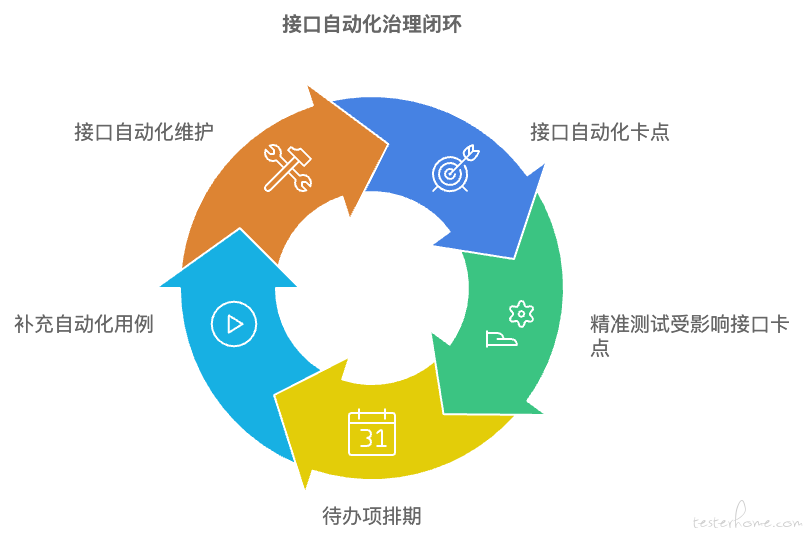
接口自动化的运行之前缺少一条统一的标准,缺少标准也就无从治理。我们通过 “双卡双待” 来实现自动化治理闭环:
双卡:
接口自动化自身卡口:治理目标在自动化用例维护。
精准测试受影响接口卡口:治理目标在增加自动化用例,同时关注点放到被测服务。
双待:
接口自动化待办项:治理目标在任务管理,工时分配。完成治理闭环。
流量回放待办项:治理目标是推广流量回放,丰富接口保障手段。
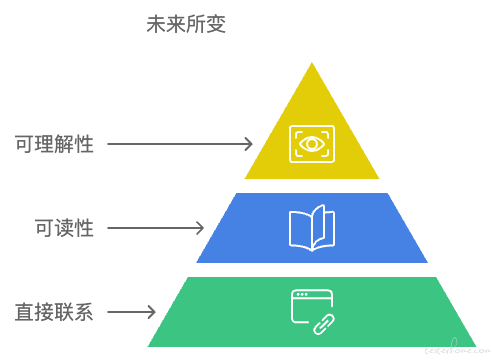
未来所变:
- 自动化用例与业务服务代码之间建立直观联系
- 这种直观联系可阅读可理解
- 阅读者对这种联系的理解程度可以评估
第九章 初心回归:此心安处是吾乡
接口自动化测试既是自动化测试领域的母题又是精神故乡。诸多专项实践是从接口自动化测试的思想中孕育,无论走多远都始终带有接口自动化测试的影子。写到最后,接口自动化测试开始在我脑中有了一个具体的形象,正如《麦田里的守望者》中那样的描述:
“那些孩子在一大块麦田里做游戏。几千万个小孩子,附近没有一个人——没有一个大人,我是说——除了我,我呢?就站在那个混账的悬崖边。我的职责是在那儿守望,要是有哪个孩子往悬崖边奔来,我就把他捉住——我是说孩子们都在狂奔,也不知道自己是在往哪儿跑,我得从什么地方出来,把他们捉住。我整天就干这样的事儿。我只想当个麦田里的守望者。”