测试基础 善用 Go Fuzzing,写出更完整的单元测试
编译:TesterHome
作者:Larry Lu

Go 在今年 3 月推出的新特性 — Fuzzing Test(模糊测试),是一种跟单元测试截然不同的测试方式。
为了让更多人知道 Fuzzing 这个有趣的新功能,带大家认识一下 Go Fuzzing
Unit Testing(单元测试)
首先介绍一个简单的例子:就只是一个非常简单的 pow(x, y) 函数,内部实际操作是用递回来计算 x 的 y 次方,就算没写过 Go 应该也看得懂。
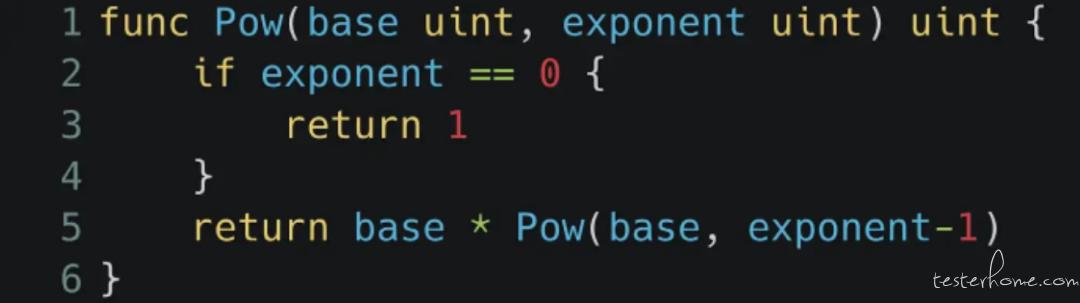
那如果我们要帮这个 pow(x, y) 写单元测试,可能会怎么写呢?
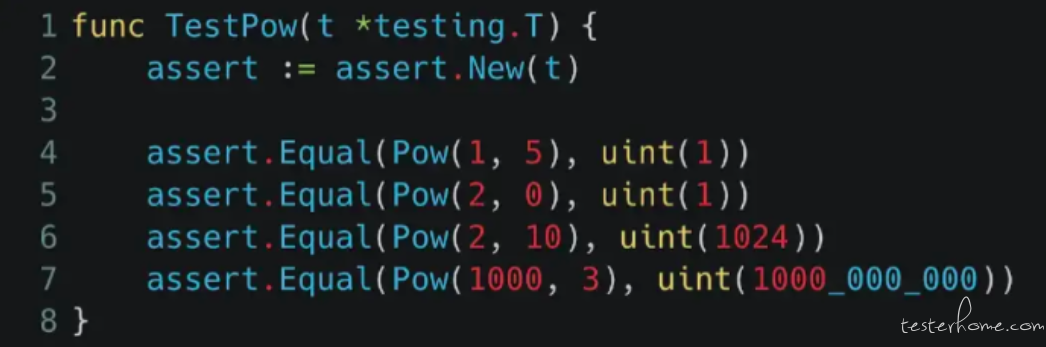
无非就是找几个简单的例子测试看看(下图),比如说 “1⁵ 是 1”、“2⁰ 是 1”、“2¹⁰ 是 1024” 等等。如果这几个例子都没问题,那我们就相信这个 pow(x, y) 应该没有写错。
但我们重新思考一下,像这样的单元测试可能有这样的问题:
首先是 “需要几个 test case 才能够确保正确性?”,像上图的单元测试只测了四组 input/output,如果这样就说 pow(x, y) 的实际操作是完全正确的,显然是有点没有说服力。
再来是,通常我们在帮自己的程序写单元测试时,并不容易想到各种 edge case(边缘情况、边缘案例),所以时常会发生 “我之前测都没问题” 但是到用户那边就因为奇怪的输入跟行为而 “炸掉”。
Fuzzing Test(模糊测试)
而 Go 在版本 1.18 推出的 Fuzzing 正好弥补了单元测试的不足。Fuzzing 是一种自动化的测试技术,它会不断丢出各种随机生成的 input 给你,让你拿去做测试。
下面这段代码,就是用 Go 的 Fuzzing engine 每次都帮我们随机生成一个 unsigned int 叫做 x(第二行),接着用这个随机生成的 x 去做 assert。但这边有一个跟单元测试很不一样的地方:因为我们并不知道 x 是多(毕竟是随机生的),所以我们必须在不知道 x 是多少的情况下去写 assert。
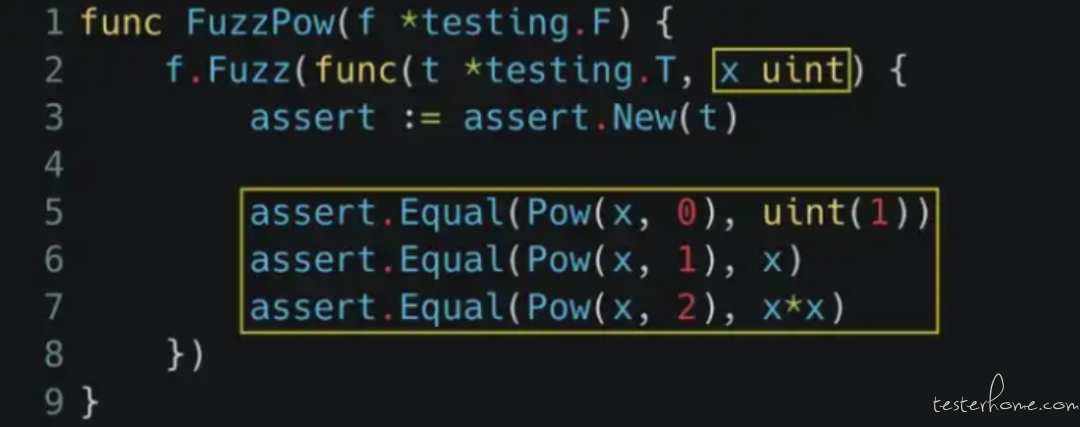
虽然听起来有点荒谬,连输入都不知道那我是要测个鬼啊!?但其实是可以的!只是要用一些旁敲侧击的方式去写 assert。比如说我们知道 “不管 x 是多少,pow(x, 0) 一定等于 1(第五行)”、“不管 x 是多少,pow(x, 1) 一定等于 x 本身”。
用这样的方式,我们就可以在 “不知道 x 是多少” 的前提下,去验证 pow(x, y) 有没有写错,如果在某些特殊情况下 pow(x, 0) 算出来不等于 1,那就代表 pow(x, y) 铁定是写错了!
写完 Fuzzing Test 后马上到终端机下 go test -fuzz=Fuzz -fuzztime 20s 跑跑看,因为 Fuzzing engine 会不断生成随机的输入,所以要限制他跑 20 秒就好,不然他就会一直跑一直跑直到找到错为止。
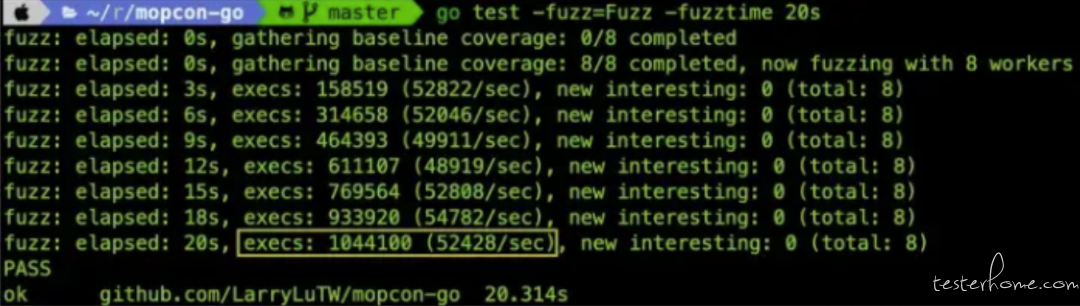
仔细看一下跑的结果,这 20 秒的时间他执行了 1044100 次的测试(倒数第三行),也就是 Fuzzing engine 总共生成了一百多万个随机的 x,然后丢进去我们写的三个 assert 做验证,最后都顺利 PASS 了 。
更多的 Fuzzing Test
但光是测这三个简单的 assert 好像没什么说服力,所以接着我们来加一些更复杂的条件。我们想要测试的是:当随机的 x 跟 y 都大于零时,“x 的 y 次方再除以 x” 一定要等于 “x 的 y-1 次方”。这应该挺好理解的,就像 2¹⁰/2 就是 2⁹ 也就是 512。
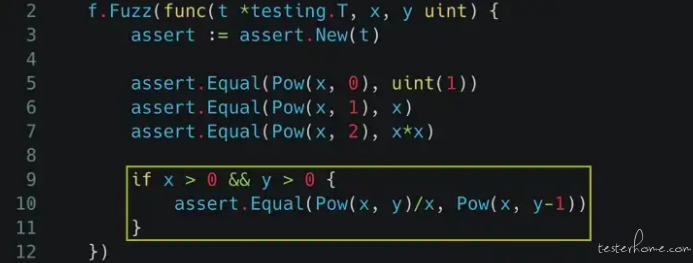
这个 assert 听起来听经地义,而且也是会写在数学课本上的东西,实际跑跑看却不知为何失败了,难道是以前数学课都教错了吗?
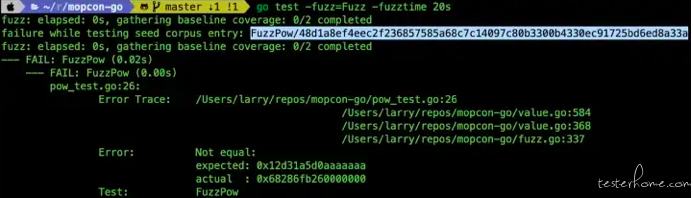
在做 Fuzzing Test 的时候如果跑一跑就失败了,Go 会帮忙把那组 input 记在 testcase/ 里,所以先别急着下定论,我们来看一下到底是怎么样的 x 跟 y 会让这个 assert 失败。

看了之后会发现在 x=6、y=30 时 assert 会失败,也就是说 pow(6, 30)/6 不会等于 pow(6, 29)。但这也太奇怪了吧?仔细试验之后才发现是因为在计算 pow(6, 30) 的时候会发生 overflow。
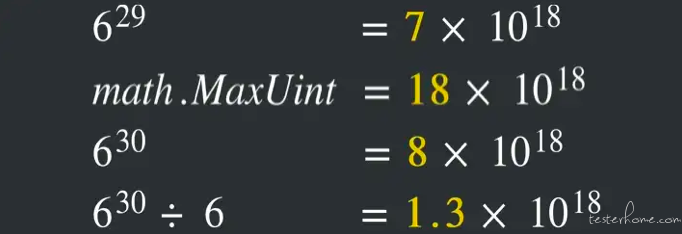
因为 Go 定义的 max.MaxUint 大概是 18 * 10¹⁸,但 6²⁹大概是 7 * 10¹⁸。如果把 6²⁹再乘上 6,就会发生 overflow 得到 8 * 10¹⁸,很像绕了操场两圈结果在跟原本差不多的位置。
所以如果把 overflow 过的 6³⁰ 拿去除以 6,就会跟 6²⁹不一样。这就是 Fuzzing 帮我们找到的 edge case,也是我们当初没想到的。
Improved Pow
仔细想想,pow(x, y) 在计算的过程中会不会发生 overflow 完全取决于使用者的输入是多少。因此我们不可能避免 overflow,但至少我们能在 overflow 发生时让使用者知道,而不是已经乘到 overflow 还继续装没事,这样可能有一天会导致我们想都没想过的 bug。
依据这个想法,我们可以帮 pow 多加一个 error type 的回传值,如果在计算的过程中不幸发生 overflow,就可以回传 ErrOverflow,让使用者自己决定要怎么处理。
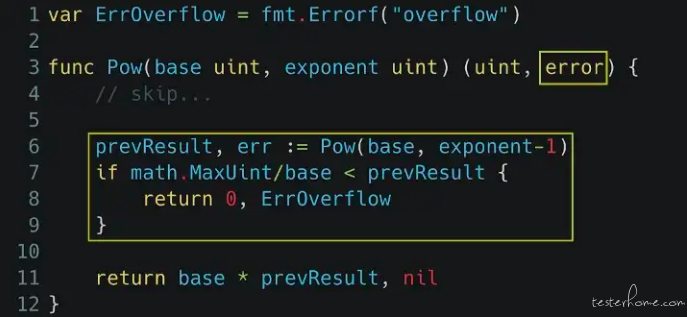
既然 pow(x, y) 的实际操作改了,那测试当然也要改一下:单元测试除了验证结果之外,还要检查看看有没有错误,像 pow(2, 10) 就不应该有错误、而 pow(6, 30) 则会得到 ErrOverflow。
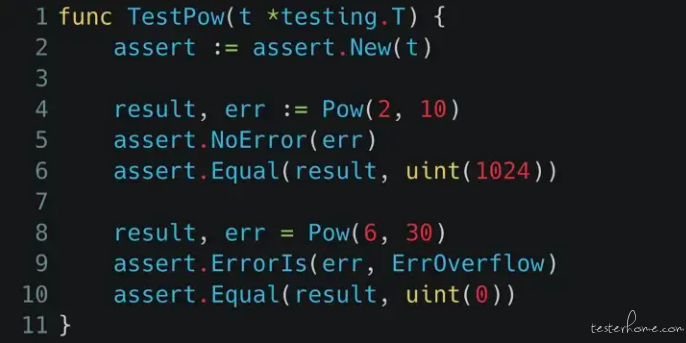
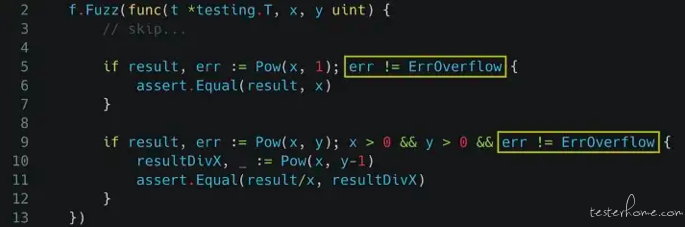
下面的 Fuzzing Test 也是,如果在计算过程中已经发生 overflow,算出来的结果自然是错误的,所以我们就不去跑 assert 了。但如果没发生 overflow,那该做的 assert 还是要做。
处理完 overflow 的问题之后再跑一次 Fuzzing Test,马上就过了~
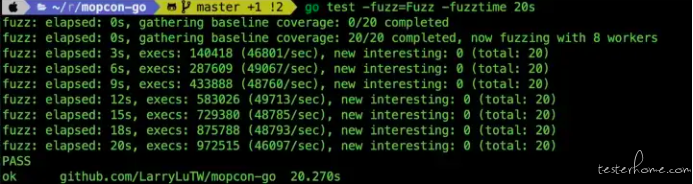
让我们回顾一下,在整个测试 pow(x, y) 的过程中,Fuzzing 最大的贡献就是帮我们找出 “pow(6, 30) / 6 不等于 pow(6, 29)” 这个 edge case,从而让我们去思考当 overflow 发生时,是不是应该要 return 一个 ErrOverflow 让使用者去处理。真的很不错!
对比
到现在如果大家都看懂的话,不难发现 Unit Test 跟 Fuzzing 在测试的方式很不一样:
首先 Unit Test 就是固定那几个 test case,而 Fuzzing 是每次会不断给你随机生成的 input 去测试,因此更容易找到 edge case,这是 Fuzzing 的优点。
其次是当我们在做 Unit Test 时,我们都是直接验证答案是多少,比如说我们知道 “pow(2, 10) 就是 1024”,所以就直接 assert(pow(2, 10), 1024)。
但在做 Fuzzing Test 的时候,我们根本不知道输入的 x、y 是多少,所以我们只能在不知道输入的情况下,用答案的性质(property)或是数学定理来 assert,比如说 “任何数的 0 次方都是 1”、“x 的 y 次方再除上 x 会变成 x 的 (y-1) 次方” 这样拐弯抹角的方式,所以写起来会比较困难、迂回一点。
Fuzzing Test 的威力
因为今天讲的 pow 蛮简单的,大家可能还感觉不到 Fuzzing Test 的威力,接下来带大家来看一下 Fuzzing 曾经发现过怎么样的 bug。
compile: hangs converting int const to complex64
首先这个例子是,Go 1.6 的编译器在编译下面这个程序时(没错就只有两行)会直接卡住。通常编译器的工作就是要把正确的代码编译成执行档、若是代码有错则是要显示编译失败。

但上面这个程序一编译下去就 “卡住了”,没错就是卡住...,可能在什么地方进入了无穷循环或是 deadlock,所以一动也不动。
constant: hang evaluating “-6e-1886451601”
而另外下面这个例子是在 Go 1.9 中,虽然通过编译了,但程序只要一跑就会直接当掉,永远没有结束的一天。

这两个例子的共通点是:虽然他们的代码很短,但里面都有一些怪怪的数字。因此如果不利用 Fuzzing 丢随的 input 进去跑,光靠人为方式是很难找到这种 bug 的,也再次验证了 Fuzzing 在找 edge case 上非常厉害。
总结
edge case 虽然平常不容易遇到,但当多次发生的时候,层层叠加起来是有可能造成安全漏洞的。另外,Fuzzing Test 虽然是比较新的东西,但它并不是用来取代 Unit Test 的,它只是利用大量随机的输入来帮你找到可能有问题的 edge case。
找到 edge case 后你还是要把它们加进单元测试里,让你的单元测试变得更健壮,就如同这篇的标题说的 “善用 Go Fuzzing,帮助你写出更完整的单元测试”,因此我认为两者没有谁强谁弱,是相辅相成的关系。