通用技术 Goroutine Leaks 引发的思考 (Go 语言)
邹靓 | 作者
引言:江湖中有个传说:10 次内存泄露,9 次都是 goroutine 泄露。( Go 语言)
背景
前段时间,通过监控观察到,我们业务中的某个服务突然出现 goroutine 数量、堆对象数量激增的情况,作为测试人员的我们跟着开发一步一步揭开了问题的真相,同时通过这个问题的排查也引发了我们的一些思考,如果你也有遇到过类似问题,毫无头绪的时候,欢迎阅读本文,跟我一起拨开层层迷雾,找到问题真凶。(一切问题都只是纸老虎~)
排查过程
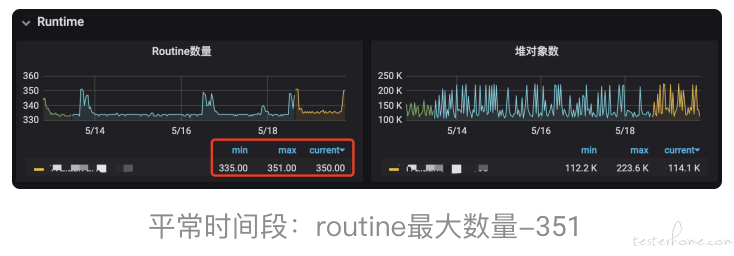
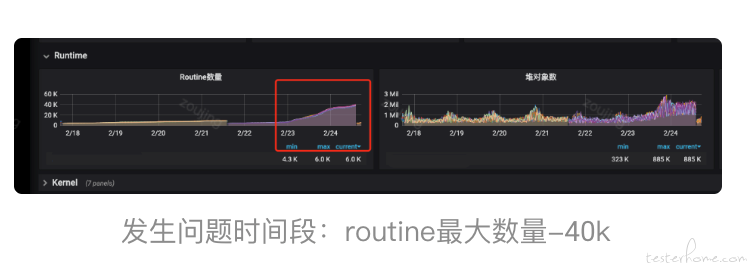
当发生 goroutine 数量激增的时候,我们的主要排查的思路一般都是先通过直接调用 runtime.NumGoroutine()( Go 的 runtime 包里面包含了一些与 Go 运行时系统交互的操作,比如控制 goroutine 的函数。NumGoroutine 函数就是查看 goroutines 运行数量)或者使用可视化的 goroutine 数量监控工具来查看 goroutine 数量,通过对比异常时间段前后 goroutine 的数量是不是持续不正常增长(业务不在高峰期的时候突然翻 N 倍被视为异常)来确认是否是 goroutine 泄漏,一旦确认,那么接下来就可通过找到 goroutine 泄漏的问题作为切入点(忘记设置默认的请求超时时间、跟 redis 、sql 交互超时、向已关闭的通道发数据等等)从而找到根因。
那么我们回到这个业务例子吧!本次可以通过监控看到,问题发生时间前后数量差距巨大且是持续增长的趋势,确定是 goroutine 泄漏,到底是什么导致了泄漏呢?那么接下来,就必须找到切入点根治它。
1、切入点 1:找出最耗时的地方在哪里
当我们遇到 goroutine 相关的问题,第一个步骤就可以先打印异常的 goroutine stack trace 信息,这样需要选择合适的工具以及方法,目前获取 stack trace 异常信息的方式主要有:
- 1、使用 panic 来获取异常退出的 stack trace 信息(不巧的是,本次事件没有明显错误异常)
- 2、使用 SIGQUIT 信号来终止没有 panic 但是有异常的程序,并获取 core 文件来查看 stack trace 信息(但这个方式可能破坏第一现场)
- 3、使用开源工具例如 gops[1] 进行堆栈跟踪(自行到下载第三方开源工具并使用)
- 4、使用 go tool pprof http://ip:port/debug/pprof/goroutine 获取内存统计信息、goroutine 信息以及其他性能分析数据 [2](根据个人喜好,本次笔者使用的是 pprof 获取 goroutine 信息)。
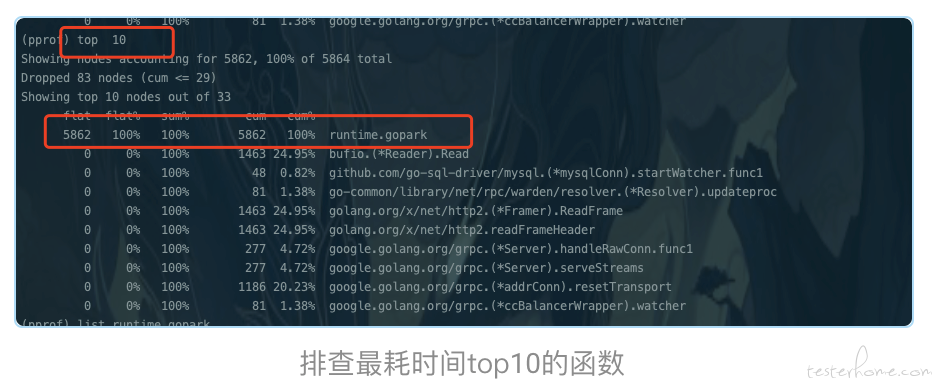
从上图中的耗时数据可以看出,rutime.gopark 函数占了大头,这代表着存在大量 goroutine 在调用了 runtime.gopark 函数后都被暂停了,即被放入等待状态,这可能导致 goroutine 线程阻塞,这显然是不健康的状态,那么既然知道了时间大量花费在 rutime.gopark 函数的执行上,接着开始找的就是什么东西在内存中占据了大量位置。
2、切入点 2:找到最耗内存的地方在哪里
那么,最耗内存的,究竟是何方妖孽呢?
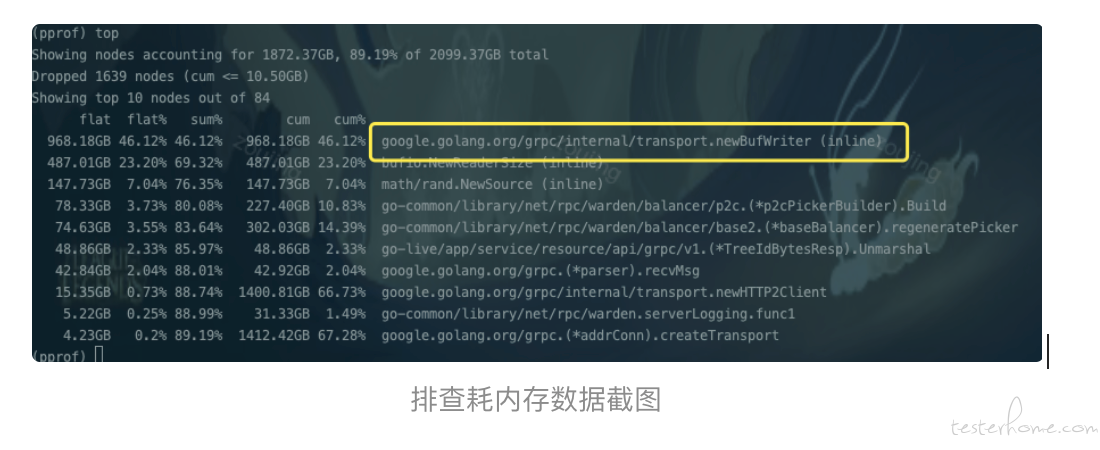
我们仍然是通过 pprof 执行 go tool pprof -alloc_space http://ip:port/debug/pprof/heap 和 top 命令找到 top1 耗内存的位置是:google.golang.org/grpc/internal/transport.newBufWriter ( golang 软件包中 gRPC 的内部方法),这代表我们这次的泄漏极有可能跟 gRPC 使用不当相关,接下来让我们来找找证据,确定这个猜想。
3、找到证据,确认猜想:是否是 gRPC 引起 goroutine 的阻塞?
我们还是通过 pprof 执行 http://ip:port/debug/pprof/goroutine?debug=1 or 2(debug=1 可以查看某条调用路径上,阻塞在此 goroutine 的数量。debug=2 则可以查看所有 goroutine 的运行栈(调用路径),可以显示阻塞在此的时间 [3])两种命令方式都可以查看当前阻塞在此 goroutine 的数量以及运行栈,乍一看这些密密麻麻的调用栈信息确实让人眼花缭乱,所以标记出了最重要的信息含义方便理解(图 1[3] 所示)。
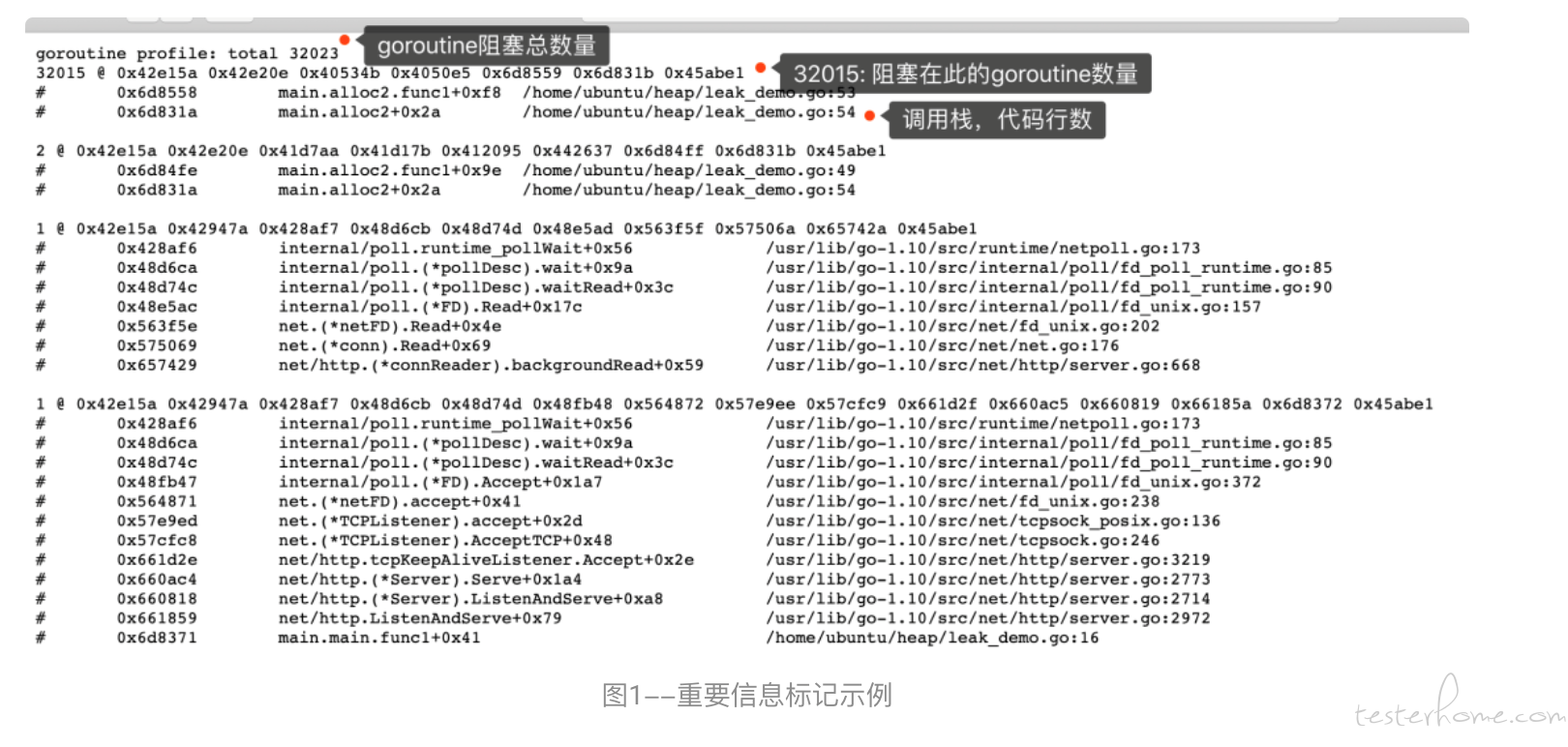
通过登陆问题服务器,可以明显看到大量 gotoutine 在调用栈 google.golang.org/grpc@v1.37.0/internal/transport/http2_client.go:340 的地方阻塞着(图 2 中标记黄色的代表阻塞的 goroutine 数量以及调用栈,代码函数;标记红色的地方代表 goroutine 阻塞的总数量),随即查看 TCP 连接数果然在问题发生时间段前后有出现断层、且数量在持续激增(图 3 所示中标记红色的地方可以看出存在明显断层,标记黄色的地方可以看到 TCP 连接数持续激增的趋势)。
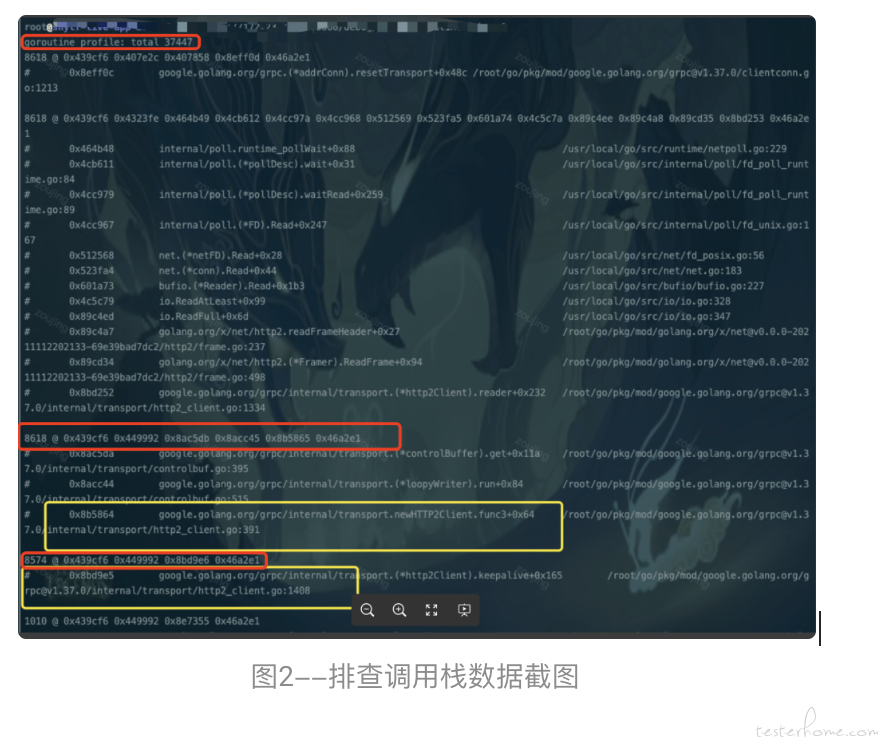
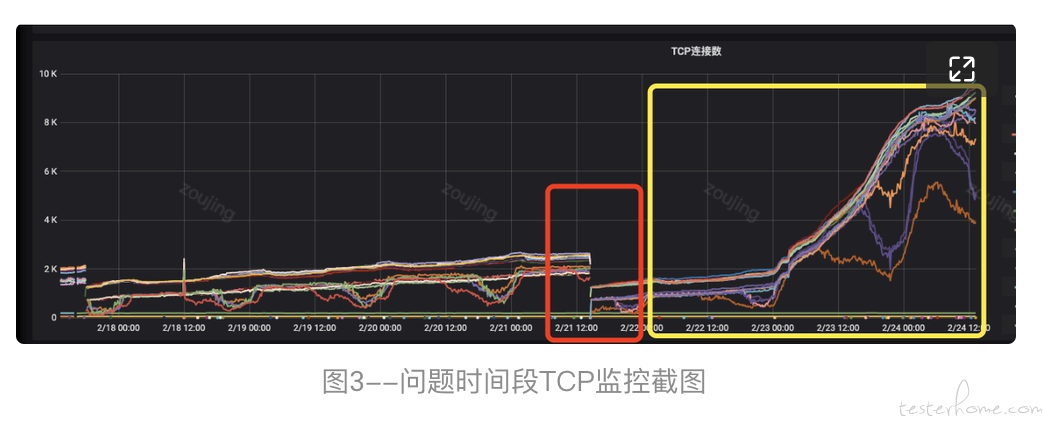
通过切入点的查看最终可以基本确认了我们之前的猜想,是由于 gRPC-Client 的异常创建引起 goroutine 的数量阻塞,并引起了本次 goroutine 泄漏。
4、罪魁祸首锁定:找到造成本次泄漏的代码
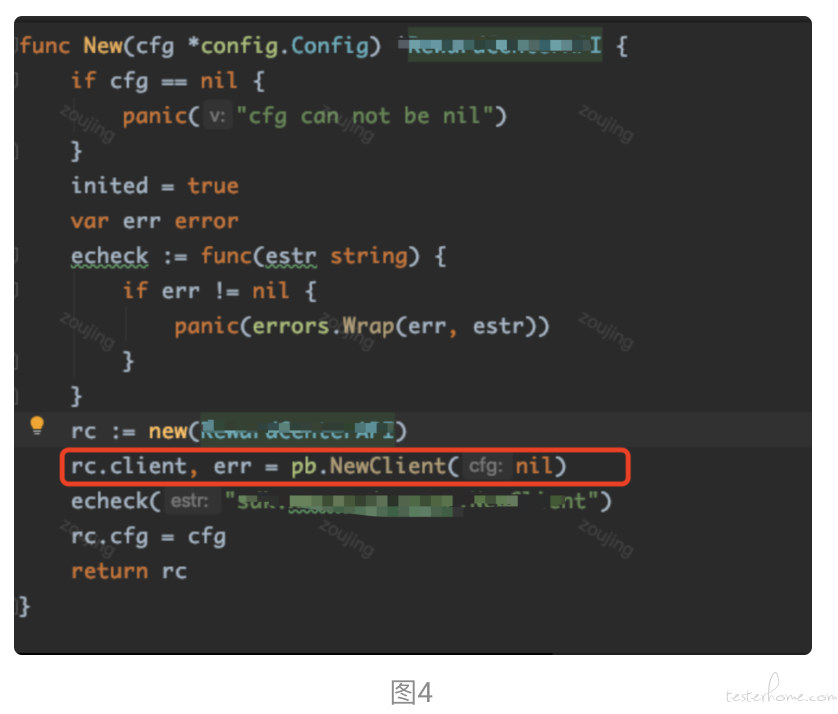
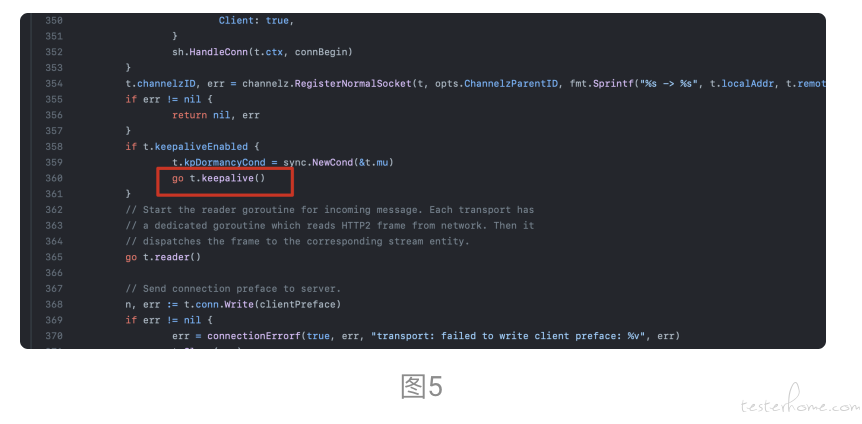
通过开发的 code review 问题发生时间段上线的新代码可以看到在业务代码中使用到了 Google Cloud Client Libraries for Go ,这类库通常在服务端使用 gRPC 来连接 Google Cloud API[4]。本次问题代码中 Client 应该写成单例模式使用,不应该写在具体的函数中每次请求就创建一个新的 Client ,且 go t.keepalive() 并发调用导致大量请求下会有越来越多的 client keepalive(图 4、图 5)而这些 client 连接都是长连接不会立马关闭,最终导致出现了 TCP 连接数量和 groutine 数量激增的情况。
答疑解惑
本次问题已经排查完毕,找到原因并解决,但是仍有几个疑问。
1、goroutine 到底是个啥?
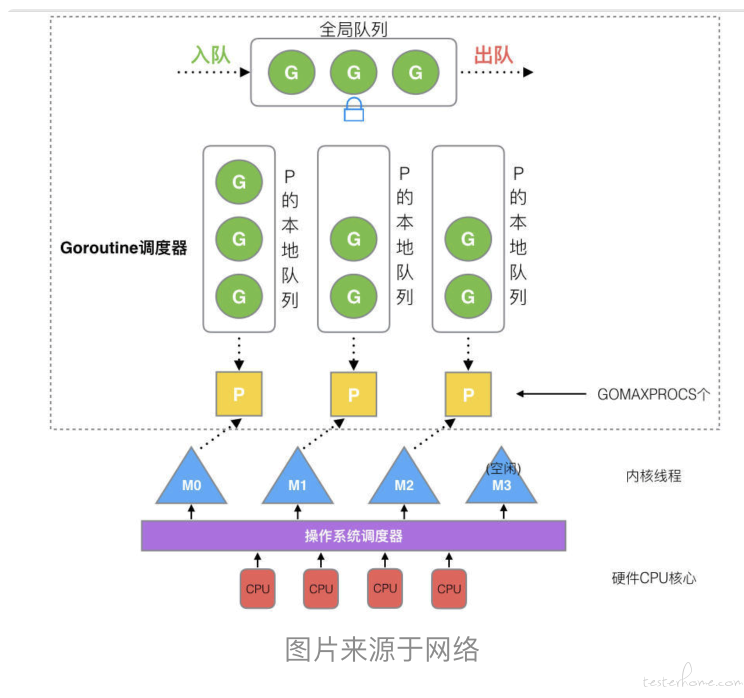
在 java/c++ 中我们要实现并发编程的时候,我们通常需要自己维护一个线程池,并且需要自己去包装一个又一个的任务,同时需要自己去调度线程执行任务并维护上下文切换,少了任何一步都不可以完成并发编程,而 Go 语言中的为了实现简单方便的的并发编程的机制,引入了 goroutine(协程)跟必不可少的 GMP 模型。简单来说就是 Go 程序在运行的时候会智能地将 goroutine 中的任务合理地分配给每个 CPU。在 Go 语言编程中你不需要去自己写进程、线程、协程,当你需要让某个任务并发执行的时候,你只需要把这个任务包装成一个函数,开启一个 goroutine 去执行这个函数就可以了( go func() ),非常简单粗暴 [6]。
2、Go 不是有 GC 吗,为什么还会有不同形式的内存泄漏的发生?
GC 是清理不再使用的对象,GO 的 GC 主要的触发机制有手动跟自动,手动回收需要开发自己调用 runtime.GC(),自动回收的触发时机分为两种,第一种是超过内存大小阈值(控制器计算的触发堆大小)、第二种是定时触发(默认 2min 触发一次)。在本次线上问题中我们遇到的是 gRpc-client 长连接不断重复创建新的 goroutine 但是没有被正确的合理复用导致的泄漏问题(属于持续不断地产生新的 goroutine、在 goroutine 生命周期没有结束的情况下 GC 不会清理这块内存)。
3、goroutine 泄露除了本次的场景,到底还有多少其他场景?
除了错误创建 gRPC-Client 连接还有关于通道(channel)的场景,比如 channel 的读或者写:
- 1.无缓冲 channel 的阻塞通常是写操作因为没有读而阻塞
- 2.有缓冲的 channel 因为缓冲区满了,写操作阻塞
- 3.期待从 channel 读数据,结果没有 goroutine 写数据
- 4.使用是当有一个全局对象时,可能不经意间将某个变量附着在其上,且忽略的将其进行释放,则该内存永远不会得到释放
- 5.select 操作,select 里也是 channel 操作,如果所有 case 上的操作阻塞,goroutine 也无法继续执行 [6]。
- 6.一个 goroutine 尝试向一个没有接收方的无缓冲 channel 发送消息
当然还有别的类型的内存泄漏问题,从这几个例子中简单举几个 demo 说明,方便以后遇到了踩坑。
比如第 4 种、跟第 6 种形式的内存泄漏例子具体如下 [7]:
测试函数
第 4 种错误使用。例如:
var cache = map[interface{}]interface{}{}
func keepalloc() {
for i := 0; i < 10000; i++ {
m := make([]byte, 1<<10)
cache[i] = m
}
}
第 6 种错误使用。例如:
var ch = make(chan struct{})
func keepalloc2() {
for i := 0; i < 100000; i++ {
// 没有接收方,goroutine 会一直阻塞
go func() { ch <- struct{}{} }()
}
}
调用函数测试
package main
import (
"os"
"runtime/trace"
)
func main() {
f, _ := os.Create("trace.out")
defer f.Close()
trace.Start(f)
defer trace.Stop()
keepalloc()
keepalloc2()
}
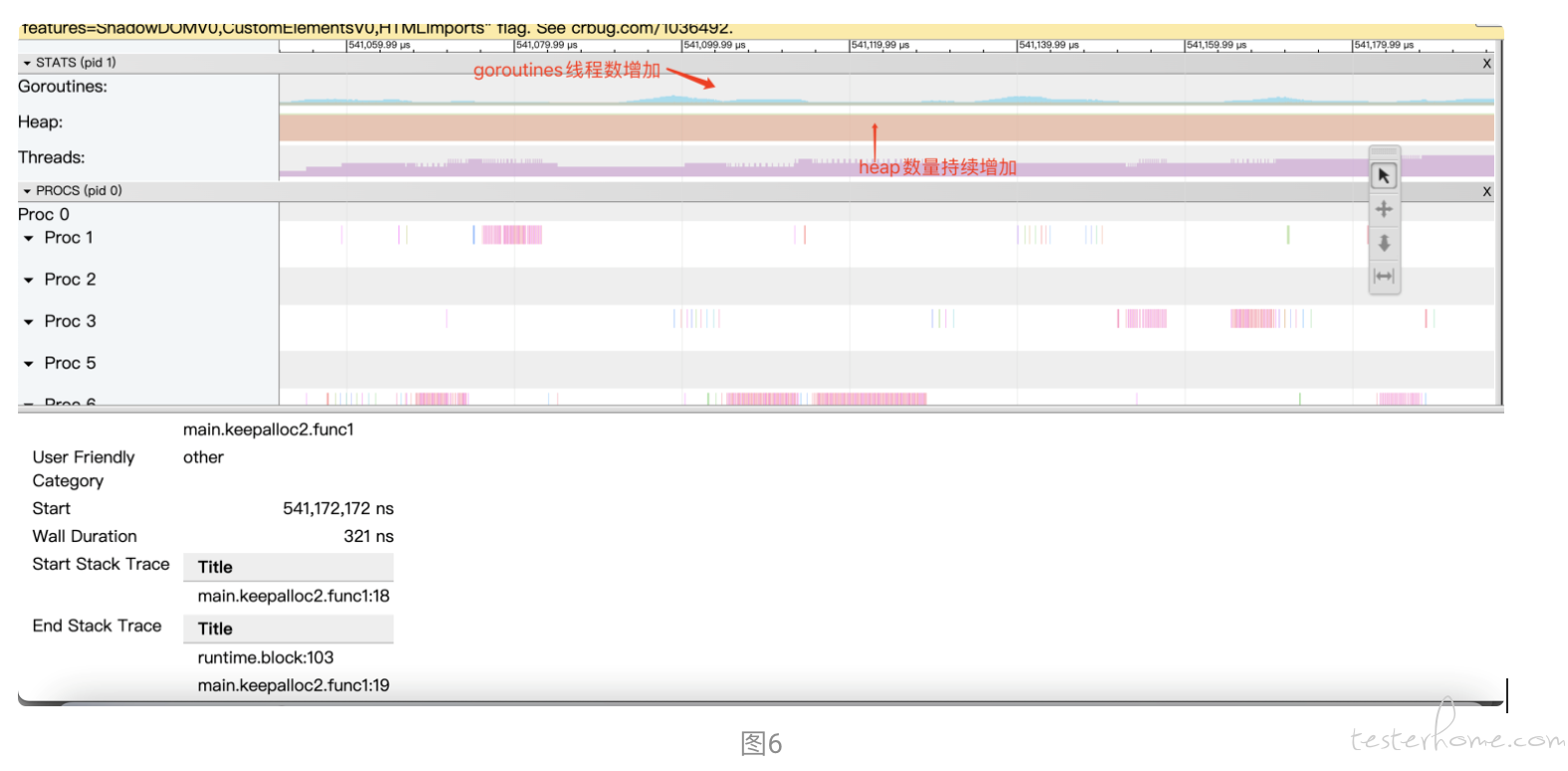
go run main.go 运行代码以后会有一个 trace.out 文件生成用命令 go tool trace trace.out 来查看发现堆(Heap)跟 goroutine 线程数一直在增长,如图 6 所示这两个案例中的 Heap 并没有被清理掉,最终可能酿成内存泄漏的大祸。
4、怎么在测试的时候发现 goroutine 泄露?
目前通过手动功能测试是无法发现 goroutine 泄露,所以一般借助工具来写单测实现泄漏检测。比如 goleak[8] 这个工具主要的方法有两种:1.第一种是 VerifyNone ——针对单一的 test case ,在每个测试用例结束检测有没有泄漏(这种方法可能会对测试用例的代码有入侵)。
具体代码:
func TestA(t *testing.T) {
defer goleak.VerifyNone(t)
// test logic here.
}
2.第二种方法是 VerifyTestMain ——针对 test package ,它会创建一个函数在每个 test package 结束后检测有没有泄漏。
具体代码:
func TestMain(m *testing.M) {
goleak.VerifyTestMain(m)
}
还有一些针对 VerifyTestMain 的方式可能存在无法确定是哪个 test case 引起的,就可以通过 bash 脚本来确定来源:
# Create a test binary which will be used to run each test individually
$ go test -c -o tests
# Run each test individually, printing "." for successful tests, or the test name
# for failing tests.
$ for test in $(go test -list . | grep -E "^(Test|Example)"); do ./tests -test.run "^$test\$" &>/dev/null && echo -n "." || echo -e "\n$test failed"; done
总结
通过这次的 goroutine 泄漏的学习印证了 Dave 的那句话:“Never start a goroutine without knowing how it will stop.” 当一个启用跟运行成本低的 goroutine 却被人遗忘它也会占用其他成本(CPU、RAM)时,往往会发生滥用、无人管制最终酿成泄漏的悲惨下场。我们在使用 gRPC-Client 的时候应该做好复用 client ,并在使用完的时候做好 close ,不然会出现 TCP 连接数过多的内存溢出。
参考
[1].https://github.com/google/gops
[2].https://pkg.go.dev/net/http/pprof
[3].https://lessisbetter.site/2019/05/18/go-goroutine-leak/
[4].https://github.com/googleapis/google-cloud-go
[5].https://learnku.com/articles/58641
[6].https://www.topgoer.com/
[7].https://www.bookstack.cn/read/qcrao-Go-Questions/spilt.7.GC-GC.md
[8].https://github.com/uber-go/goleak
 好不容易上手 Python 了,现在又来了 go
好不容易上手 Python 了,现在又来了 go