没有源码!对测试平台功能设计感兴趣或者不知道做什么功能的可以看下去,希望对你有点启发 🙏
在实际使用中测试中包含了大量回归任务与其他检查机制,仅接口回归任务而言目前执行的接口已经达到了 3500w+,每日场景用例执行量达 5w+,自动检测任务总运行 50w+ ,但由于各种历史包袱或者使用频次,非重要功能等原因一些检测到的风险并未及时修改而导致长时间存在,又由于未将风险关联到人,导致风险项无法流转追溯,所以需要一个风险跟踪机制将问题持久化并将负责人拉入风险处理的流程内,在有空的时候主动推进,让问题最终得到解决,避免历史风险持续叠加导致各类棘手的问题。
数据看板将展示所有风险并根据风险类型 - 风险来源 - 风险名称 - 负责人聚合, 在此可以审查系统近期捕获到的一切异常信息
在工作台内可以将任务单个/批量指派给他人,可以将任务单个/批量更改状态,可以单个/批量评论任务,可以记录任务各个字段的更改人 - 前后更改 diff 值 -以及持续时间
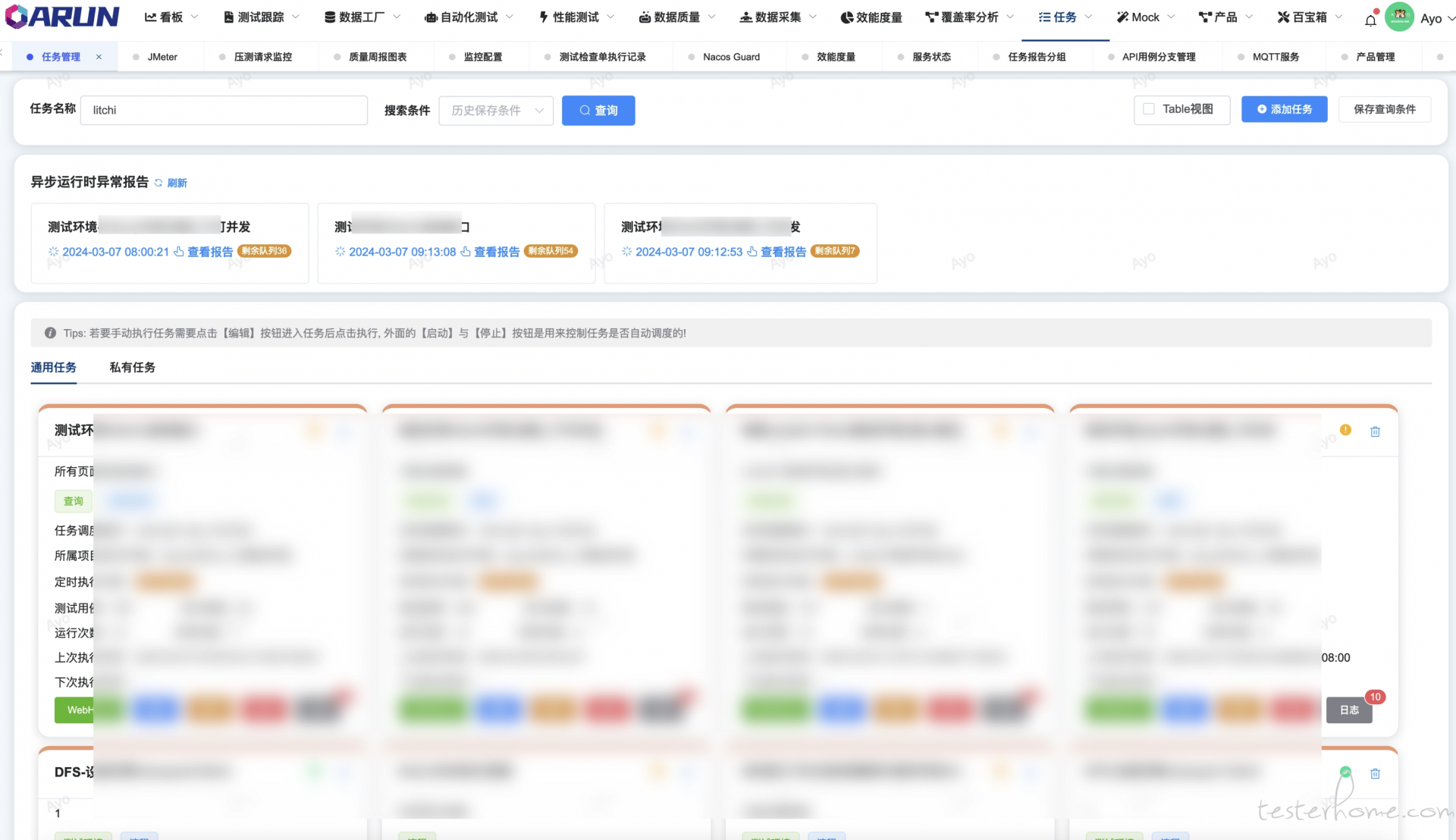
随着公司项目越来越多,而对应的测试回归用例也越来越完善,但面对客户项目上线发布的频率增高,尤其是临时定版热修的情况下,测试用例回归将会耗费大量时间,最终会消耗一定的时间在于等待回归用例的执行,为了减少这种窘况的发生,对于任务用例编排以及执行优化迫在眉睫,我们希望通过以下方式来减缓这种问题的情况:
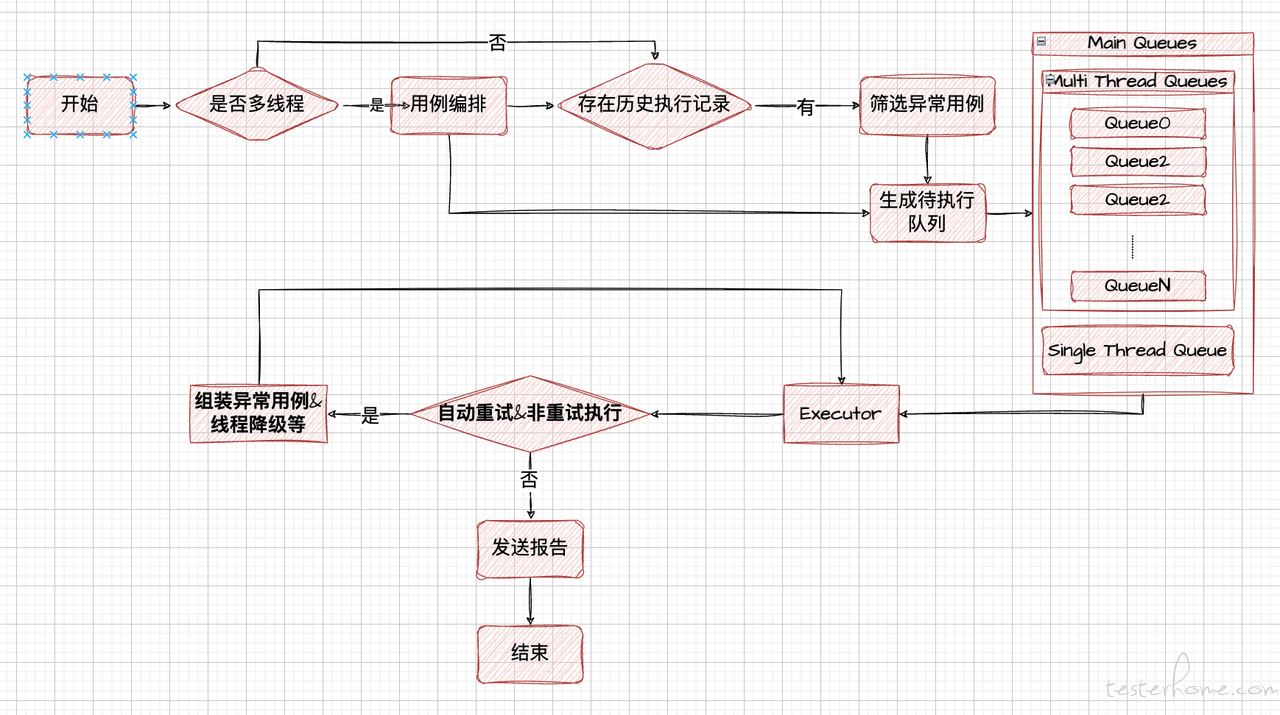
基于贪心算法的线程级别的用例编排,使用历史执行数据根据线程数量动态分组执行队列,另外对于执行用例按照用例执行时间从小打大依次扔入队列,使得消耗时间越大的上用例都在最后,可以在有限时间内看到更多用例的执行情况;
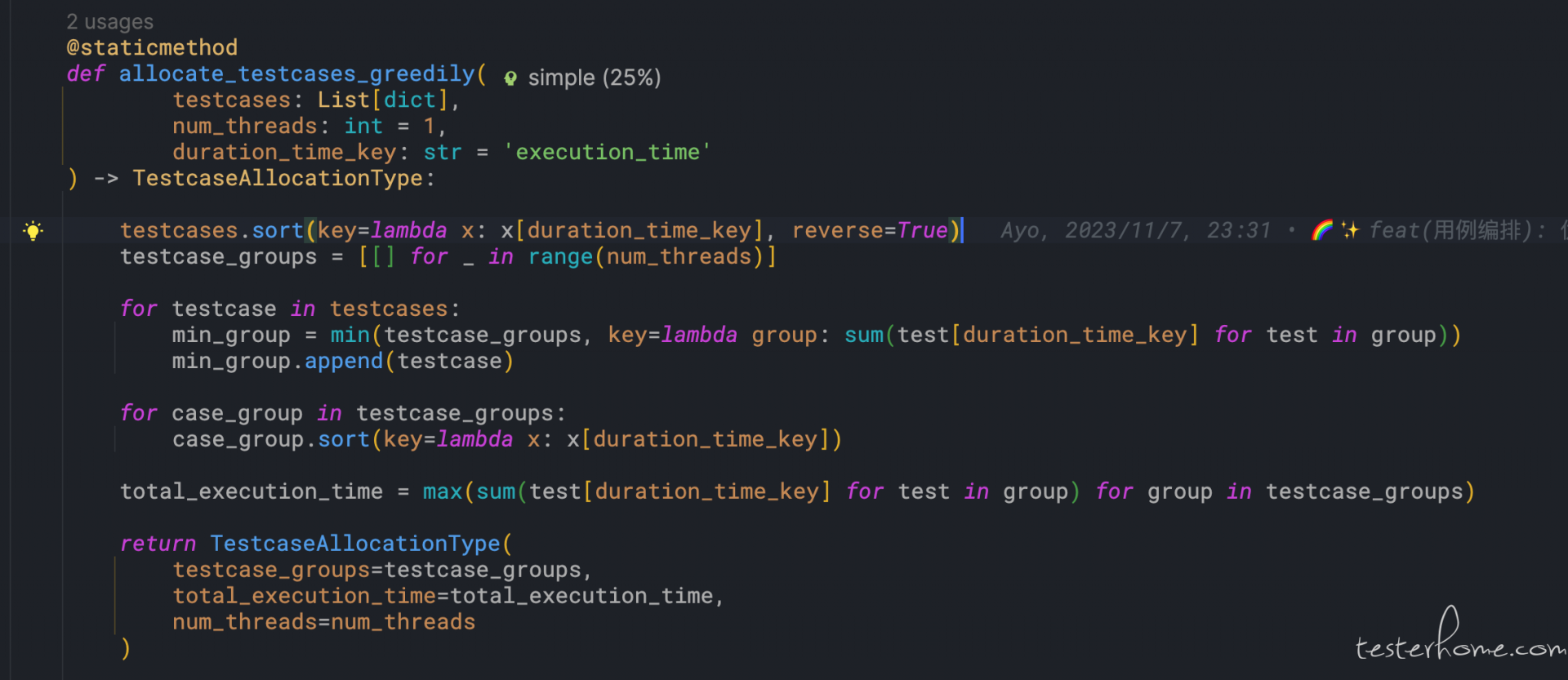

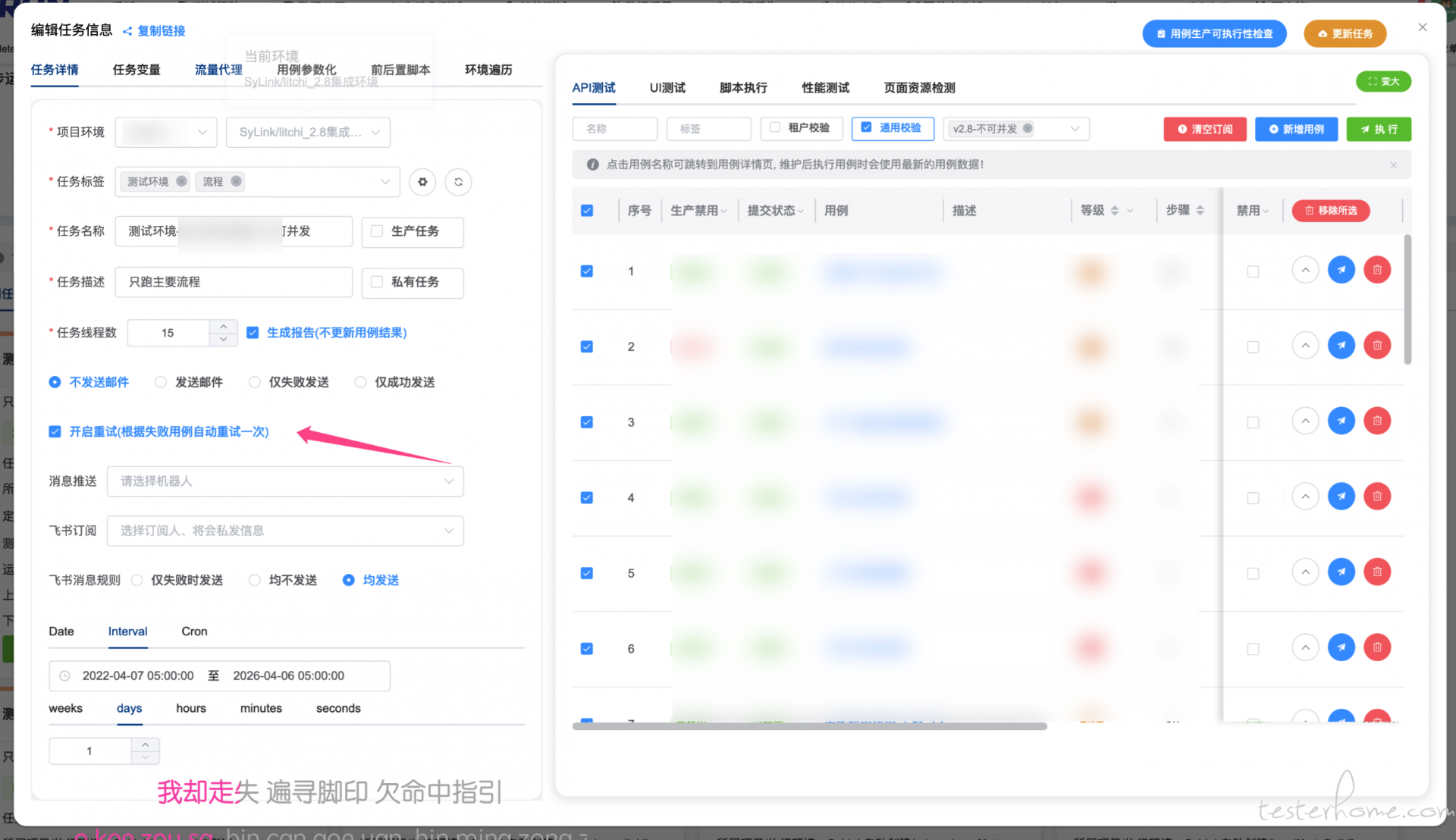
开启自动重试,自动重试默认采用 2 个线程执行,而平时用的都是单线程,这样设计为了提高给到大家重试时的及时性,以及大家自己重试时的正确性;另外对于不可并发的任务,采用多线程执行后将会将第一次执行异常的用例落库,并在下次执行时动态的分配到单线程执行队列中,在多线程只任务结束后,由单线程执行;
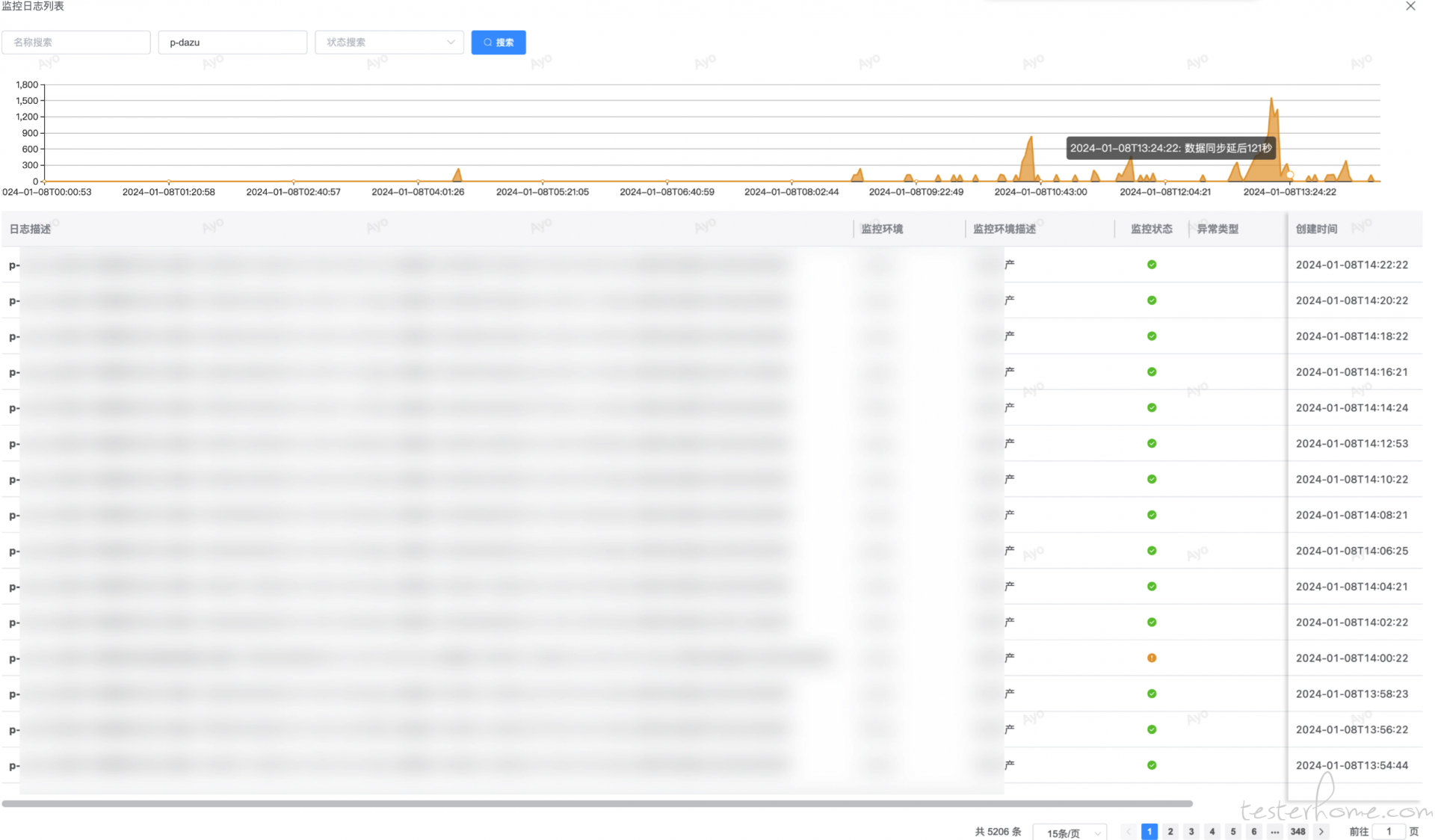
目前通过 flink cdc 通过模拟 mysql slave 的方式订阅 binlog 的变更消费,来做数据同步到 starrocks,但由 flink 组件复杂且不是特别稳定,有时候会出现 taskmanager 假死,binlog 数据无序消费从而造成同步数据异常的问题,现在需要一个工具可以验证同步任务是否正常运行;
现在通过每个环境自动创建一张表,并写入此次检查的时间戳,下次执行时检查 starrocks 与 mysql 中的时间戳的差值,差值则为最小的延后时间(经测试在没有压力的时刻 mysql 修改/增加的数据写入 starrocks 将会非常快,几乎无感)
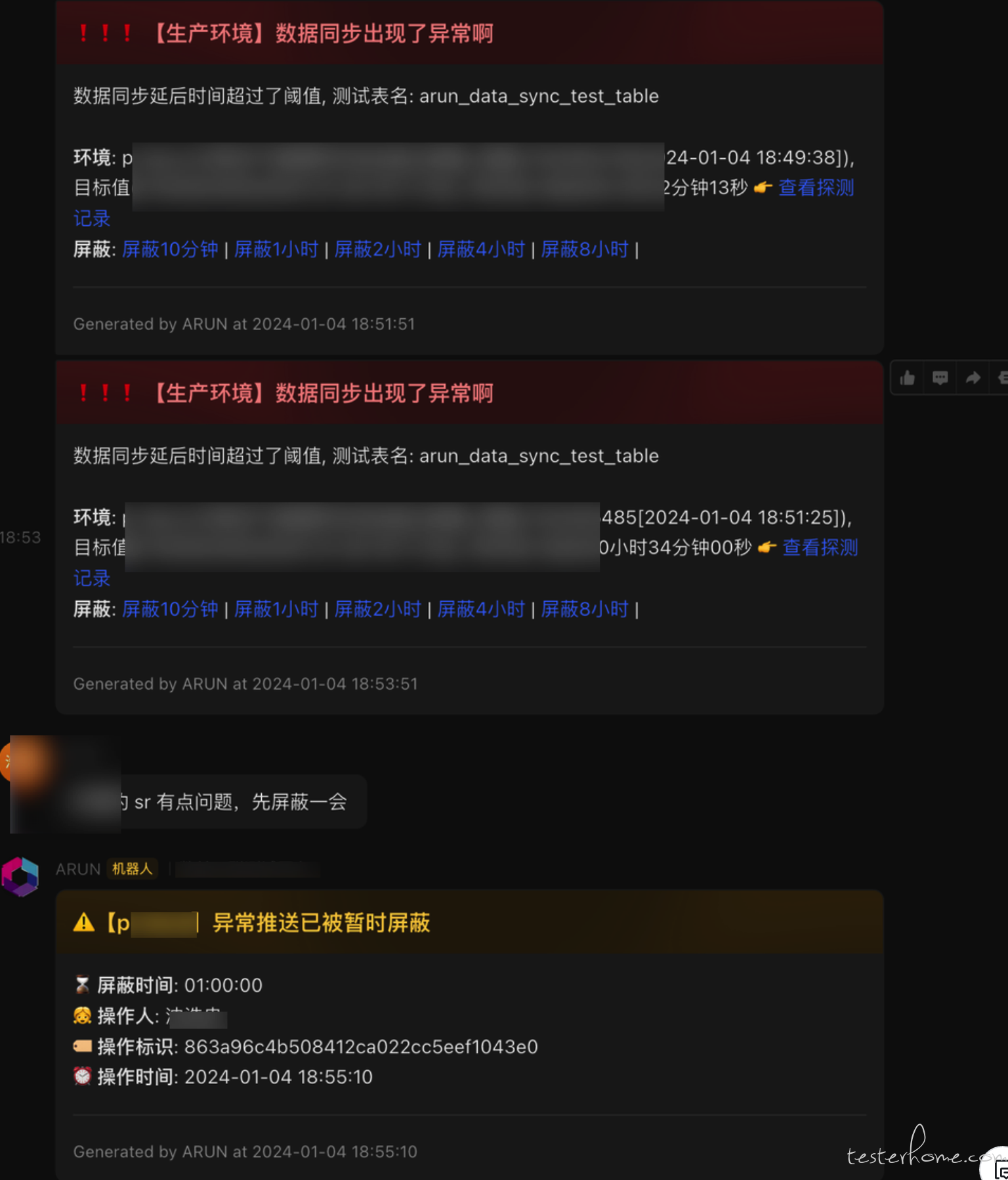
支持公共/自定义配置环境阈值/环境忽略等配置;支持异常推送/恢复推送/失联推送等;支持历史检查日志/延后趋势汇总/前一天的探测成功率汇总;支持屏蔽指定时间/环境的消息;支持全环境的状态总览;异常推送到指定群组
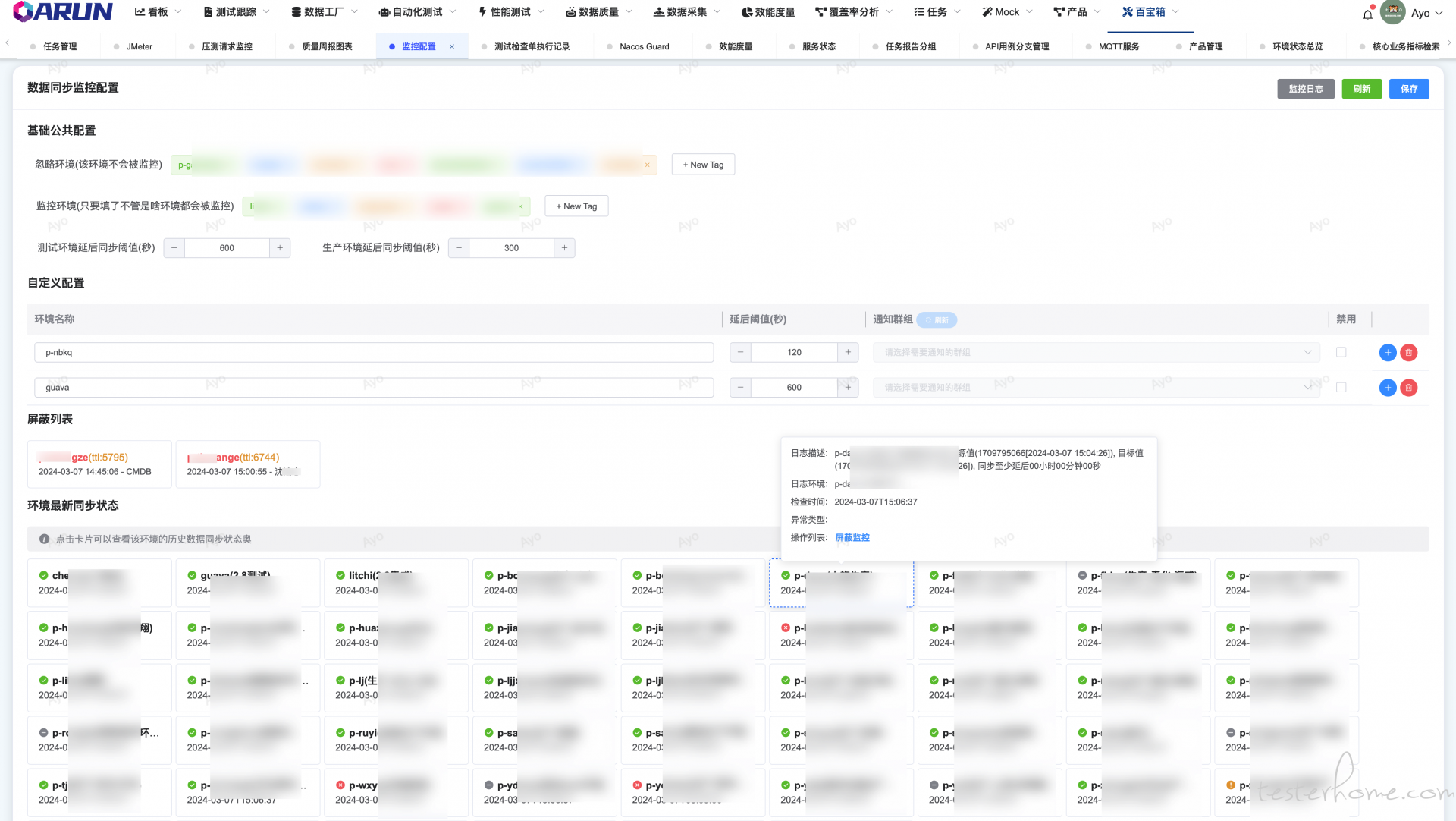
历史延迟趋势审查
消息聚合屏蔽/汇总

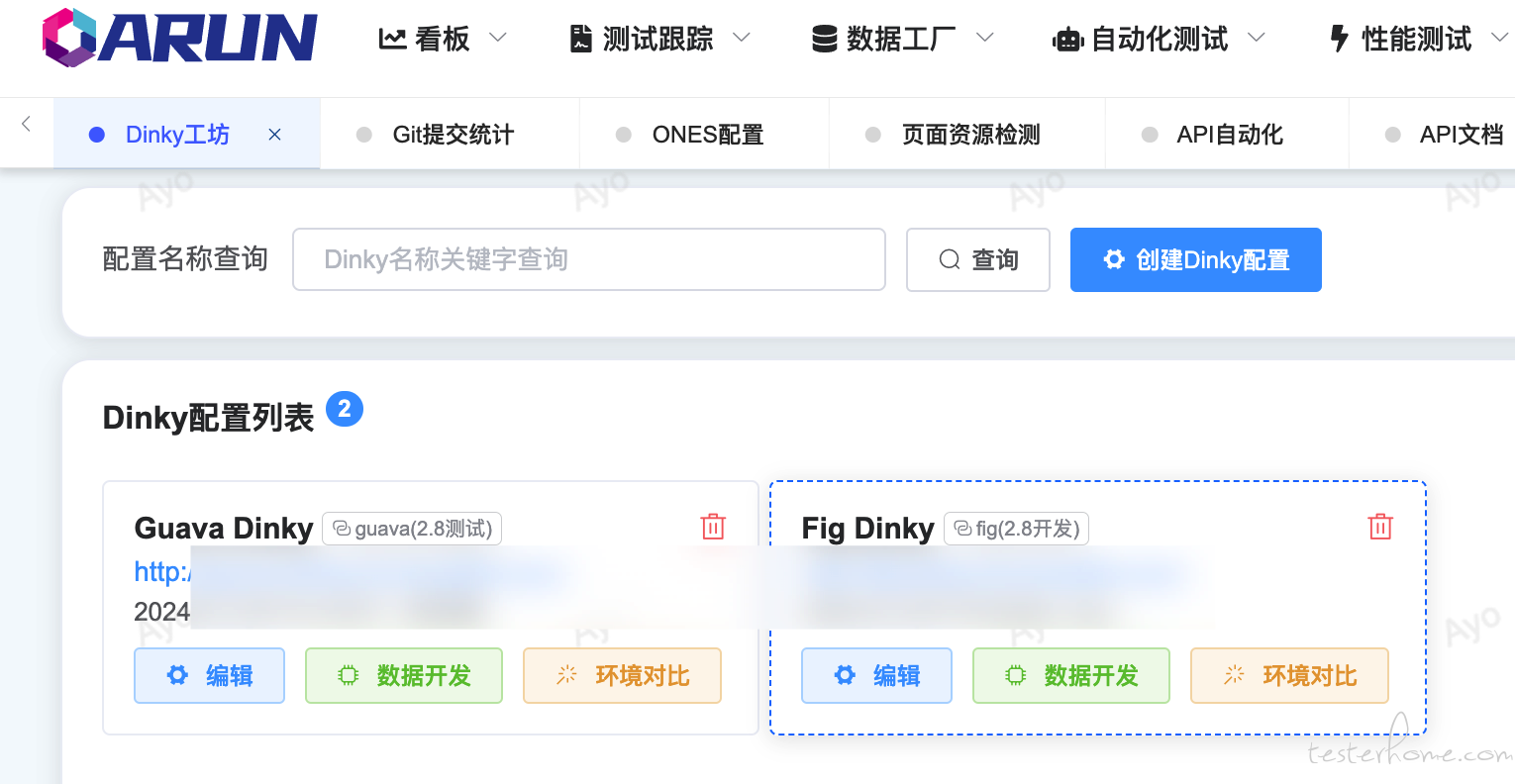
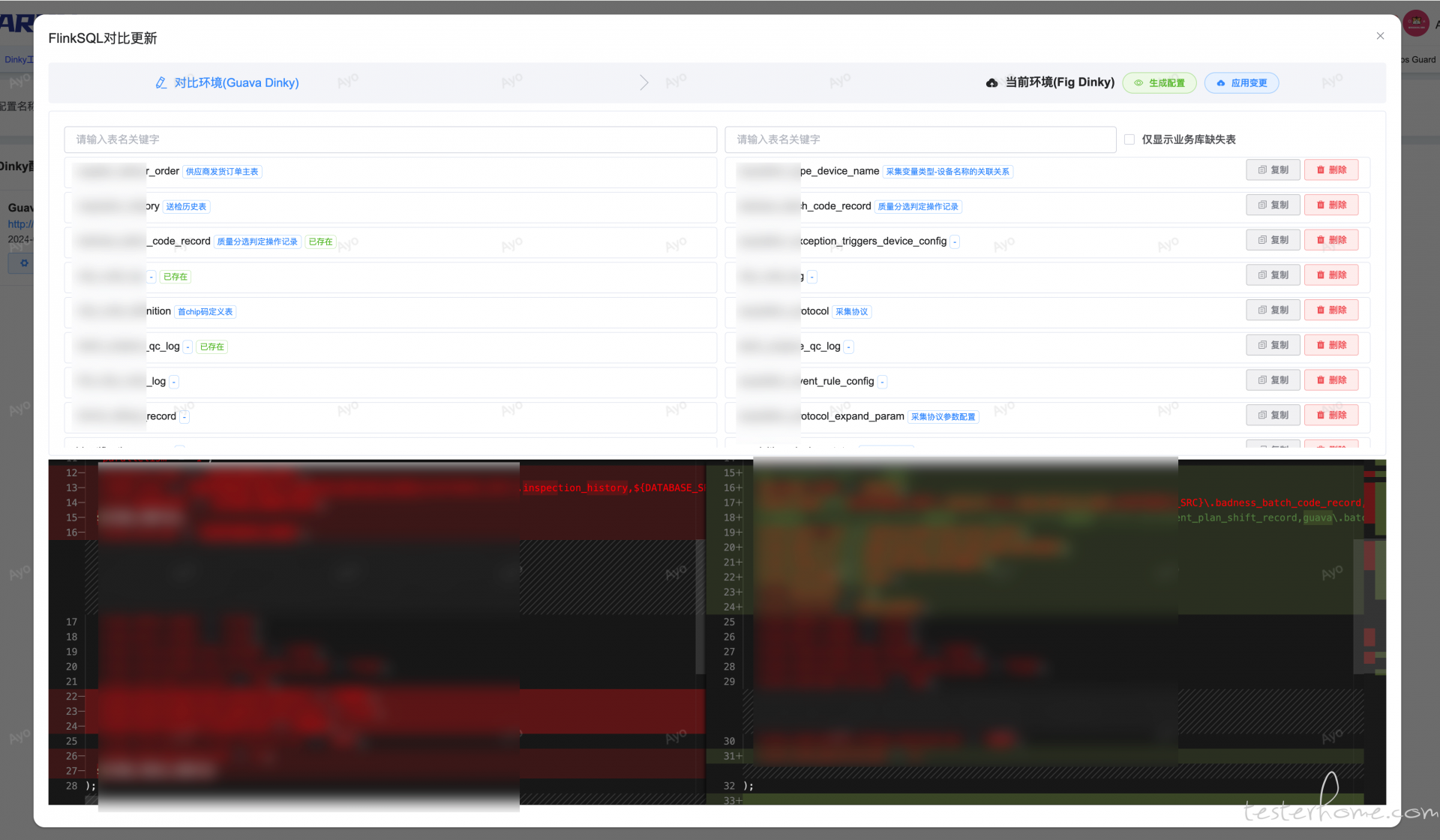
可视化编辑 Dinky Flink SQL,并自动关联当前业务数据库,拖拽预览/生成 FlinkSQL 并保存进 Dinky,解决 Dinky 无法关联业务库,无法直接判断表是否存在以及不同 FlinkSQL Diff 功能。
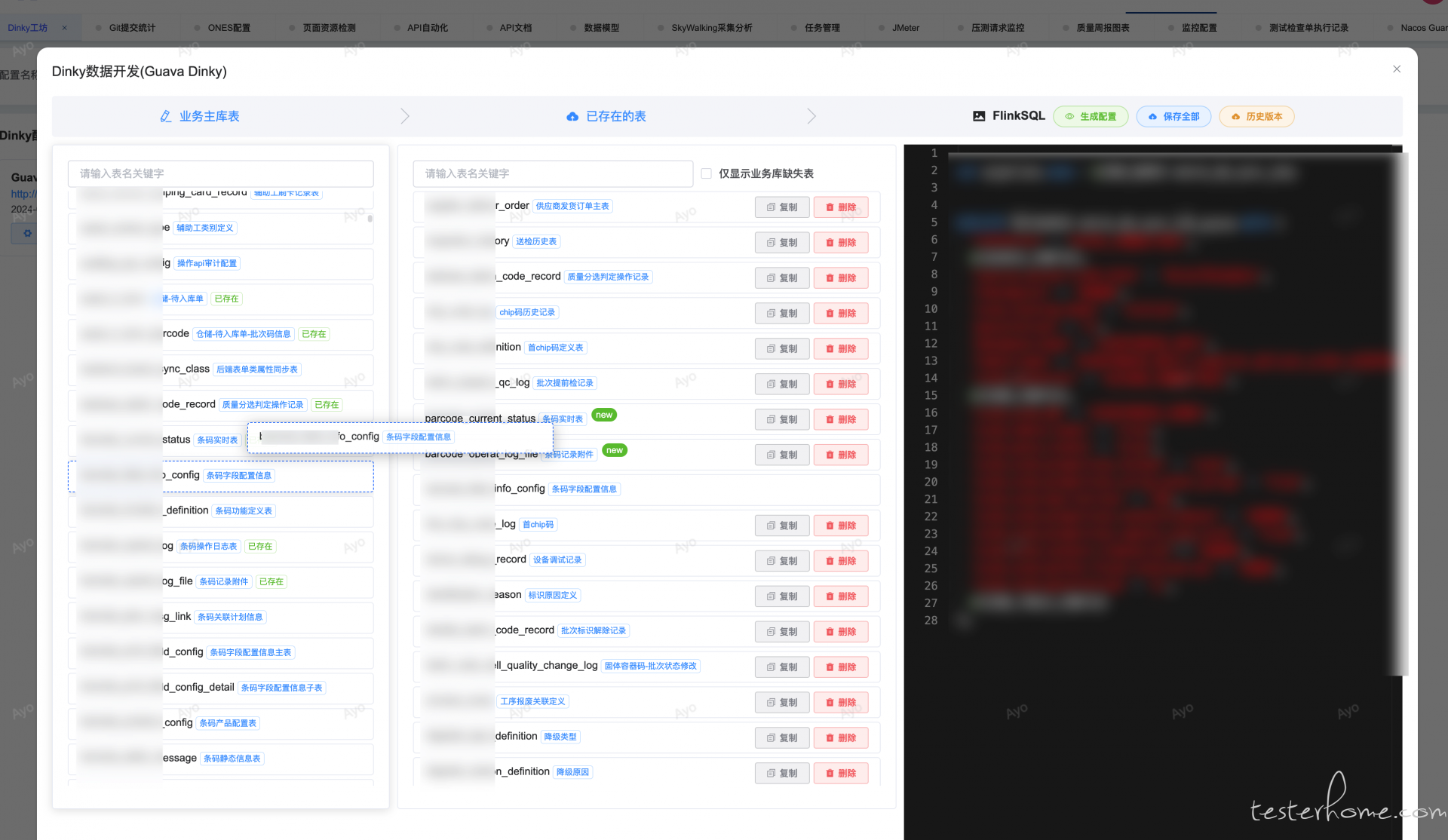
根据业务库查询所有表,解析 FlinkSQL 查看已存在的表,并做可视化编辑以及 diff 操作
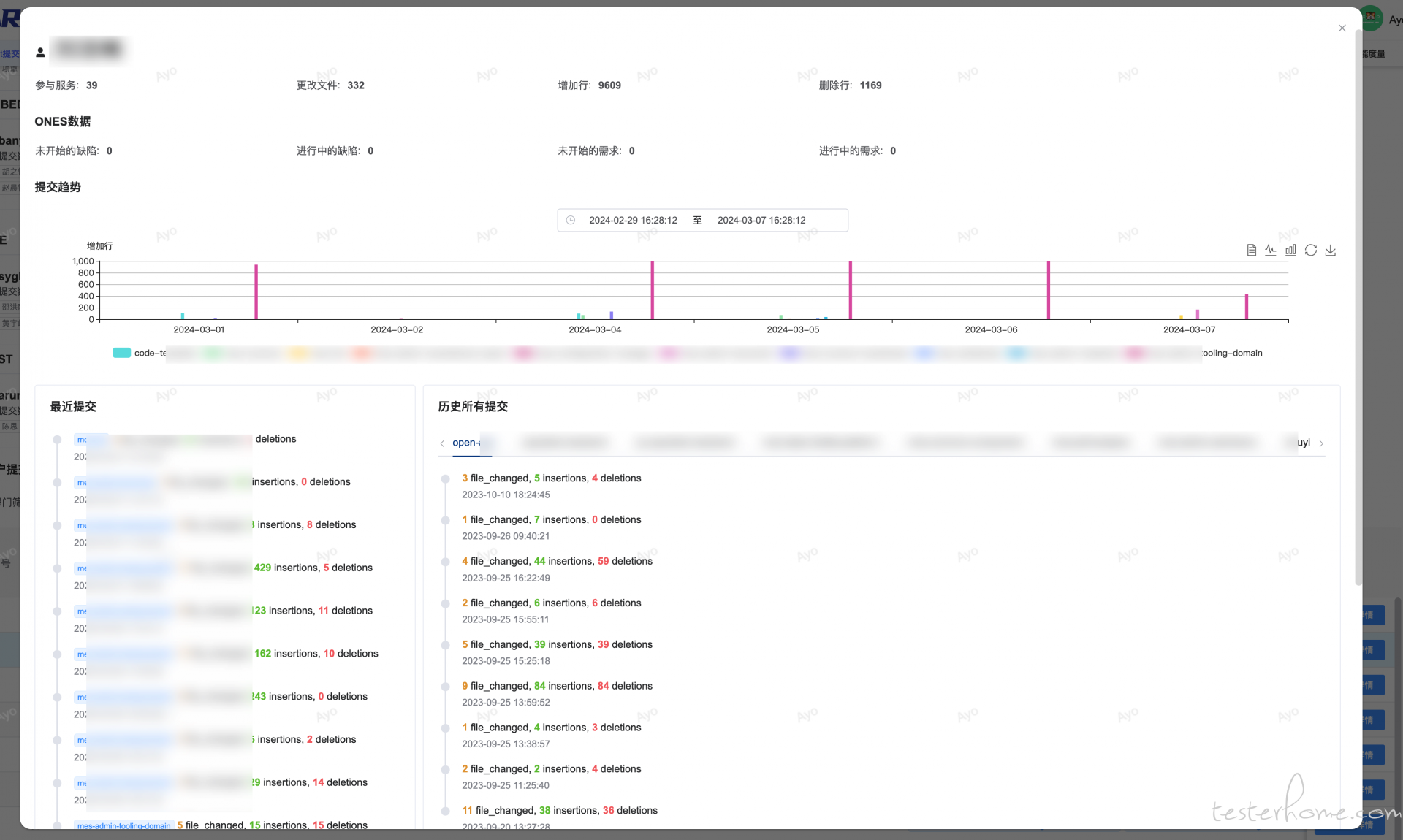
为了统计热点服务,聚焦核心功能以及分析人员能效的一个维度;
部门服务下人员提交汇总聚合展示代码增加/变更量
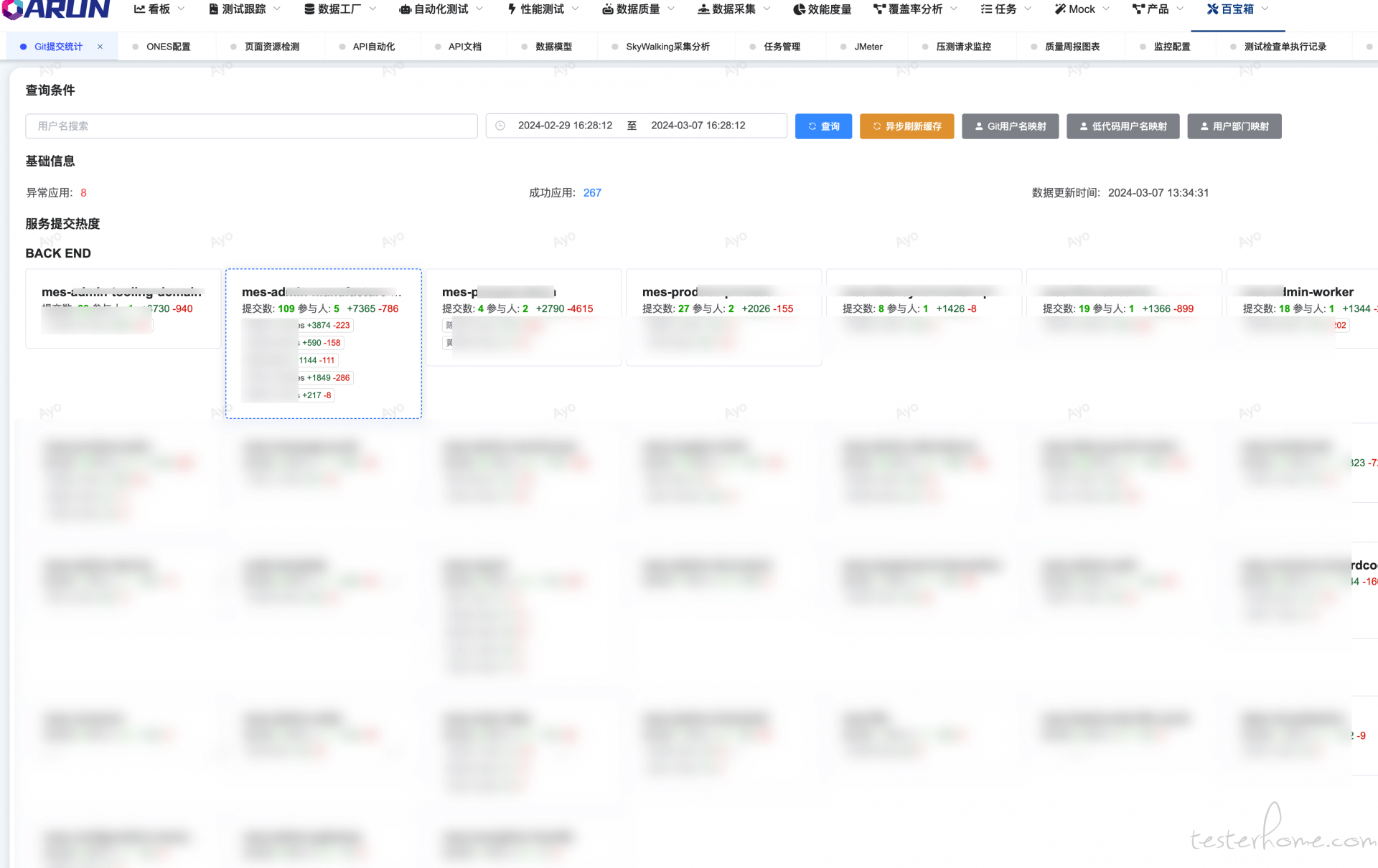
代码提交按照人员的排序列表以及人员最近提交趋势