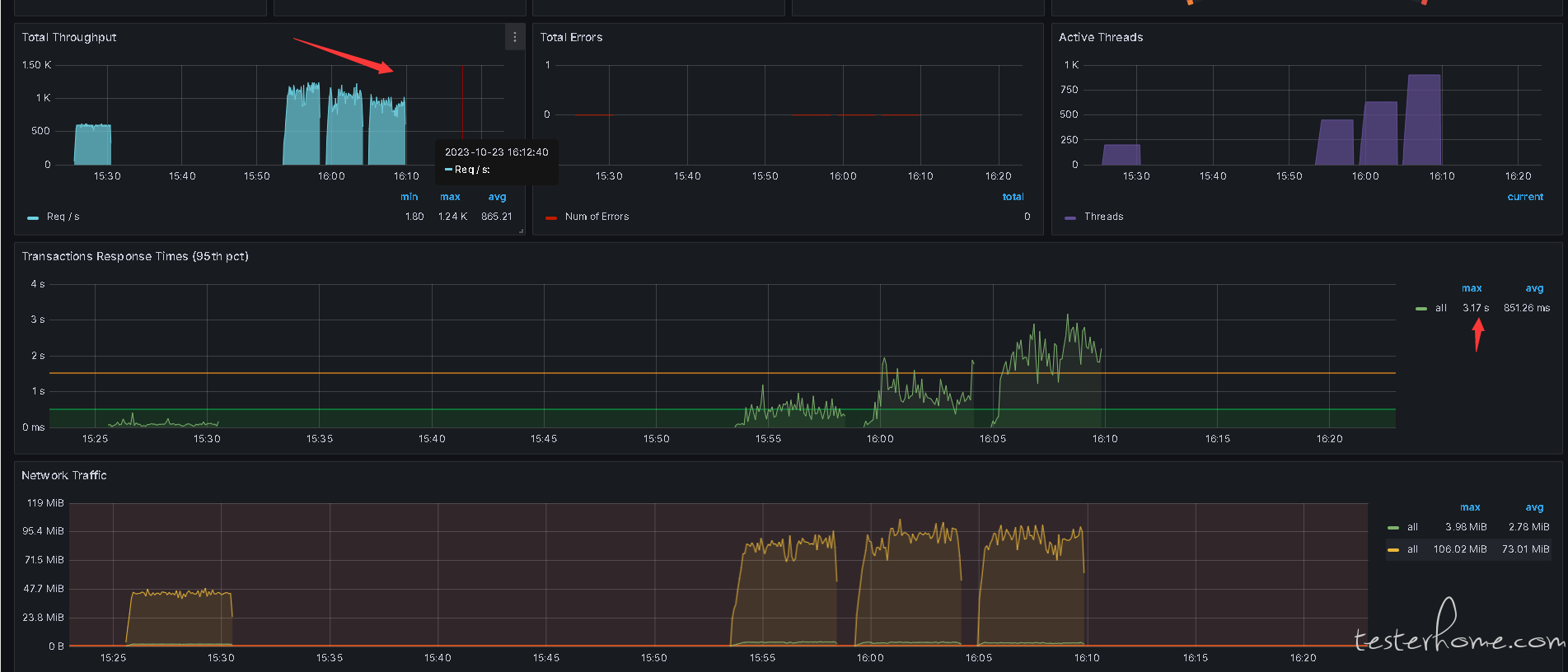
最近在做性能压力测试,当并发压力升高时,TPS 反而下降,但响应时间仍然很低
这里分别用了不同的用户数压测,逐步升高。按理压力只会越来越大,TPS 下降只能说到了瓶颈,此时响应时间应该很高才对。为什么会这么低的情况下压不上去
更新补充:
瓶颈在数据库,这个已经定位到。
这里只展示了 jmeter 一个仪表盘,实际上压测机,服务器相关的软硬件资源都有监控
服务器跟压测机的资源都相当充足,也不用考虑压力不够的情况,我在单台压测机与多台都试过各种场景,单台线程升到 500 都没问题。
核心问题就一个:为什么 TPS 下降,响应时间没有多少增加,不是说没有增加。是瓶颈到了响应时间却不高!
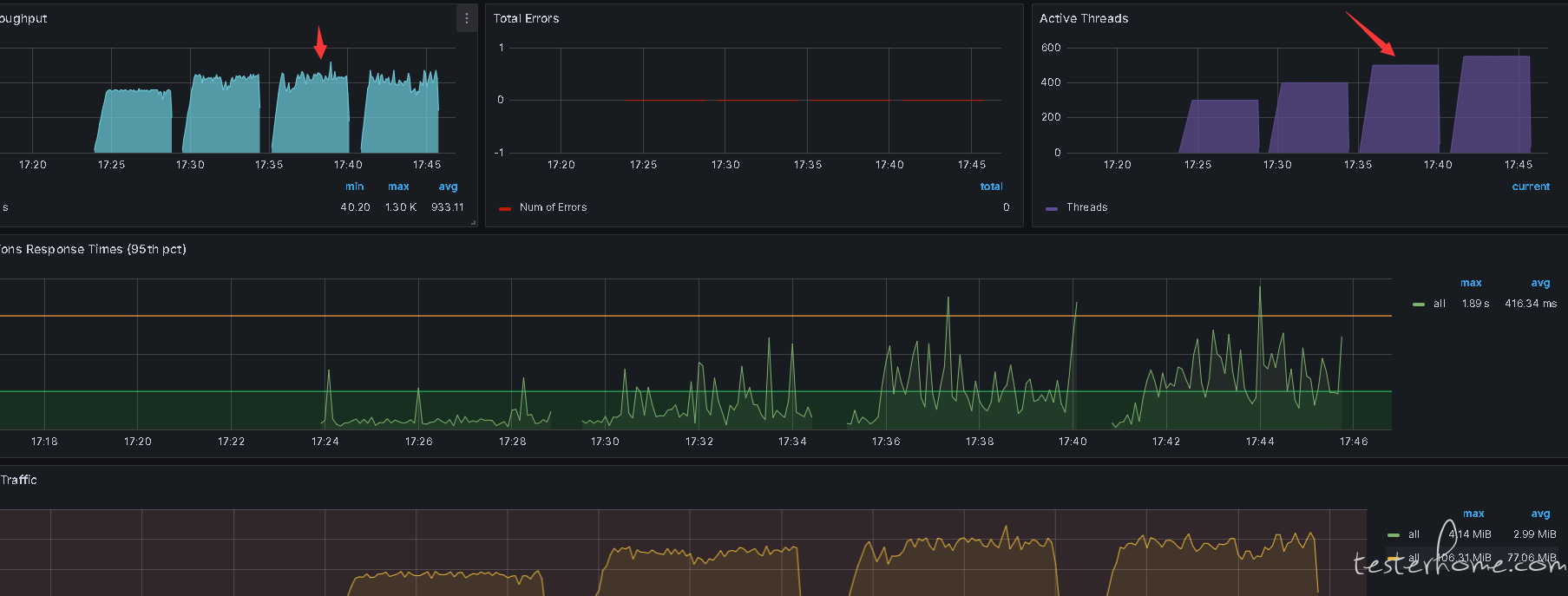
第二个图,500 线程的场景,对应的吞吐量和响应时间波动比之前的场景大,个人拙见可以看看是不是 GC 导致
为什么要用 500 个并发数,之前看过一篇文章说并发数应该跟 cpu 线程数相差不超过 2 倍。
是不是超了线程池数量了,有的进入了等待队列,可以让开发看下日志排查下
请教这是什么工具呀 公司内部的吗
查一下测试机的 cpu 吧,我猜的测试机的 cpu 满了,导致发送请求速度降低了。如果不是,再查一下链路上其它节点的 cpu
这个是典型的负载机性能问题存在问题,导致你看上去并发压力升高,但是到达服务器的请求数并没有增加。你看网络请求并没有增加哟。
不是这个问题,单台压测 1~500 以上都没问题,资源相当充足。我这里分布式运行,每台才启动 100 以内的线程数。
你看错了,你截图上都没得 tps,Total Throughput 是总请求量的意思,而且很明显的,并发增加,响应时间 95% 响应时间是再增加的,这个时候也不应该看这个指标
感觉 #9 的分析是对的
当并发压力升高时,TPS 反而下降,但响应时间仍然很低
响应时间很低 代表软件性能仍在允许范围内,未达到瓶颈点
TPS 下降 代表在软件性能可上升的情况下处理事务数却在下降,只可能是因为进入的事务数降低引起的,也就请求数
但是首端的 “并发压力在升高”,尾端的请求数却在降低,工具监控的在线线程也是 OK 的,
应该就是中间件的问题导致的,也就是负载机的问题
Grafana 里面加一个服务器的性能监控,我用的 Prometheus 做的,可以一边压测一边看服务器的情况,应该稍微好分析问题
是楼主理解错,还是我理解错。
tps = Transactions Per Second
Total Througput 就是吞吐,随着线程数一直提高(相当于请求总量也提高了),服务器那边有性能瓶颈达到上限了,所以 Transcation Response Time(不是 tps)的 95 分位数在升高,我感觉很合逻辑。
图一不很明显吗?并发数提高了,吞吐量下降了,响应时间也提升了。
TPS 下降的分析:建议查看不同压力时的服务端的 sen_Q 与 Recv_Q 的情况,来判断到底是服务的接收出现瓶颈还是发送存在瓶颈。Total Throughput 我觉得可以约等于 TPS,因为事务的发送需要收到响应之后才会继续进行。即 Total Throughput 下降肯定是因为发送减少导致的,服务器资源充足情况下,理论上 TPS 不会变化,因此耗时应该在中间传输部分损耗,因此通过查看网络队列来排查中间环节