一、背景
搜索推荐算法架构为京东集团所有的搜索推荐业务提供服务,实时返回处理结果给上游。部门各子系统已经实现了基于 CPU 的自适应限流,但是 Client 端对 Server 端的调用依然是 RR 轮询的方式,没有考虑下游机器性能差异的情况,无法最大化利用集群整体 CPU,存在着 Server 端 CPU 不均衡的问题。
京东广告部门针对其业务场景研发的负载均衡方法很有借鉴意义,他们提出的 RALB(Remote Aware Load Balance) 算法能够提升下游服务集群机器 CPU 资源效率,避免 CPU 短板效应,让性能好的机器能够处理更多的流量。我们将其核心思想应用到我们的系统中,获得了不错的收益。
本文的结构如下:
1.RALB 简介
◦简单介绍了算法的原理。
2.功能验证
◦将 RALB 负载均衡技术应用到搜索推荐架构系统中,进行功能上的验证。
3.吞吐测试
◦主要将 RALB 和 RR 两种负载均衡技术做对比。验证了在集群不限流和完全限流的情况下,两者的吞吐没有明显差异。在 RR 部分限流的情况下,两者吞吐存在着差异,并且存在着最大的吞吐差异点。对于 RALB 来说,Server 端不限流到全限流是一个转折点,几乎没有部分限流的情况。
4.边界测试
◦通过模拟各种边界条件,对系统进行测试,验证了 RALB 的稳定性和可靠性。
5.功能上线
◦在所有 Server 端集群全面开启 RALB 负载均衡模式。可以看出,上线前后,Server 端的 QPS 逐渐出现分层,Server 端的 CPU 逐渐趋于统一。
二、RALB 简介
RALB 是一种以 CPU 均衡为目标的高性能负载均衡算法。
2.1 算法目标
1.调节 Server 端的 CPU 使用率,使得各节点之间 CPU 相对均衡,避免 CPU 使用率过高触发集群限流
2.QPS 与 CPU 使用率成线性关系,调节 QPS 能实现 CPU 使用率均衡的目标
2.2 算法原理
2.2.1 算法步骤
1.分配流量的时候,按照权重分配(带权重的随机算法,wr)
2.收集 CPU 使用率:Server 端通过 RPC 反馈 CPU 使用率(平均 1s)给 Client 端
3.调权:定时(每 3s)根据集群及各节点上的 CPU 使用率(窗口内均值)调节权重,使各节点 CPU 均衡
2.2.2 指标依赖
| 编号 | 指标 | 作用 | 来源 |
|---|---|---|---|
| 1 | IP | 可用 IP 列表 | 服务注册发现和故障屏蔽模块进行维护 |
| 2 | 实时健康度 | IP 可用状态实时变化,提供算法的边界条件 | RPC 框架健康检查功能维护 |
| 3 | 历史健康度 | 健康度历史值,用于判断 ip 故障及恢复等边界条件 | 指标 2 的历史值 |
| 4 | 动态目标(CPU 使用率) | 提供均衡算法的最直接目标依据 | Server 端定时统计,RPC 框架通过 RPC 返回 |
| 5 | 权重 weight | 实时负载分发依据 | 算法更新 |
2.2.3 调权算法

2.2.4 边界处理
边界 1:反馈窗口(3s)内,如果下游 ip 没被访问到,其 CPU 均值为 0,通过调权算法会认为该节点性能极好,从而调大权重
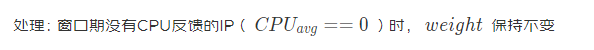
边界 2:网络故障时,RPC 框架将故障节点设为不可用,CPU 和权重为 0;网络恢复后,RPC 框架将 IP 设置为可用,但是权重为 0 的节点分不到流量,从而导致该节点将一直处于不可用状态
处理:权重的更新由定时器触发,记录节点的可用状态,当节点从不可用恢复为可用状态时,给定一个低权重,逐步恢复
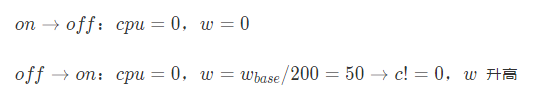
2.3 落地关键
既要快又要稳,在任何情况下都要避免陷入僵局和雪崩,尤其要处理好边界条件
算法要点:
1.公式中各依赖因子的更新保持独立的含义和更新机制,以维护算法的可靠和简洁
◦IP 列表的更新由服务注册发现和 RPC 框架共同保证
◦RPC 更新 CPU
2.注意边界值的含义,边界值的含义需要区分连续值
◦CPU = 0,表示未知,不表示 CPU 性能好
◦w = 0,表示不会被分配流量,只有在不可用的情况下才为 0;可用情况下,应该至少有一个较小的值,保证仍能触发 RPC,进而可以更新权重
3.算法更新权重,不要依赖 RPC 触发,而应该定时更新
三、功能验证
3.1 压测准备
| Module | IP | CPU |
|---|---|---|
| Client 端 | 10.173.102.36 | 8 |
| Server 端 | 11.17.80.238 | 8 |
| 11.18.159.191 | 8 | |
| 11.17.191.137 | 8 |
3.2 压测数据
| 指标 | RR 负载均衡 | RALB 负载均衡 |
|---|---|---|
| QPS |
|
|
| CPU |
|
**** |
| TP99 |
|
|
由于机器性能差距不大,所以压测的 CPU 效果并不明显,为了使 CPU 效果更明显,给节点” 11.17.80.238“施加起始的负载 (即无流量时,CPU 使用率为 12.5%)
| 指标 | LA 负载均衡 | RR 负载均衡 | RALB 负载均衡 |
|---|---|---|---|
| QPS |
|
|
|
| CPU |
|
|
|
| TP99 |
|
|
|
3.3 压测结论
经过压测,RR 和 LA 均存在 CPU 不均衡的问题,会因为机器资源的性能差异,而导致短板效应,达不到充分利用资源的目的。
RALB 是以 CPU 作为均衡目标的,所以会根据节点的 CPU 实时调整节点承接的 QPS,进而达到 CPU 均衡的目标,功能上验证是可用的,CPU 表现符合预期。
四、吞吐测试
4.1 压测目标
RALB 是一种以 CPU 使用率作为动态指标的负载均衡算法,能很好地解决 CPU 不均衡的问题,避免 CPU 短板效应,让性能好的机器能够处理更多的流量。因此,我们期望 RALB 负载均衡策略相比于 RR 轮询策略能够得到一定程度的吞吐提升。
4.2 压测准备
Server 端 100 台机器供测试,Server 端为纯 CPU 自适应限流,限流阈值配置为 55%。
4.3 压测数据
通过压测在 RALB 和 RR 两种负载均衡模式下,Server 端的吞吐随着流量变化的趋势,对比两种负载均衡策略对于集群吞吐的影响。
4.3.1 RALB
4.3.1.1 吞吐数据
下表是 Server 端的吞吐数据,由测试发压 Client 端,负载均衡模式设置为 RALB。在 18:17Server 端的状况接近于刚刚限流。整个压测阶段,压测了不限流、部分限流、完全限流 3 种情况。
| 时间 | 17:40 | 17:45 | 17:52 | 18:17 | 18:22 |
|---|---|---|---|---|---|
| 总流量 | 2270 | 1715 | 1152 | 1096 | 973 |
| 处理流量 | 982 | 1010 | 1049 | 1061 | 973 |
| 被限流量 | 1288 | 705 | 103 | 35 | 0 |
| 限流比例 | 56.74% | 41% | 8.9% | 3.2% | 0% |
| 平均 CPU 使用率 | 55% | 55% | 54% | 54% | 49% |
4.3.1.2 指标监控
Server 端机器收到的流量按性能分配,CPU 保持均衡。
| QPS | CPU |
|---|---|
4.3.2 RR
4.3.2.1 吞吐数据
下表是 Server 端的吞吐数据,由测试发压 Client 端,负载均衡模式设置为 RR。在 18:46 Server 端的整体流量接近于 18:17 Server 端的整体流量。后面将重点对比这两个关键时刻的数据。
| 时间 | 18:40 | 18:46 | 19:57 | 20:02 | 20:04 | 20:09 |
|---|---|---|---|---|---|---|
| 总流量 | 967 | 1082 | 1149 | 1172 | 1263 | 1314 |
| 处理流量 | 927 | 991 | 1024 | 1036 | 1048 | 1047 |
| 被限流量 | 40 | 91 | 125 | 136 | 216 | 267 |
| 限流比例 | 4.18% | 8.4% | 10.92% | 11.6% | 17.1% | 20.32% |
| 平均 CPU 使用率 | 45%(部分限流) | 51%(部分限流) | 53%(部分限流) | 54%(接近全部限流) | 55%(全部限流) | 55%(全部限流) |
4.3.2.2 指标监控
Server 端收到的流量均衡,但是 CPU 有差异。
| QPS | CPU |
|---|---|
|
|
4.4 压测分析
4.4.1 吞吐曲线
根据 4.3 节的压测数据,进行 Server 端吞吐曲线的绘制,对比 RALB 和 RR 两种负载均衡模式下的吞吐变化趋势。
import matplotlib.pyplot as plt
import numpy as np
x = [0,1,2,3,4,5,6,7,8,9,9.73,10.958,11.52,17.15,22.7]
y = [0,1,2,3,4,5,6,7,8,9,9.73,10.61,10.49,10.10,9.82]
w = [0,1,2,3,4,5,6,7,8,9.674,10.823,11.496,11.723,12.639,13.141,17.15,22.7]
z = [0,1,2,3,4,5,6,7,8,9.27,9.91,10.24,10.36,10.48,10.47,10.10,9.82]
plt.plot(x, y, 'r-o')
plt.plot(w, z, 'g-o')
plt.show()
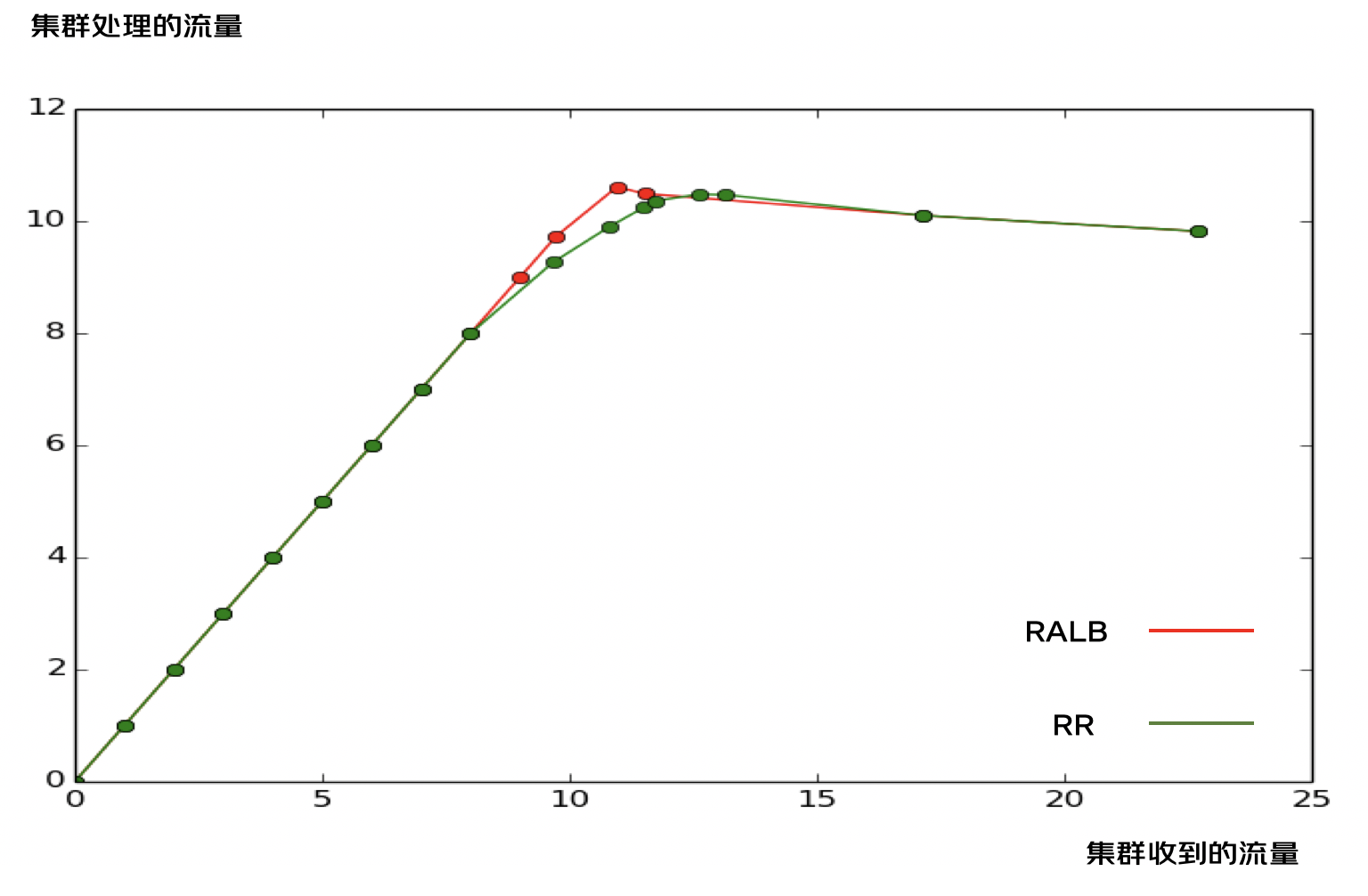
4.4.2 曲线分析
| 负载均衡策略 | RALB | RR |
|---|---|---|
| 阶段一:所有机器未限流 | 接收 QPS=处理 QPS,表现为 y =x 的直线 | 接收 QPS=处理 QPS,表现为 y =x 的直线 |
| 阶段二:部分机器限流 | 不存在 RALB 根据下游 CPU 进行流量分配,下游根据 CPU 进行限流,理论上来讲,下游的 CPU 永远保持一致。所有的机器同时达到限流,不存在部分机器限流的情况。 所以在图中,不限流与全部机器限流是一个转折点,没有平滑过渡的阶段。 | RR 策略,下游的机器分配得到的 QPS 一致,由于下游根据 CPU 进行限流,所以不同机器限流的时刻有差异。 相对于 RALB,RR 更早地出现了限流的情况,并且在达到限流之前,RR 的吞吐是一直小于 RALB 的。 |
| 阶段三:全部机器限流 | 全部机器都达到限流阈值 55% 之后,理论上,之后无论流量怎样增加,处理的 QPS 会维持不变。图中显示处理的 QPS 出现了一定程度的下降,是因为处理限流也需要消耗部分 CPU | RR 达到全部限流的时间要比 RALB 更晚。在全部限流之后,两种模式的处理的 QPS 是一致的。 |
4.5 压测结论
临界点:吞吐差异最大的情况,即 RALB 模式下非限流与全限流的转折点。
通过上述分析,可以知道,在 RALB 不限流与全部限流的临界点处,RR 与 RALB 的吞吐差异最大。
此时,计算得出 RALB 模式下,Server 集群吞吐提升 7.06%。
五、边界测试
通过模拟各种边界条件,来判断系统在边界条件的情况下,系统的稳定性。
| 边界条件 | 压测情形 | 压测结论 |
|---|---|---|
| 下游节点限流 | CPU 限流 | 惩罚因子的调整对于流量的分配有重要影响 |
| QPS 限流 | 符合预期 | |
| 下游节点超时 | Server 端超时每个请求,固定 sleep 1s | 请求持续超时期间分配的流量基本为 0 |
| 下游节点异常退出 | Server 端进程被杀死直接 kill -9 pid | 杀死进程并自动拉起,流量分配快速恢复 |
| 下游节点增减 | Server 端手动 Jsf 上下线 | jsf 下线期间不承接流量 |
| Server 端重启 stop + start | 正常反注册、注册方式操作 Server 端进程,流量分配符合预期 |
六、功能上线
宿迁机房 Client 端上线配置,在所有 Server 端集群全面开启 RALB 负载均衡模式。可以看出,上线前后,Server 端的 QPS 逐渐出现分层,Server 端的 CPU 逐渐趋于统一。
| 上线前后 Server 端 QPS 分布 | 上线前后 Server 端的 CPU 分布 |
|---|---|
参考资料
1.负载均衡技术
2.深入浅出负载均衡
作者:京东零售 胡沛栋
来源:京东云开发者社区