专栏文章 测试环境的故事-01 测试环境数据库的搭建
不仅是测试栏目,没有太多的高大上理念,只有一个话题,如何想办法解决你的问题.
从实践中学习,从实践中练习, 这些是领导不会告诉你的
测试人员习惯了别人准备好的环境,别人准备好的数据库,往往一有问题一方面担惊受怕,一方面有抱怨其他组为什么没有做好这些事情,而自己又很少有机会去尝试这些事情,而我刚好有一次小小的机会来进行构建一个测试环境数据库. 不做不知道,做完之后还是有点担惊受怕.
实践让你踩坑,也让你获得新的知识.
1. 缘起,构建测试环境了
由于是小团队,那么一开始就只有两个环境,一个 DEV,一个生产环境,随着规模的扩张,需要搭建一个测试环境,那么测试环境,就需要一个测试数据库.
所以目标很明确,就是:
- 复制 DEV 环境的数据库到测试环境
- 复制 DEV 环境的数据到测试环境
目前我们使用的是 postgresql 数据库,所以也就是对 postgresql 数据库做以上的操作
2.实施,踩坑记录
把 DEV 环境的数据库复制到一个新的环境,需要做的确实就是:
- 复制 DEV 环境的数据库到测试环境
- 复制 DEV 环境的数据到测试环境
在操作过程中, 主要遇到的坑:
- 直接通过 datagrip 复制数据的方式复制,发现表结构没有完全复制
- 通过 airbyte 同步数据的方式,发现表结构没有完全复制,同时还新加了很多字段
2.1 Datagrip 复制表的方式复制
关于使用 airbyte 同步数据的方式就不在这里介绍.主要介绍一下使用复制表方式的数据同步.
下图是通过复制表的方式进行复制,复制结果是表结构数据没有完全复制
直接选择一个 postgres 的 schema 进行复制
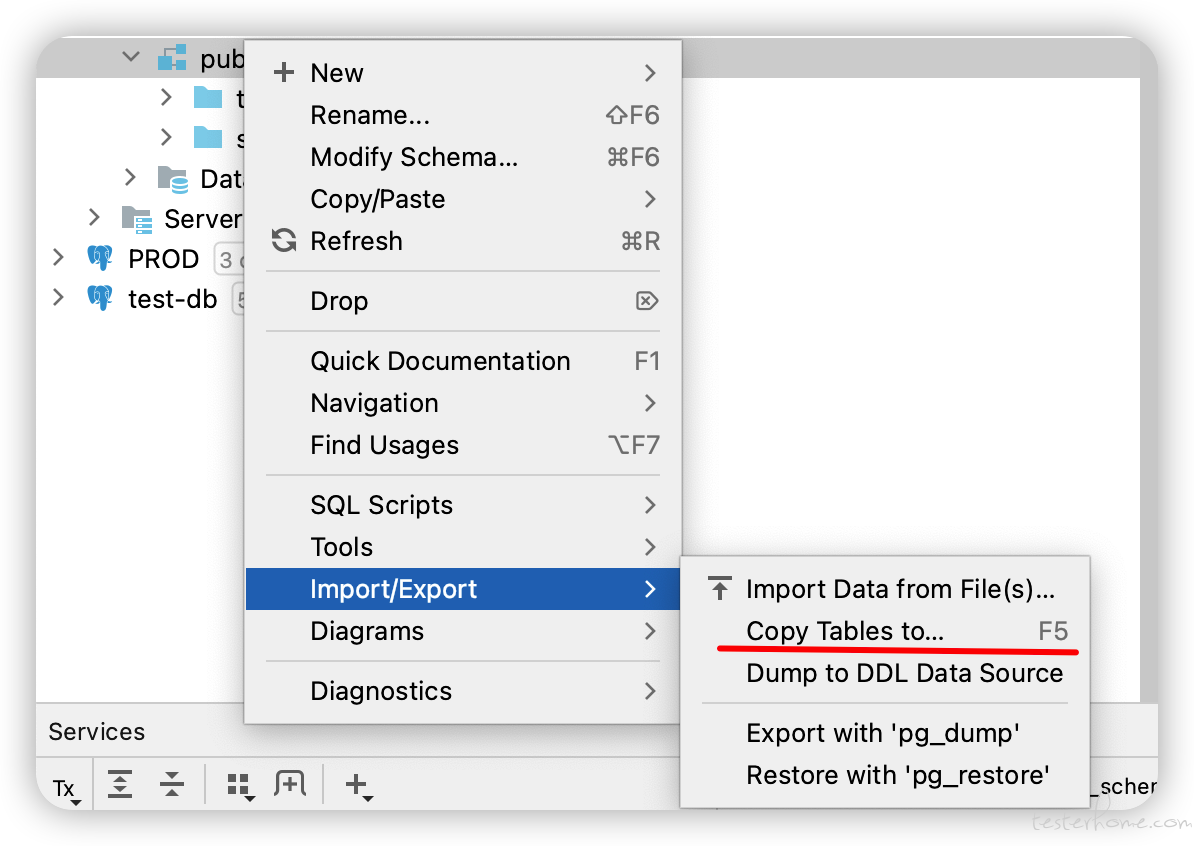
复制完发现类似表中的一些默认值,sequence,index,key,trigger 等都没有复制完成
发现数据没有表结构没有复制完全,那是心慌,心慌的,因为:一个一个表的去排查那是非常耗时间的,最少有 100 张表
修改还了知道会不会有删除数据或者需要重新导入,导入数据也很花时间
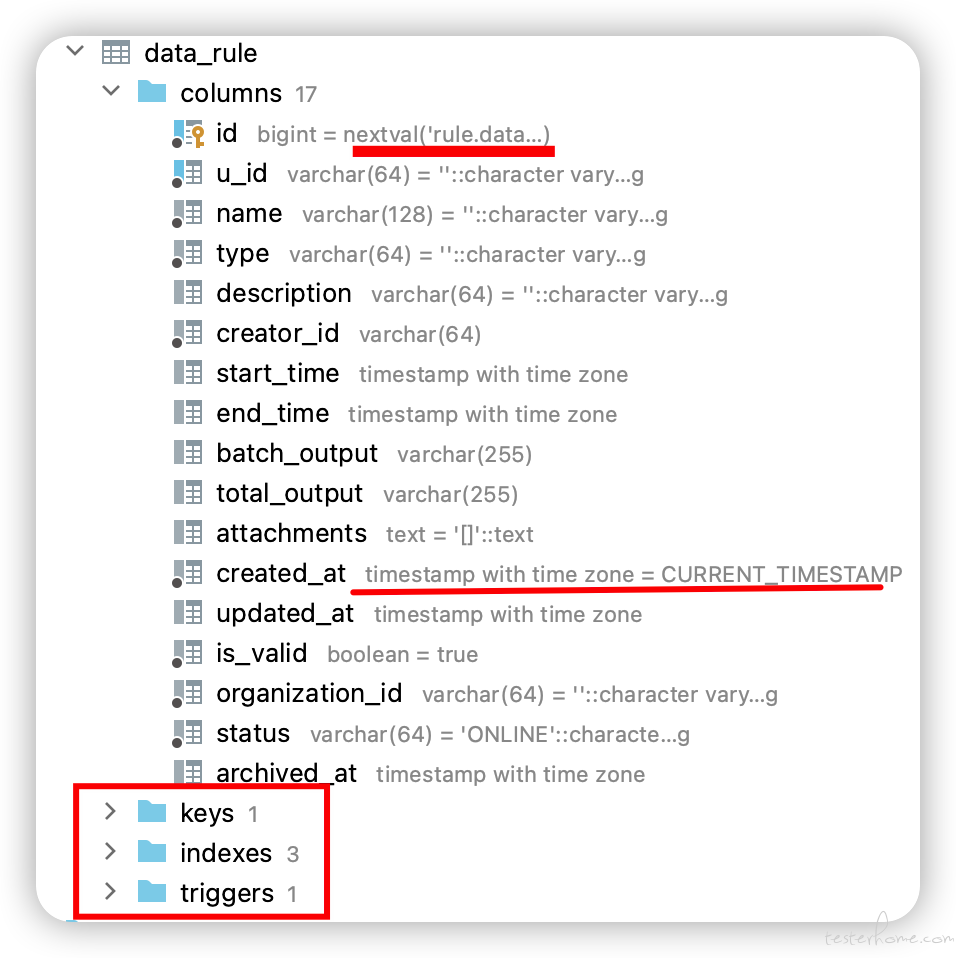
但是不管怎么样,至少数据是复制过去了,那么表结构的差别方式怎么来处理呢?
在研究了半天之后,发现有一个 compare structure 工具,使用 compare structure 工具,可以直接对比表结构差别并且生成 SQL 语句:
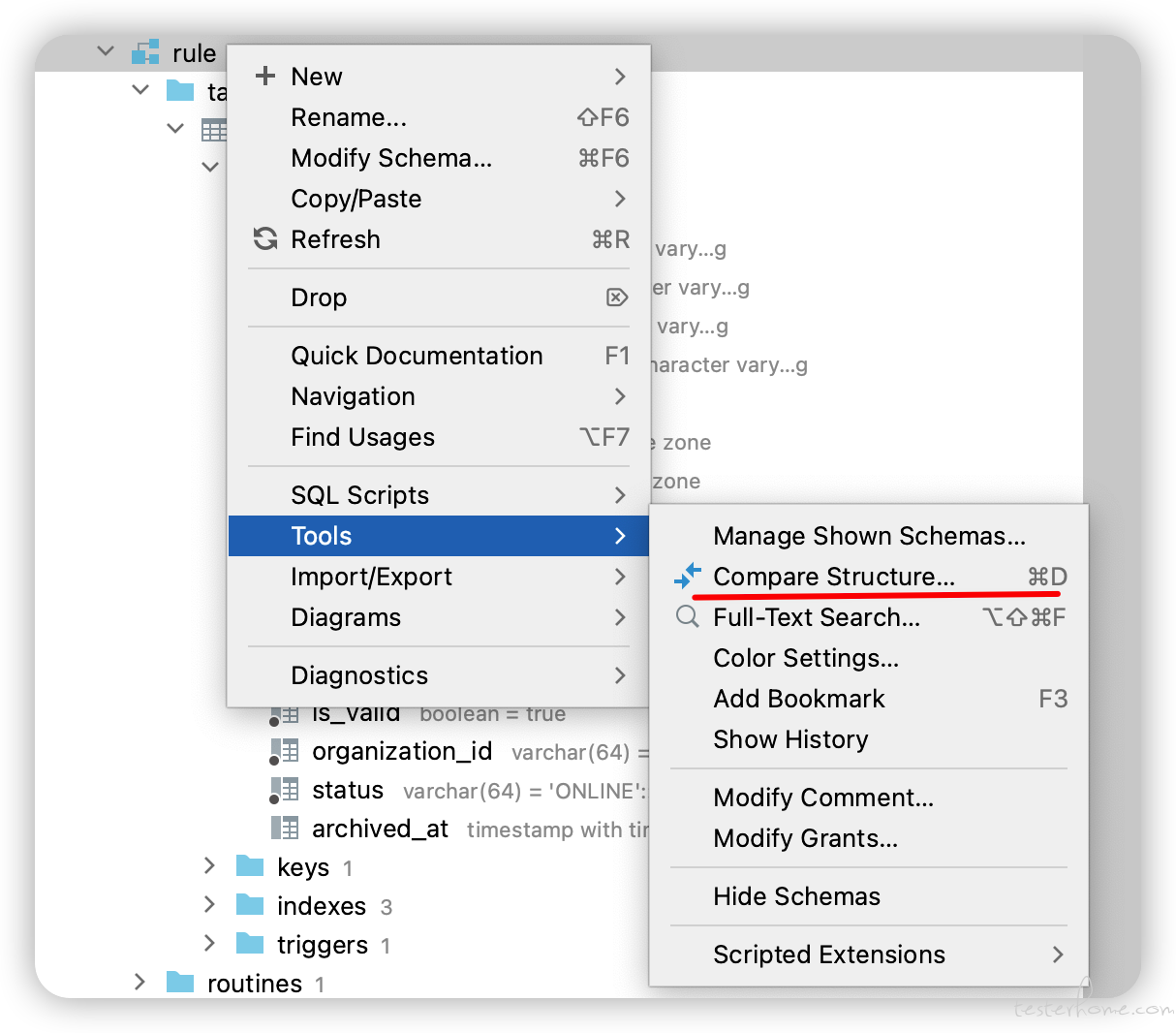
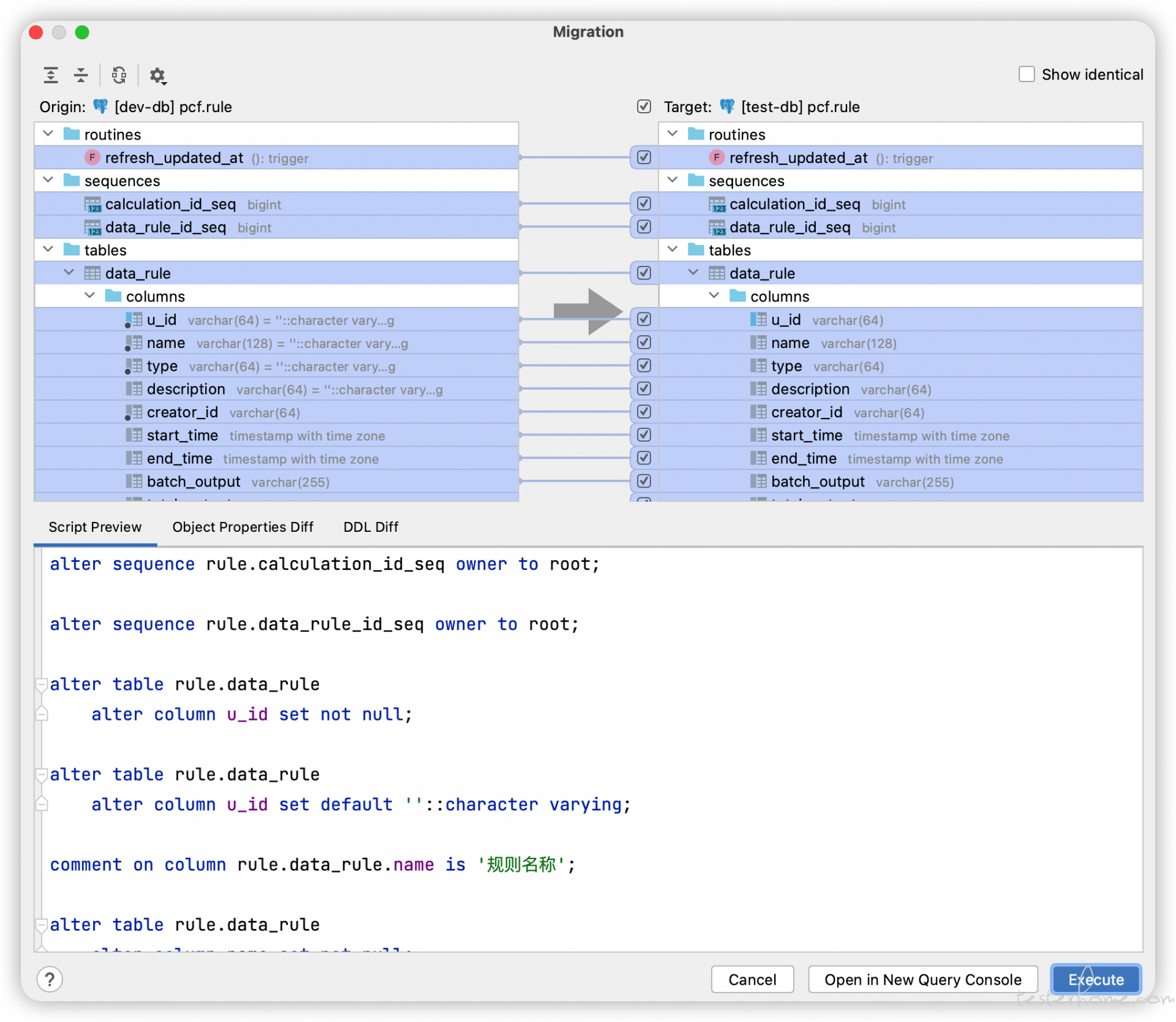
直接运行下面的脚本,忽律了一些无关紧要的错误,运行成功了。数据也没有问题,那个心情真是不是一下子能描述的。
以上是一个复制数据和表结构的一个方法,数据量不是海量的情况下速度还是非常快。
然后事情并没有那么简单,突然发现复制过来的表不能插入数据了
2.2 不能插入数据的处理
不能插入数据,主要原因是每一个表的 sequence 从 0 开始的,所以就会发生 id 键冲突的情况?
怎么办,有时 100 多个 sequence,手动更新那会类似. 此时突然想到,python,顺手写一个设置 sequence 的代码,说干就干.
在 postgres 中设置 sequence 可以用如下 SQL:
select setval('calculator.unit_process_snapshot_id_seq'::regclass,max(id)) from unit_process_snapshot;
而一个 schema 的 sequeunce 直接可以复制得到,只要选择所有的 sequence,Ctrl+C 就可以把 sequence 名子全部复制得到
![[sql-sequence.png]]
那这样就是好办了,写一段 python,通过获得的 sequence 名字列表,直接生成更新的 SQL 就可以。
代码怎么写,其实可以很快就能写出来:
- 输入是: 类似于:
unit_process_snapshot_id_seq这样一个 sequence 名字 - 输出就是:
- 其实只要用 python string 的一个 format 方法就可以,string 的模版是:
selectsetval('calculator.{}'::regclass,max(id)) from {}然后简单生成一下表名称,也就是 sequence 去掉_id_seq 就可以生成了,同样这样也就可以批量生成了
最好 python 代码 3 分钟搞定:
seq = """
activity_answer_id_seq
task_id_seq
unit_process_id_seq
unit_process_snapshot_id_seq
"""
def generate_postgre_seqs(schema_name:str,seqs: str):
all_seq = seqs.split("\n")
result = []
for item in all_seq:
if len(item) > 1:
result.append(generate_postgres_seq(schema_name,item))
return result
def generate_postgres_seq(schema_name:str,seq_name: str, table_name: str = None) -> str:
temp = 'select setval(\'{}.{}\'::regclass,max(id)) from {};'
if table_name is None:
table_name = seq_name.replace("_id_seq","")
return temp.format(schema_name,seq_name, table_name)
def test_seq():
print(seq)
result = generate_postgre_seqs("calculator",seq)
for item in result:
print(item)
一个批量生成更新数据库 sequence 的脚本就这样完成了,把数据结果在数据库中执行,sequence 问题也就搞定了,100 多个 sequence 一转眼就完成了.
小结
通过以上的一个小例子,用了一些工具,辅助一些简单脚本,就可以把一件看起来很麻烦的事情解决了. 我们回顾一下做了什么事情:
- Datagrip 复制表数据,发现数据库的表结构没有完全复制
- Datagrip 通过构 Compare Structure 方式,完全同步表结构,并且不影响数据
- 通过一段 python 脚本,生成修改数据库 sequence 的代码,直接运行就把 sequence 同时改掉
文章同步发布在微信公众号: Datagrip/python 使用快速构建测试环境数据库