1、常用时间、日期函数
需要结合 to_date 、to_char 两个函数使用,库表时间类型有的是 varchar 类型的,要转成时间类型
① 获取当前时间:current_timestamp,localtimestamp
② 获取当前日期:CURRENT_date
③ 获取当前月份:to_char(now(),'yyyy-MM')
④ 获取近7天的数据
SELECT * from cm_capital_outflow where to_char(date,'yyyy-mm-dd') BETWEEN to_char( CURRENT_DATE - INTERVAL '7 day', 'yyyy-mm-dd' ) AND to_char( CURRENT_DATE, 'yyyy-mm-dd' )
⑤获取近一个月的数据
to_char( CURRENT_DATE - INTERVAL '1 months', 'yyyy-mm-dd' )
⑥获取近一年的数据
to_char( CURRENT_DATE - INTERVAL '1 year', 'yyyy-mm-dd' )
⑦毫秒时间戳转日期:to_timestamp(round(start_time/1000))
⑧秒时间戳转日期:to_timestamp(long_)
⑨日期字段截取年份:date_part('year',f_fromdate)
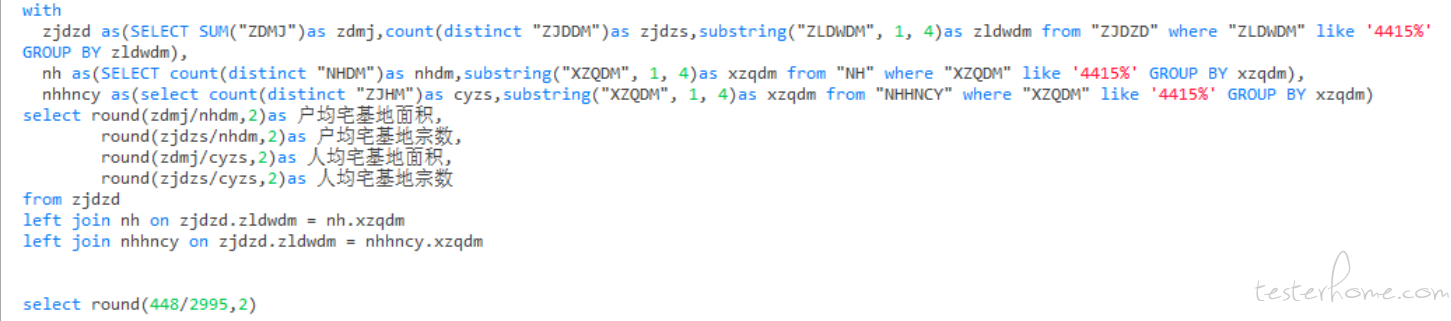
2、With 的用法
With 子句有助于将复杂的查询分解为更简单的语句,便于阅读,也可以当做一个为查询而存在的临时表,WITH 子句在使用前必须先定义.
格式: with 自定义表名 1 as(后面跟着 sql 语句的查询),自定义表名 2 as(后面跟着 sql 语句的查询)
多个临时表的使用
3、递归查询
在 WITH 子句中可以使用自身输出的数据

1.向上递归
with RECURSIVE hr_dept1 as(
SELECT * from hr_dept where dept_id='489614256'
union
SELECT hr_dept.* from hr_dept,hr_dept1 where hr_dept.dept_id=hr_dept1.parent_id)----递归查询
SELECT dept_id,dept_name,dept_type,parent_id from hr_dept1
ORDER BY dept_type
1 sql中with hr_dept1 as () 是对一个查询子句做别名,同时数据库会对该子句生成临时表;
2 recursive 是一个函数,他会把查询出来的结果再次代入到查询子句中继续查询
3 最后一句select后跟的字段必须少于等于hr_dept和hr_dept1中字段。
2.向下递归
with RECURSIVE hr_dept1 as(
SELECT * from hr_dept where dept_id='51597175'
union
SELECT hr_dept.* from hr_dept,hr_dept1 where hr_dept.parent_id=hr_dept1.dept_id)
SELECT dept_id,dept_name,dept_type,parent_id from hr_dept1
ORDER BY dept_type
4、select 条件中 case then 的用法
格式:case
when then
when then
.......
end
1、计算不同年龄段人数的占比
2、注意between and 是双包含于的关系
3、目前身份证号长度只有15位、18位两种,所以查询固定长度为15、18的证件号码
select b0/(b0+b18+b30+b50+b70)::float as 零到18岁,b18/(b0+b18+b30+b50+b70)::float as 十八到30岁,b30/(b0+b18+b30+b50+b70)::float as 三十到50岁,b50/(b0+b18+b30+b50+b70)::float as 五十到70岁,b70/(b0+b18+b30+b50+b70)::float as 七十岁以上 from ---计算不同年龄段的人数占比
(
with t as (
SELECT (CURRENT_DATE - to_date(substring(zjhm,7,4),'YYYY'))/365 as age,zjhm ---18位新证件号
from cg.qc_jtcy
where area_id like '41%' and xb in ('男','女') and length(zjhm)=18
GROUP BY zjhm
union all
SELECT (CURRENT_DATE - to_date('19'||substring(zjhm,7,2),'YYYY'))/365 as age,zjhm ---15位老证件号
from cg.qc_jtcy
where area_id like '41%' and xb in ('男','女') and length(zjhm)=15
GROUP BY zjhm---t表根据身份证号计算年龄,并通过group by对证件号去重处理
)
select
count(case when age between 0 and 17 then 1 end) as b0,
count(case when age between 18 and 29 then 1 end) as b18,
count(case when age between 30 and 49 then 1 end) as b30,
count(case when age between 50 and 69 then 1 end) as b50,
count(case when age >70 or age =70 then 1 end) as b70
from t ---b表是根据身份证号计算不同年龄段的人数
)b
5、where 条件中 case when 的用法
select b.qhmc as name,sum(a.tbmj) as datas from yw_tjxxb_cb a
INNER join sys_adminarea b on a.qhdm = b.qhdm
where bxgsdm='6' and nf='2021' and zwdm in('07', '02', '52', '23', '17','04', '22', '53', '03', '06', '16', '01', '08') and
case when length(rtrim('1000000', '0')) = 1 then length(a.qhdm) = 2
when length(rtrim('100000', '0')) = 2 then length(a.qhdm) = 4 and a.qhdm like concat(rtrim('100000', '0'),'%')
when length(rtrim('100000', '0')) = 4 then length(a.qhdm) = 6 and a.qhdm like concat(rtrim('100000', '0'),'%')
when length(rtrim('100000', '0')) = 6 then length(a.qhdm) = 9 and a.qhdm like concat(rtrim('100000', '0'),'%')
when length(rtrim('100000', '0')) = 9 then length(a.qhdm) = 12 and a.qhdm like concat(rtrim('100000', '0'),'%')
else a.qhdm = rtrim('100000', '0') end
GROUP BY b.qhmc
备注:length(rtrim('6500200', '0')) = 2 去除右侧所有的0后长度为2,
length(a.qhdm) = 4 取qhdm长度为4的区划
a.qhdm like concat(rtrim('650000', '0'),'%') 并且 qhdm是以去除0后的区划开始的
也就是说查出65甘肃省下所有的市(市是4位区划)
BI大屏中’100000’ 需要替换为变量,比如'${qhdm}'
6、case when 给字段赋值
select qhdm,
(case
when substring (bdh,21,12) <> qhdm then 'qhdm错误'
when substring (bdh,1,4) <> nf then 'nf错误'
when substring (bdh,7,1) <> datagroup then 'tbj错误'
end
)bdh
from yw_tbqdstatus ORDER BY bdh
7、HAVING 配合 GROUP BY 子句,在创建的分组上设置条件
例子:查询一个表中身份证号重复的数据。
SELECT id_card ,count(*) FROM hr_employee
GROUP BY id_card
HAVING count(*) >1
计算查询统计结果中大于阈值的数
select dkbm,sum(cdbl)as cdbl from yw_cbycfxtjb
where rwid = 'D71C70DA7AAF4726A109EEDCB8F423DC'
group by dkbm having sum(cdbl) < 0.1
order by cdbl
8、UNION 和 UNION all 的区别
①UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
②UNION ALL 操作符可以连接两个有重复行的 SELECT 语句。
9、类型转换
① postgresql 整数除整数等于0
select round(448/2298::numeric,2)
② 查询重复记录条数
select f_uri,count(*) as c from tbdm_files group by f_uri order by count(*) desc
③ Nhid解密:select decode_sfzh(nhid)
④ 数字转字符串 select cast(123 as VARCHAR);
⑤ 字符串转数字 select cast('123' as INTEGER);
⑥ 避免空值转换报错CAST( COALESCE( NULLIF( col, ‘’), ‘0’) AS INTEGER)
⑦ 日期转字符串 to_char(check_date,'yyyy-mm')
10、跨库查询
SELECT code FROM dblink
( 'dbname=cic_sys user=postgres password=postgresql host=localhost port=3002',
'select code from sys_dept where parent_ids like ''%,41,%'' or code = ''41''') t(code character varying)
11、将纵向数据改成横向数据显示
SELECT dkbm,
sum(case when xsz=1 then xsz else null end) as xsz1,
sum(case when xsz=2 then xsz else null end) as xsz2,
sum(case when xsz=3 then xsz else null end) as xsz3,
sum(case when xsz=4 then xsz else null end) as xsz4,
sum(case when xsz=15 then xsz else null end) as xsz5
FROM yw_proc_rhgcb_s WHERE qhdm = '411328102200' GROUP BY dkbm;
12、string_agg 同字段内容合并
多个字段相同,一个字段不同,将那个不同字段的字符进行拼接,将多条记录显示为一条记录(其他相同字段 group by)
string_agg(DISTINCT b.animal_type,',')
13、将两个不同的字段进行拼接
SELECT work_end_time|| '-' || work_start_time as 作业时间端
14、字符转数值类型,若空字符串则为 0.00
round(sum(cast(COALESCE(nullif(check_result,''),'0.00') as numeric))/count(distinct sample_code),2)
15、给字段值添加单位
SELECT round(SUM(tbmj)/10000,2) ||'万亩' AS 验标面积
FROM yw_tjxxb_cb
WHERE qhdm = '41'
16、通过 sql 构建新表
with t as (
SELECT
'[
{"dm":"1","mc":"种植监测"},
{"dm":"2","mc":"长势监测"},
{"dm":"3","mc":"产量监测"},
{"dm":"4","mc":"灾害监测"}
]' as str
)
SELECT
replace(cast(json(json_array_elements(cast(str as json))) -> 'dm' AS VARCHAR),'"','') AS dm,
replace(cast(json(json_array_elements(cast(str as json))) -> 'mc' AS VARCHAR),'"','') AS mc from t;
17、避免科学技术法
select b.qhmc as 区划名称,sum(a.dkje)::decimal::text as 贷款总额 ---避免显示科学计数法
18、取 json 中某个字段的值
SELECT act_hi_procinst.business_key_::json->> 'businessName' as 公文标题
19、从两个无关联的表查数据
SELECT COUNT (A.enterprise_number ),count(b.service_organize_number)
FROM ht_contract A, wp_work_process b
20、两表关联赋值
表 1 与表 2 根据 seriaild 列做关联
修改 set 表 1.receive_ymd=表 2.ymd
UPDATE table_1
SET receive_ymd=inputymd
FROM(
SELECT *
FROM table_1 AS ta_1
INNER JOIN tbale_2 AS tb_2
ON ta_1.serialid=tb_2.serialid
)tbs
WHERE table_1.create_time=tbs.create_time AND table_1.serialid=tbs.serialids




