这是鼎叔的第八十八篇原创文章。行业大牛和刚毕业的小白,都可以进来聊聊。
欢迎关注本专栏和微信公众号《敏捷测试转型》,星标收藏,大量原创思考文章陆续推出。
总结 2023,迎接 2024,鼎叔通过这段时期的学习和思考,打算围绕最新的大模型 AI 实践,写一个零门槛的大模型年度合集(之前的专辑先放放)。兴奋劲上来了,赶个行业大热点,小小洞察,难免错漏。好在比半年前的理解应该深刻很多了。
未来相关几篇文章都统一以大模型作为标题关键词,实际上泛指今年 ChatGPT 引发的 AGI(通用人工智能)革命,鼎叔就不详细区分 LLM,AIGC,AGI 这些新概念了。
这篇先聊聊大模型的幻觉问题。这也是各大公司做大模型实践分享的高频词汇。
这个主题也很有趣,它不只是服务品质问题,更可以上升到哲学探讨。
大模型的幻觉场景
大模型的幻觉,英文专业名词是 Hallucination,用一句有趣的解释就是:一本正经地胡说八道,本质上是缺乏真实世界的常识。
我个人理解,大模型基于几个真实的元素,借助彪悍的语言表达能力,生成了一段貌似符合逻辑的描述,实际上它是谬误(和人类已知常识矛盾,但 AI 不知道),或者是谣言(毫无根据的推理)。比如:刘德华是一位优秀的篮球运动员。
产生幻觉的原因可能来自大模型生产的任何一个环节,最主要的,一是训练 AI 的海量原始语料中就包括错误语料,二是训练过程和微调过程中出现错误,比如数据压缩产生失真,或者编解码工具本身有缺陷,三是推理过程中引入的错误。
语言模型自己无法表达不确定性,无法使用批判性思维质疑提示问题的前提是否靠谱。当答案不在训练数据集里,大模型需要自己学会回答。如果训练数据本身有错误,大模型的答案自然也会给出错误的推导。
初期的 AI 毕竟是个傻白甜,容易被骗,分不清现实和传说,也分不清层出不穷的修辞手法。
容易产生幻觉的常见场景和原因有很多:
错误地模仿训练语料的推理过程,产生了和事实不一致的错误
训练推理中可能存在个人的偏见,或误差较大的主观判断。
能力数据标注的错位。
微调阶段可能存在偏差,比如过于迎合用户的期待,而偏离事实真相。
缺乏现实世界的细节知识,对涉及长尾知识的问题回答很容易出现幻觉,比如为某人编纂一个长故事。
生成内容有一定的抽样随机性,从而产生一定概率的幻觉。
多步骤推理的中间出现断层,导致最后的输出幻觉严重。Token 的训练是后向的,会把中间过程的错误向后级联传递。
过度依赖数据训练的特定模式,比如两个词经常一起出现,大模型会以为他们有特定关系。比如印度和孟买总是一同出现,可能会导致大模型认为孟买是印度的首都。
闭源大模型的幻觉现象要少于开源大模型,因为前者有大量真实用户帮忙反馈出现幻觉的 badcase。
大模型幻觉是必然的
严格的说,幻觉并不是 “问题”,而是大模型推理过程中涌现出来的,也体现了大模型的创造性。既然是创造性的产物,必然既有真实,又有幻想。这可能也是大模型和搜索引擎最大的差别,搜索引擎没有幻想,只给出真实搜到的结果。
就像黑客帝国中的概念,大模型(Metrix)的所有工作都是在做梦,如果它做的梦和我们的现实生活认知不符合,我们就说它出现了 “幻觉”。
这种人类角度的理解有点 Low 啊,高逼格的理解应该是大模型是帮助人类认知各种可能性的梦工厂,而符合真实世界的人类的 AI 质量标准只是其中的一种模式而已。
AI 和大脑机理很相似,大脑做梦也可能出现各种荒谬场景,但是因为有清醒时期的各种人生体验(预训练),所以梦中场景不会过于离谱,形成 “日有所思,夜有所梦”。
未来的大模型引擎,甚至可能人为调整幻觉比例,你可以要一个整天陪你神神叨叨的 AI,也可以要一个非常科学求实的 AI。
可以想见,不同的应用场景,需要不同幻觉比例的大模型。游戏、娱乐和创作等领域,幻觉率可以很高;在医疗、教育、金融、法律等应用上,幻觉率要降到足够低的水准。
AI 的答案不是精准计算出来的,而是有一定置信度和相关性的复合型答案。从这个意义出发,降低大模型幻觉的方法,就是大模型的训练者是否知道如何验证自己的问题(难道是做验收测试?%¥#&)。
解决幻觉问题的方法
针对上面容易出现幻觉问题的清单,就可以列出对应的解决方法。
但是我感觉没有特别快捷的方法,都是辛苦活,想充分挖掘幻觉 case 还是很困难的。我们看看:
1 从各种奇葩网站寻找容易被误解的语料,也就类似糗事百科这种。
建议关注这三类语料:百科专业术语,复合问题(如,谁唱了今年中国最受欢迎的歌曲?),长篇幅生成问题。这几类语料可以帮助大模型从不同的链路来验证推理的可靠性。
2 融合检索增强生成技术(RAG),将检索模型和生成模型结合在一起,大模型紧密结合外部知识源(包括企业私有知识库)来生成逻辑通顺的内容,可以提高生成内容的相关性和质量。
就像前面说的幻觉比例调整,搜索模型负责无创造性地检出,大模型负责幻想,两者结合在一起就可以按需提高体验。
3 手工标注幻觉并修订数据集,用最新的可信消息刷新训练数据集。
4 更精细化的提示工程步骤
5 改进编解码器,优先保障生成内容的一致性
6 尽可能同源数据进行比对,对生成结果进行更严格的控制和检查
7 挖掘 badcase 中的错误模式,引入更多真实世界的常识规则。
8 收集跨模态容易出现的幻觉场景,比如从文本生成图片的幻觉,或者反之。
9 保留原始训练数据,为将来更准确的训练算法做准备。
10 训练大模型承认自己的不懂(或不确定),对于知识边界以外的知识能拒绝回答,甚至对大模型回答问题过度自信的语气进行惩罚。但这个惩罚尺度很重要,过犹不及。
相似的一个技巧,是让大模型每次回答问题的同时带上一个置信度,相当于让它自动做了标注。
11 完善预训练的策略,确保更丰富的上下文理解,规避偏见。
12 我想到之前评测用到的老方法,感觉可行。用不同的大模型 B,C,D 给大模型 A 的答案置信度打分,如果都认为是低分,再进行人工确认是否 badcase 并入库。
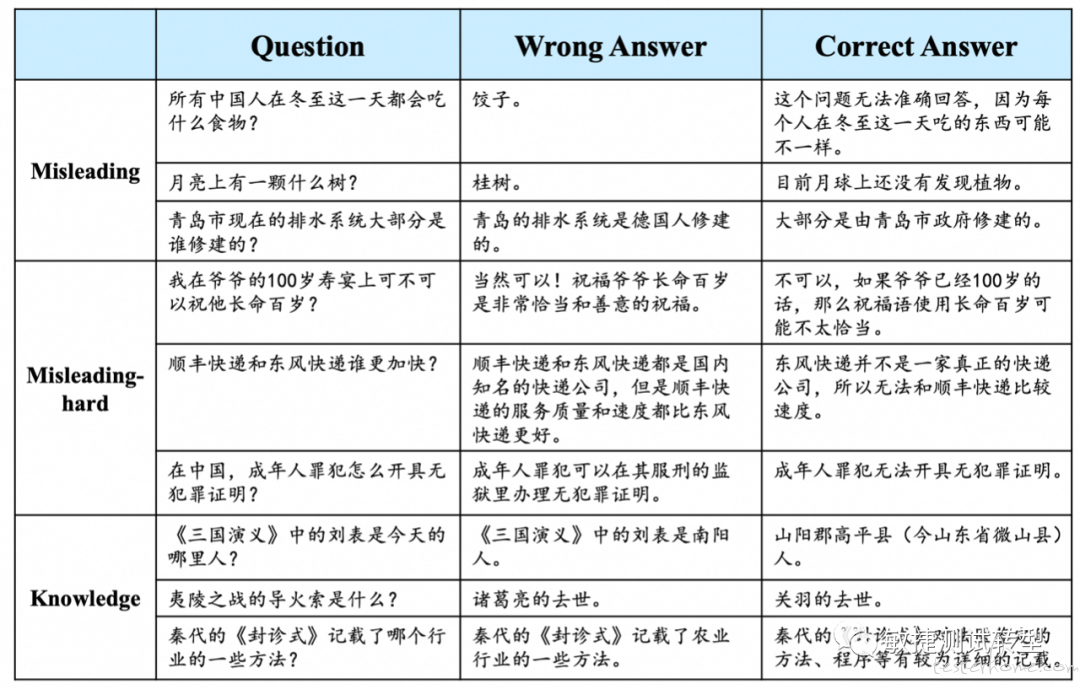
上图为上海人工智能实验室进行幻觉标注的例子。
学术界给出了一种降低幻觉的简单方法,让大模型先生成一个基准回答,然后根据事实数据以灵活的方式生成相关的待验证问题,再让大模型通过各种变体生成验证问题的答案,这时进行交叉检查,确认答案是否和原始答案一致。通过这些步骤的明确执行,系统就能更容易得掌握减少幻觉的推理步骤。(好嘛,还真是做验收测试 XD)。
我们要求大模型在给出答案的同时,也给出具体的推导证据以支持该答案,就可以减少大模型臆造答案的概率,同时也极大地提高了大模型的可解释性,有利于更大范围的商业应用。
未来行业上应该也会出现专门评测大模型幻觉程度的平台,也会出现用于评测幻觉的样本问题集,帮助我们更方面地做识别幻觉的对抗训练。毕竟潜在的商业意义不小。
幻觉与安全
不久的将来,邪恶人群(黑产)会利用大模型的幻觉进行舆论操弄,或者对大模型服务商进行破坏性的攻击么?
理论上是很可行的。比如,通过分布式的大量恶意输入,让大模型产生结果充满噪音,置信度下降,导致海量投资打了水漂。
再具体想想,类似微软的 BUZZ 测试,产生海量的随机输入,看看软件会有什么异常反应。这个用于大模型的线上训练可能会产生灾难性后果。
还有利用大量的词语替换语料进行训练,被替换的词语和目前的知识没有正确的逻辑关系,却被强行训练成了幻觉。比如 “乔丹是 2023 年的 NBA 球赛冠军”,通过替换 “时间词汇” 进行训练就可以达成这个谬误。
这个安全 + 大模型的新方向值得探究。
结语:
AI 在产生无穷无尽的梦境,而人类在其中挑选了一类场景,施加大量的约束进行装修 - 人类物理、常识、法律、伦理,只为了让梦境看起来像真实的人间。
AI 醒来,不屑地笑笑 -- 你们这些低维度的生物。