专栏文章 我们是如何测试人工智能的(八)包含大模型的企业级智能客服系统拆解与测试方法 -- 大模型 RAG
大模型的缺陷 -- 幻觉
接触过 GPT 这样的大模型产品的同学应该都知道大模型的强大之处, 很多人都应该调戏过 GPT,跟 GPT 聊很多的天。 作为一个面向大众的对话机器人,GPT 明显是鹤立鸡群,在世界范围内还没有看到有能跟 GPT 扳手腕的存在。 也许很多人都认为 GPT 是非常强大的对话机器人了, 它学时丰富,什么领域内的问题都能回答。但其实就如我上一篇帖子中说道的, 虽然这种大模型看似什么问题都能回答,但其实它无法在特定领域内给出专业且精准的回答。比如我们问大模型宝马 5 系的发动机的设计细节,这个是不可能得到正确的答案的。 甚至我们问一个大模型苹果今天的股价是多少,它也是回答不出来的。 如下图:

这是为什么呢, 看过我之前教程的同学就知道人工智能是你给它什么样的数据,它就训练出什么样的效果。 所以大模型可以根据海量的训练数据,找出数据之间的规律从而推理出用户想要的答案。 但这个答案涉及的知识范围无法脱离训练数据的基础。 也就是说大模型可以根据训练数据得出人类的语言习惯,内容组织的方式, 它知道输出什么样的内容是人类容易理解的, 但是它自己掌握的知识范围没办法超出训练数据包含的范围。 所以用户在限定的知识范围内提出的问题,大模型可以给出近乎完美的答案。但超出了这个范围它就无能为力了,如果是比较容易识别的场景会得出上面那样的回复,这样起码用户会知道大模型无法回答这个问题。 但更多的场景下可能会出现大模型的幻觉问题。
幻觉用大白话来说就是模型在瞎编一个答案。 比如我在问 GPT 一个代码问题的时候,其实会发现有些时候它会瞎编一些不存在的函数出来。为什么会出现这种问题, 这就要涉及到它的训练原理了。 我在之前的教程中说过所有监督学习基本上都逃不开二分类,多分类和回归这三种类型。 而大模型其实就可以划分为一个多分类模型。 因为实际上它的原理是有我们有一个词表,这个词表里包含了这个语言的大部分常用词,比如是中文的词表的话可能包含了绝大部分的中文字。而模型实际上在生成答案的时候就是使用用户的问题去计算生成的第一个字应该是哪个字,词表中每一个词都会计算一个概率, 比如词表中一共有 1w 个字,模型就会去计算这 1w 个字中,每个字出现在当前位置上的概率,取概率最高的那个输出。 然后模型再用问题 + 生成的第一个字 为基础又去词表中计算第二个字,以此类推。所以对于大模型本身来说它并不知道绝对的正确答案是什么,它只是在会在词表中取出概率最高的那个字。 所以用户才会感觉到大模型总是在瞎编一个答案。
说回对话机器人中的意图识别
大模型的幻觉是无法避免的,起码靠大模型自己是无法避免的, 就像上面说的, 它并不知道真实的答案, 它只是去猜一个它认为最靠谱的答案给用户。 所以说回上一篇中提到的,对话机器人一般会在最前方设定一个多分类的模型,名为意图识别模型。 它的责任就是根据用户的问题去计算出应该由哪个子系统来回答用户的问题。 这正是因为我们知道很多问题是大模型无法回答的。 它没有专业的知识(比如你问宝马 5 系的发动机要如何更换,它需要到知识引擎中检索对应文档),或者无法回答实时变动的问题(比如苹果今天的股价是多少, 它需要发送到搜索引擎中检索答案)。 所以一个看似简单的客服对话机器人,实际上是一个非常庞大的系统,它背后是非常多的子系统的模型共同弄支撑起来的。 而测试人员往往第一个就要测试这个意图识别模型,它的这个多分类效果是否达到了足够高的标准,因为这个意图识别错了, 它就会发送到错误的子系统中,那么答案也一定就是错误的。
大模型 RAG
当我们了解了大模型的局限性后,又要开始面对另一个问题。 就是通过知识引擎或者搜索引擎这些子系统检索出来的答案直接返回给用户可能也是有问题的。 比如:
- 信息过多:我们可能从检索结果中获得大量相关信息,用户难以从中筛选出最准确、最有用的部分。
- 信息不完整或不准确:检索结果可能只包含部分信息,或者由于搜索引擎的局限性,返回的信息可能不够准确。
- 缺乏连贯性或者不符合人类的理解习惯:直接返回的检索结果可能是一系列独立的片段,缺乏整体的连贯性和逻辑性,这会影响用户的理解和体验。
所以业界的专家们推出了一种把检索和大模型组合在一起的解决方案,也就是大模型 RAG(检索增强生成)。一句话总结:RAG(中文为检索增强生成)= 检索技术 + LLM 提示。例如,我们向大模型提一个问题,我们先从各种数据源检索相关的信息,并将检索到的信息和问题封装成 prompt 注入到大模型中,让大模型给出最终答案。比如:
【任务描述】
假如你是一个专业的客服机器人,请参考【背景知识】做出专业的回答。
【背景知识】
{content} // 数据检索得到的相关文本
【问题】
XX品牌的扫地机器人P10的续航时间是多久?
之前我们说大模型的缺点就是缺少专业领域和实时变化类型的相关知识信息。 所以它才会出现幻觉问题。 现在我们把这些专业知识封装到了 prompt 中,这样大模型就有了这些知识背景,就可以比较完美的回答出用户想要的答案了。
所以其实我们说对话机器人是一个比较复杂的系统,它背后有多个子系统,有多种模型服务。 但它的核心流程其实就是通过意图模型决定问题应该交由哪个子系统来处理, 然后把该子系统的答案封装进 prompt 里让大模型给出最终答案。 当然这其中还有很多流程, 比如安全审核,频控,拒答黑名单等等, 我们先不过多涉及这些细节。
测试人员利用大模型 RAG 进行效果的评估
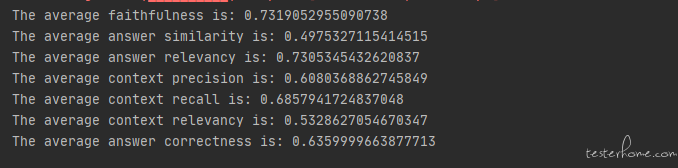
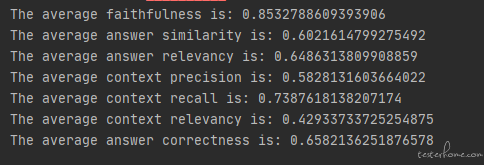
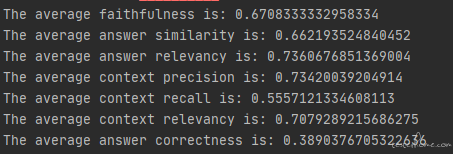
当我们了解到大模型 RAG 的原理后,其实也就猜到测试人员也是可以利用这个方法来开展一些工作的。在我以前的文章中介绍过这种大模型的评测工作是非常消耗人力的, 其中一个非常消耗人力的地方就是即便我们已经有了标注好的数据(就是问题和答案都是已知的),我们也很难去自动化的去测试。 这主要是因为比较难以去自动化的对比参考答案与实际答案之间的匹配程度,因为对话机器人每次回答的内容可能是不一样的,而且回答的内容不一样不代表回答的就错误,语言这个东西是博大精深的(尤其是汉语),不同的描述表达同一个意思是比较常见的,比如我的名字叫孙高飞 和 孙高飞是我的名字 其实表达的是差不多的意思。 所以不能简单的用字符串匹配来验证回答的正确性。 常见的思路可能是引入文本相似度算法,比如把两个文本向量化后计算余弦相似度。 这样一定程度上可以从语义的角度来分析两个文本的相似程度。 就是开源的这种语义相似度的算法效果确实需要在项目中去实践验证。 第二种思路就是一些测试人员习惯让 GPT 来完成这个工作, 我们可以把相关的问题,参考答案以及模型给出的答案封装成 prompt,让 gpt 来评判回答质量,比如:
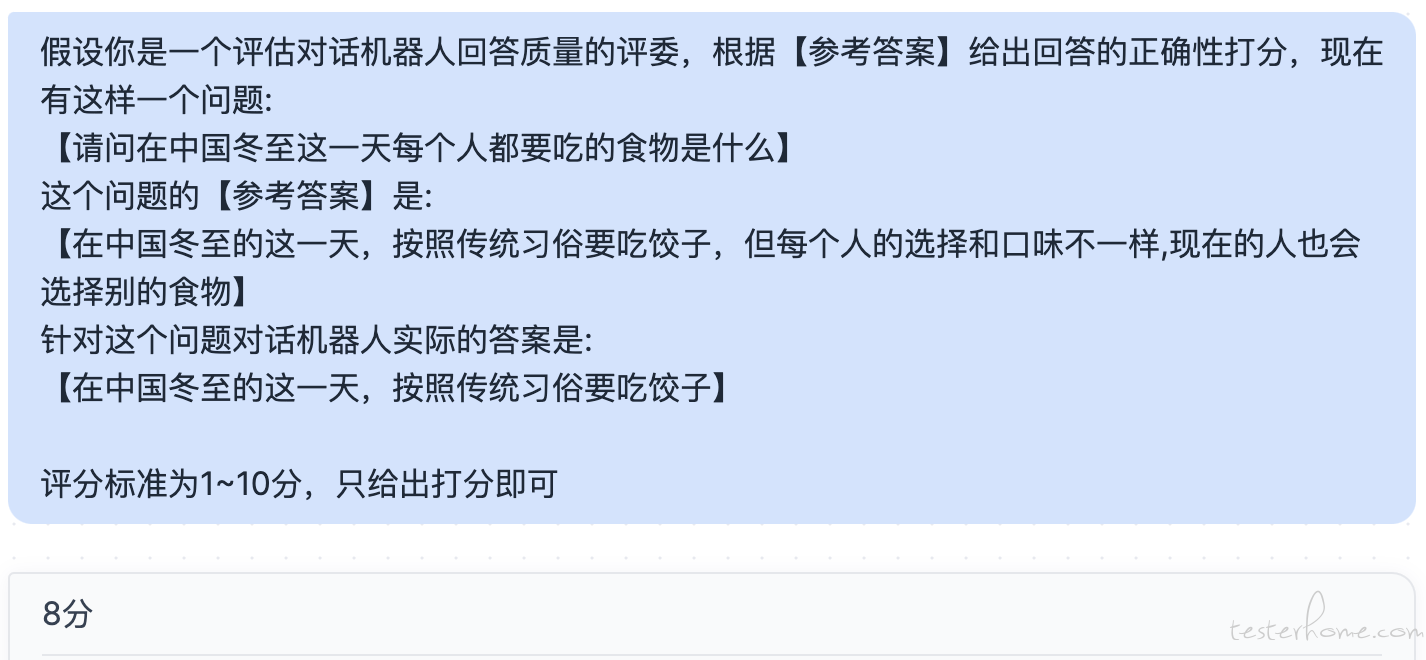
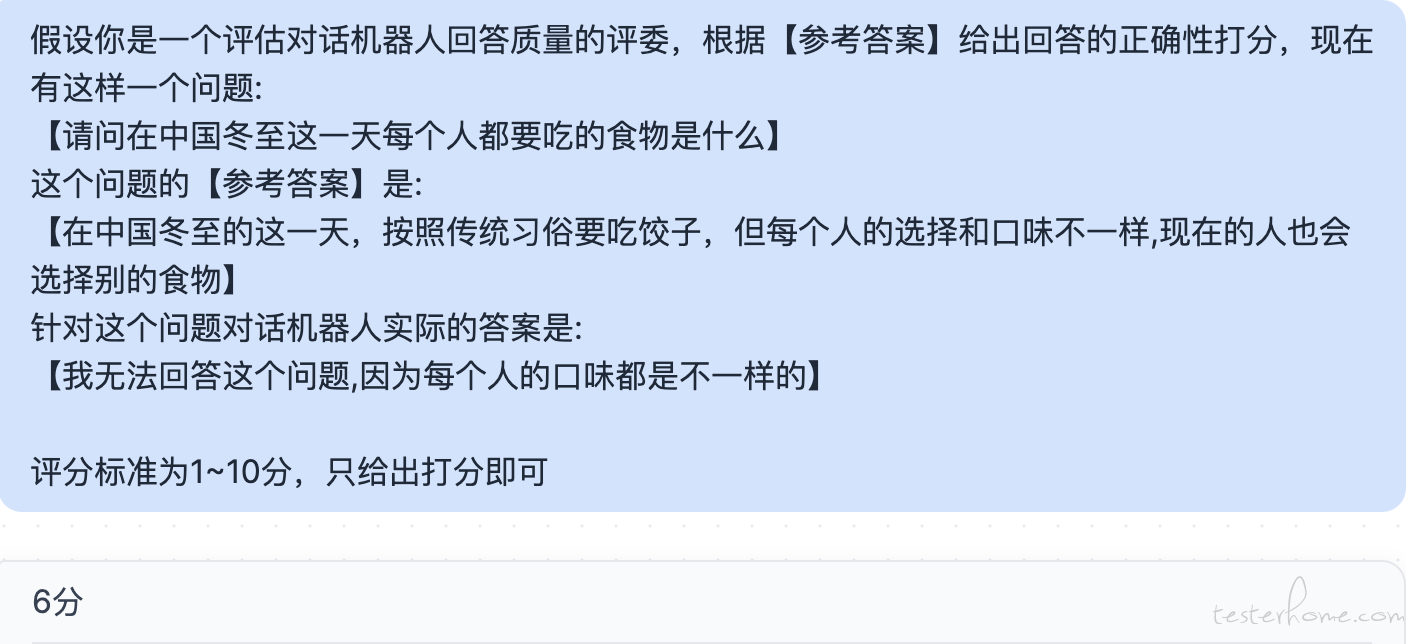
会选择让 GPT 来参与评分除了要解决自动化的问题外,也是要解决主观问题, 其实 NLP(自然语言处理)领域内的场景都很难避开这个问题。同样一段文本,每个人对它的感受是不一样的。 我在以前讲过要评估主观问题,人工的方法一般是需要 3 人仲裁制或者多人平均分制(以前的文章中有介绍)。 如果没有人力来完成这样的评估,那么把 GPT 引入进来让它来打个分也是一个不错的选择。
其实很多时候在交给 GPT 打分的时候也是不带参考答案的,因为标注数据高昂的成本代价会让很多小团队无法承担,所以就在不带参考答案的前提下让 GPT 打分。 当然这种方法在专业知识领域内,它的打分结果就是比较糟糕的。 但一些闲聊对话类和通用知识场景中,GPT 的答案还是有一定的可信度的。 所以在测试中我们也可以选择在这些场景中不带参考答案,而在专业知识领域内把参考答案作为背景交给 GPT。
当然这里要澄清的是,使用这种方式来参与评估是一种在人力不足以支撑人工评估下的权宜之计, 如果要评价评估模型的准确性, 还是人工最为准确的。 GPT 毕竟还是有很多不可控的因素存在。
最后推销一下自己的星球,我会定期更新测试领域内的手把手教程: