从去年末开始,除了日常的测试任务外,还被分配全权负责一个端到端 UI 自动化项目,因此这是一个从 0 开始构建起 APP ->服务端 ->硬件执行端项目的总结文,主要为了记录这个项目的变化,以及从中的收获,希望也能对大家有所帮助
1.跑起来
第一阶段,经历了一周的准备和了解之后,确立的首要的目标就是迅速跑通一个冒烟,所以紧赶慢赶终于写好了一个冒烟流程的 case。
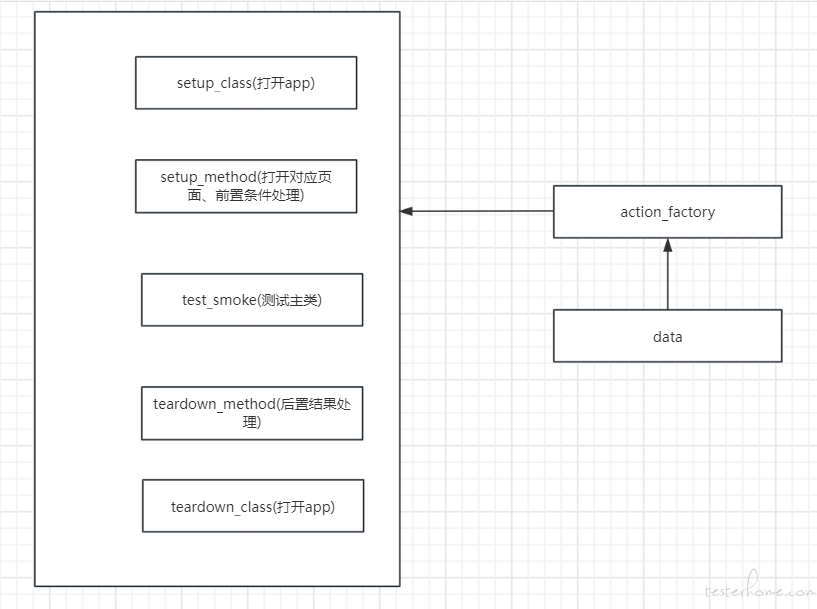
1.测试框架选型:pytest,将不同操作封装在不同层
2.APP 测试工具:基于 Uiautomator2 封装的 UI 测试框架
3.将公共数据放到统一的 py 文件管理,数据读取方法抽提到一个独立的类,同时这个类也放置其他的公共操作方法
具体结构如下
2.多起来
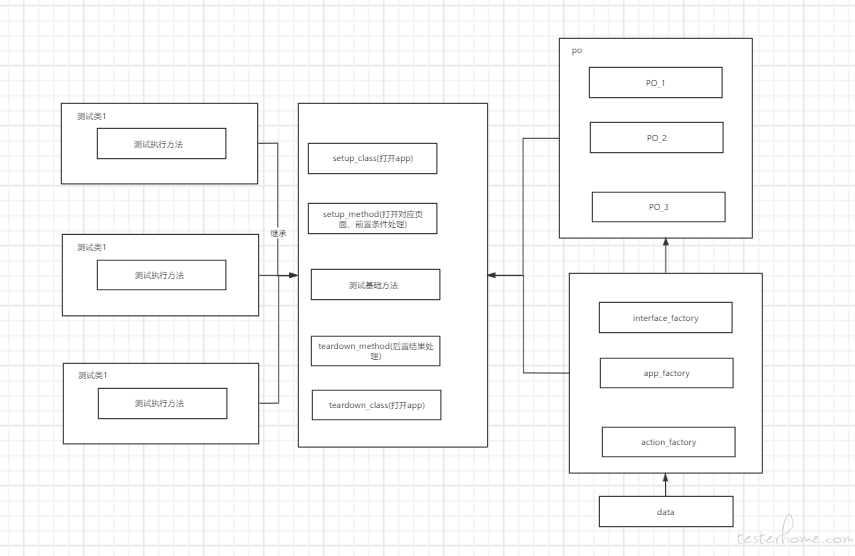
第一条冒烟用例跑过了,但是随着后续增加其他类型的用例,每写一个用例,就要多加一个 py 文件,然后把 setup\teardown\test 方法都写一遍,中间存在大量的冗余代码,而且稍有改动,跟着要改的地方很多。因此,想到了要对结构进行细化分层,主要改动如下:
采用 PO 模式,以页面维度,将页面操作封装起来,方便调用和组合
抽提所有测试执行的共同点,为一个测试基类,测试类继承基类然后进行扩展,方便维护和优化
将公共方法的维度细化,将涉及移动设备操作、接口通用请求操作单独拆分为不同文件,方便区分和调用
这一时间结构如下:
3.方便管理
经过 1、2 步骤,现在对于多个页面的多个功能的操作,都可以有效组织起来,而且对于单个页面或者功能的改动对其他页面、功能的影响也达到减少
但是,新的问题又出现了:一个页面可能存在多个用例执行的动作模式都一样的(打开页面 -- 点击元素 -- 获取执行结果 -- 写入执行结果 --- 结束本次执行),区别只是依赖的数据不同,最初采用的每次手动变更数据,时间异常繁琐而且易错,并且不能一次执行多个相同行为模式不同数据的用例,所以说到这里,变更之道呼之欲出,需要对用例的数据采取参数话的方式:
"p1","p2" [(p11,p21),(p12,p22)]
)
具体参数话方式,这里我不班门弄斧了,大家可以自行百度学习
4.方便执行
呃,没错,和方便管理数据一起产生的新的问题:如何方便快捷选的用例执行范围?
每次执行需要选择用例集合的某一种或者某几个来执行,最开始,我采用的执行前注释掉不执行的用例,后来发现实在太麻烦了,而且有疏漏风险,所以查阅资料,最终选择的方案是,给用例打标签
然后执行命令的时候,只需要在 pytest 命令后加 “-k 'm1'”,就可以选定标记含有 “m1” 的用例了(这里想说的一点是,不用 -m ,是我需要模糊匹配这个参数是精确匹配标记的)
5.方便分享
前面说了这么多,天花乱坠的,结果也只能在我一人的本地看到,领导同事每次都要询问我获取执行情况,因此在领导的建议下,还是接入了公共平台,实现的云端发送任务到本地执行,然后回收结果至云端,具体的平台不做过多介绍,大家使用 Jenkins 即可达到相同效果,这个过程想要提及的其实是获取云端下发参数作为用例的启动参数的经验,
举个例子:测试基类支持 2 种运行模式: p1\p2,主要靠实例变量 C1 的 2 个枚举值进行判断切换,在本地运行时,我们可以手动修改不同的枚举,但是现在上云了,我们想通过命令行给用例方法传参,到达动态控制的效果,这周情况下,就可以利用 pytest_addoption + pytest.feature
大致的思路,就是使用 pytest_addoption 指定读取我们自定义的参数对于的参数值,而用 pytest.feature 将参数做处理并传递给测试方法
# 读取指定参数
def pytest_addoption(parser):
parser.addoption("--param", default= "False", action="store", help="need background wake up before run case", dest="para")
# 获取参数作为返回值
@pytest.fixture(autouse=True)
def read_param(request):
logger.info(f"read param:{request.config.getoption('--need_wake_up')}", )
return request.config.getoption("--need_wake_up")
# 将参数进一步处理获得最终可使用的值
@pytest.fixture(autouse=True)
def set_param(request, read_param):
read_need_wake_up = get_target_from(read_param, bool_pattern).title()
if read_need_wake_up == "True":
param = True
else:
param = False
logger.info(f"set param :{param}" )
return param
def get_target_from(s: str, pattern: str) -> str:
match = re.search(pattern, s)
if match:
return match.group(1)
return ""
# 测试方法
def test_1(set_need_wake_up):
print(f"need_wake_up:{set_need_wake_up}")
pass
具体使用教程可查看 : https://blog.51cto.com/u_15688254/5391586
6.方便可视化
关于数据可视化,这个是正在接洽的内容,大概规划也是利用已有的轮子,即 生成 allure 报告,然后将报告上传到平台上查看,这个只需要在 pytest 命令后面加上
--alluredir=.\temps
7.总结
罗马不是一天建成的,同样自己在做这个项目的时候,也是一步步摸索着前进,慢慢优化的,我想任何一个好的项目也多少这样不断迭代出来的,工作最是让人成长,这个话真是干的越久越有体验。
从非计算机科班转行到测试行业,从最简单的手工测试到自动化测试,自己在上一个公司是做 Java 的 web 自动化,现在的工作切换到 APP + WEB + 端,工作内容变多变杂,强度变大,但是也学到了更多东西,就这个项目而言,做下来,对 python 的基础语法、UIautomator 的使用,pytest 的强大与灵活都有了更深刻的了解,未来也希望参与更多测试框架和工作的学习和创造,加油!希望各位大佬也不吝赐教
 ,后面发现太杂,后续就一个项目对应一个端,然后直接挂到 Jenkins 上进行定时任务,生成 allure 报告。
,后面发现太杂,后续就一个项目对应一个端,然后直接挂到 Jenkins 上进行定时任务,生成 allure 报告。