前言
对于数据仓库的测试来说底层的系统会有很多有自建的集群使用 spark 或者 flink 测试,也有很多直接使用云厂商的产品比如 datworks 等等,再这里我想分享下抛开环境,只对数据仓库测试的一些小心得。
数仓分层设计
标准数仓分为 ODS,DWD,DIM,DWS,ADS 等,每一层都有自己的含义:
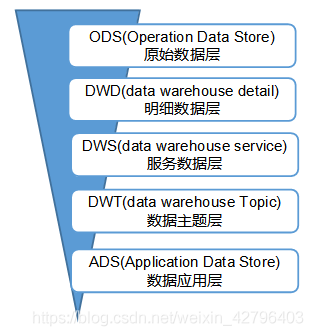
ODS:存储原始业务数据,数据原封不动同步到到 ODS,不做任何修改,并且备份,备份时可以压缩;
DWD:数据清洗,脱敏,规范化,一般保持和 ODS 层一样的数据粒度,并且提供一定的数据质量保证。同时,为了提高数据明细层的易用性,该层会采用一些维度退化手法,将维度退化至事实表中,减少事实表和维表的关联,代表业务最小粒度层。任何数据的记录都可以从这一层获取,为后续的 DWS 做准备。另外,在该层也会做一部分的数据聚合,将相同主题的数据汇集到一张表中,提高数据的可用性;
DIM: DWD 同级别维度,比如时间维度、用户维度、权限维度、省份维度等;
DWS:又称数据集市或宽表。按照业务划分,比如订单,用户,商家,商品等,基于各个主题在加工和使用,进行轻度汇总,如统计各个主题 7 天,30 天,90 天的行为,用户购买行为,商品动销行为等,在 DWD 基础上关联 DIM 维度数据汇总,用于提供后续的业务查询,OLAP 分析等;
ADS:要是提供给数据产品和数据分析使用的数据,一般会存放在 ES、ClickHouse、Redis 等系统中供线上系统使用,也可能会存在 Hive 或者 Druid 中供数据分析和数据挖掘使用,一般在 DWS 基础上生成指标,主题宽表,主要用于具体的业务服务。
TEMP:每一层的计算都会有很多临时表,专设一个 temp 层来存储我们数据仓库的临时表。
数仓测试
数仓测试其实和其他域的测试一样都有需求评审,预发环境测试回归和上生产的步骤。
不同的是数仓测试的时候需要确定的口径。举个例子:淘宝商家半年内的销售情况,看到这个口径会认为只要值对了就可以了,其实不是,需要考虑这个商家的类别(统计企业的商家还是个人商家),商家的状态(注销,正常)等
数据的类型测试
1.黑盒测试
所谓黑盒的数据测试就是已数据结果为准对数据进行校验需要测试的有:
- 检查表结构是否与设计文档一致
- 主键是否唯一
- 字段非空非 null 判断
- 非正常值判断
- 枚举准确性
如果是关于金额类型的是否有负数
数据是否有效合理
关于以上校验的一些 sql 样例
唯一性
--sku唯一,无重复记录
SELECT sku_id
,count(1)
FROM xxx.ads_xxx_sku
WHERE pt = '20221211'
GROUP BY sku_id
HAVING count(1) > 1
;
判断为 null
--空值判断
SELECT sku_id,sku_name
FROM xxx.ads_xxx_sku
WHERE pt = '20221211'
and (sku_id IS NULL OR sku_name IS NULL)
;
判断是否为空
select sku_id,sku_name
from xxx.ads_xxx_sku
where pt='20221211'
and (sku_id="" or sku_name="")
负值判断
select price
from xxx.ads_xxx_sku
where pt='20221211'
枚举判断
SELECT distinct(sku_name)
FROM from xxx.ads_xxx_sku
WHERE pt = '20221211'
;
2.白盒测试
需要对开发的代码走读,check 指标处理逻辑。同时测试也需要准备验证脚本,或者查找到可以作为验证参考的数据,便于口径核对,这个环节,对测试人员的指标口径沉淀有一定的要求。在发现指标数据存在差异的情况,需要协助开发人员一起定位差异原因,时常需要在现有的口径基础上,在数仓空间往上翻多层,或者一个指标定义不够清晰,需要自行去数分空间查找口径定义。另外,在测试通过后,需要编写相应的 DQC 脚本,及时监控生产数据质量。这些对测试来说,需要有一定的 sql 功底;
- 字段长度、最大最小值、异常值、边界等
- 计算单位是否统一
- 常见函数,比如 dateadd 等日期函数的时间偏差
- 查看调度配置是否缺少依赖
关于以上情况举下一些实际案例
使用的是 DATEADD 函数,统计近 6 天数据,需往前推 5 天,对应的前置条件应调整为 ‘-5’
BETWEEN TO_CHAR(DATEADD(TO_DATE('${bizdate}','yyyyMMdd'), -6,'dd'),'yyyyMMdd')
字段未做默认处理,数值字段一般默认为 0,字符串默认为 ‘’;
nvl(t22.spu_bid_cnt_30d,0) as spu_bid_cnt_30d -- 近30天_出价spu数
,nvl(t17.spu_cnt_td,0) as spu_cnt_td -- 当天动销商品数
,nvl(t22.spu_inv_num_7d,0) as spu_inv_num_7d -- 近七天_在售商品数
,t22.spu_inv_num_30d as spu_inv_num_30d -- 近30天_在售商品数
常用的测试方法
DQC 校验
在日常测试时,常会遇到一种迁移任务和重构任务,此类任务对于原先的指标和口径几乎是没有任何差别,这个时候 DQC 校验可以方便快捷的来解决
通常使用的方法如下:
SELECT t1.xxx_id AS xxid
,t1.xxx_month AS xx统计时间
,t1.xxx_rate AS xx率
,t2.xxx_rate AS 旧xx率
FROM (
SELECT xxx_id
,xxx_month
,xxx_rate
FROM newtalbe
WHERE pt = '20221011'
) t1 inner JOIN (
SELECT xxx_id
,xxx_time
,xxx_rate
FROM oldtable
WHERE pt = '20221011'
) t2
ON t1.xxx_id = t2.xxx_id
AND t1.xxx_month = t2.xxx_time
where t1.xxxx_rate <> t2.xxxx_rate
血缘横向对比
测试过程中往往会发现数据对不上或者枚举不对的情况,为了进一步排查我们就需要通过血缘关系,来了解我们字段的来源是否错误。
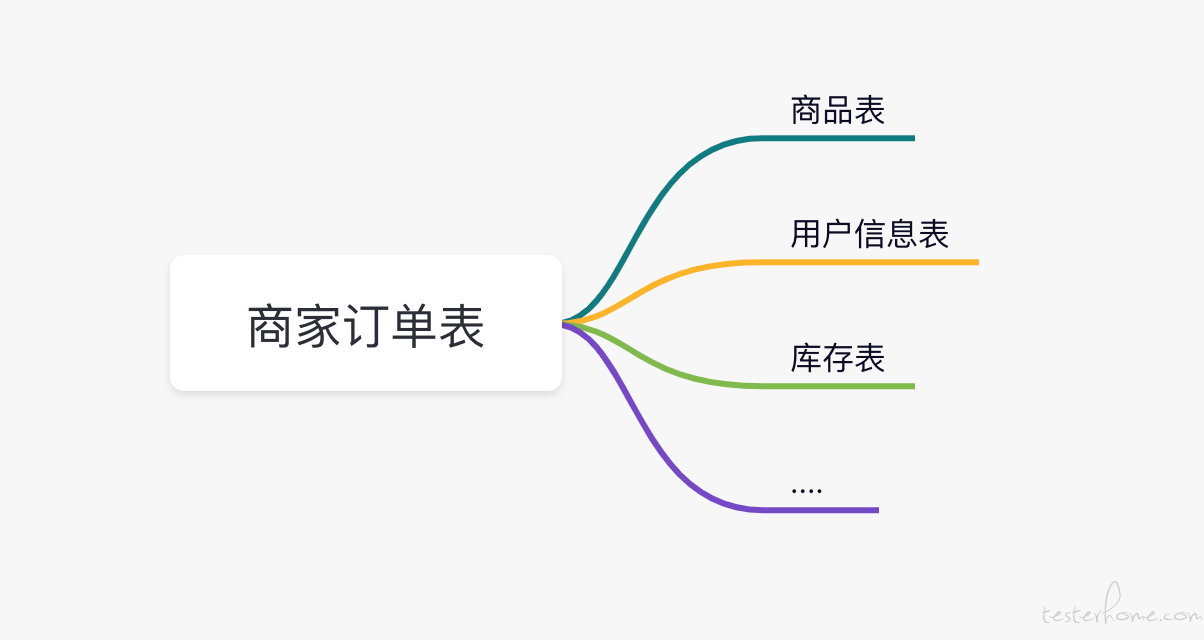
比如以上表如果商家订单表中的内容有错误,可以通过 sql 先查看字段的来源,然后通过血缘关系来看表中的字段是否有问题,对问题根因逐个进行排查
设置质量监控
在上线时,我们回对重要的表进行监控,为了就是保证数据质量的完整性、一致性、及时性和准确性
- 完整性是指数据的记录和信息是否完整,是否存在数据缺失情况。数据缺失主要包括记录的缺失和具体某个字段信息的缺失,两者都会造成统计结果不准确。完整性是数据质量最基础的保障.
- 准确性是指数据中记录的信息和数据是否准确、是否存在异常或者错误的信息。例如,订单中出现错误的买家信息等,这些数据都是问题数据。确保记录的准确性也是保证数据质量必不可少的一部分。
- 一致性通常体现在跨度很大的数据仓库中。 例如,某公司有很多业务数仓分支,对于同一份数据,在不同的数仓分支中必须保证一致性。例如,从在线业务库加工到数据仓库,再到各个数据应用节点,用户 ID 必须保持同一种类型,且长度也要保持一致。
- 及时性保障数据的及时产出才能体现数据的价值。例如,决策分析师通常希望当天就可以看到前一天的数据。若等待时间过长,数据失去了及时性的价值,数据分析工作将失去意义。
总结
以上是我对数仓测试的一些小心得,也希望能够让大家了解数据测试,如果有什么不对或者建议请留言