专题合集
目录
特殊的进程
容器技术说白了,其实就是一种特殊的进程。
跟普通的进程相比,容器进程活在楚门的世界里,通过 Namespace 的隔离,让它误以为自己是唯一的存在。
在 Linux 里面,提供了 PID、Mount、Network、User 等等这些 Namespace,帮助容器进程在方方面面欺骗自己。
比如一台物理机上,其实有 100 个进程,通过 Pid Namespace 隔离,让它们只能看到自己,它们就会觉得自己才是唯一那个 Pid = 1 的进程。
比如容器的启动,需要挂载自己的操作系统文件,专业术语叫 rootfs(根文件系统),也是通过 Mounts Namespace 来实现。
# 常见的 rootfs
$ ls /
boot etc home lib64 mnt proc run srv tmp var
bin dev lib media opt root sbin sys usr
容器里面的 rootfs 跟服务器节点里面的并不是一致的,它并没有包含操作系统的内核,它只是一些配置文件和目录,便于保持容器进程启动状态与预期一致。
而内核配置,则是在启动的时候共享服务器节点的内核配置,所以调度在同一个服务器节点的容器内核,必然是一致的。
除了 Mounts Namespace,容器还借助了 pivot_root || chroot 来为进程构建一个完善的文件隔离环境。
pivot_root 是由 Linux 提供的一种系统调用,它能够将一个 Mounts Namespace 中的所有进程的根目录和当前工作目录切换到一个新的目录。
pivot_root 会先挂载一个临时的 rootfs 完成特定功能,然后再切换到真正的 rootfs。
而 chroot 系统调用能够将当前进程的根目录更改为一个新的目录,但是系统的其他部分,依旧运行于旧的 rootfs。
所以容器并不是真正意义上的隔离环境,只是一种障眼法罢了。
但是障眼法只要做得好,能欺骗得了自己,就能欺骗得了别人。
不仅如此,Cgroups 的存在,还可以限制容器的资源使用上限,以免它用到了它不该用到的资源。
在 Docker 里面,可以通过 --cpu-period --cpu-quota 配置参数来指定资源。
这也是为什么在前面的文章,我说 Docker 的容器技术其实并不新,不过是 Namespace + Cgroups 的把戏罢了,真正核心的还是它的 Image 。
标准化
前面文章里我提到了 Containerd,OCI,CRI,Runc 等等,听起来很多,实际上这些都是容器在标准化演进过程中的产物罢了。
在解释这些之前,我们先来看看,一个容器 Docker 是怎么把它启动的?
# 温馨 tips
Docker 是 CS 架构,Docker Daemon 作为守护进程,负责与 Docker Client 交互,管理镜像和容器。
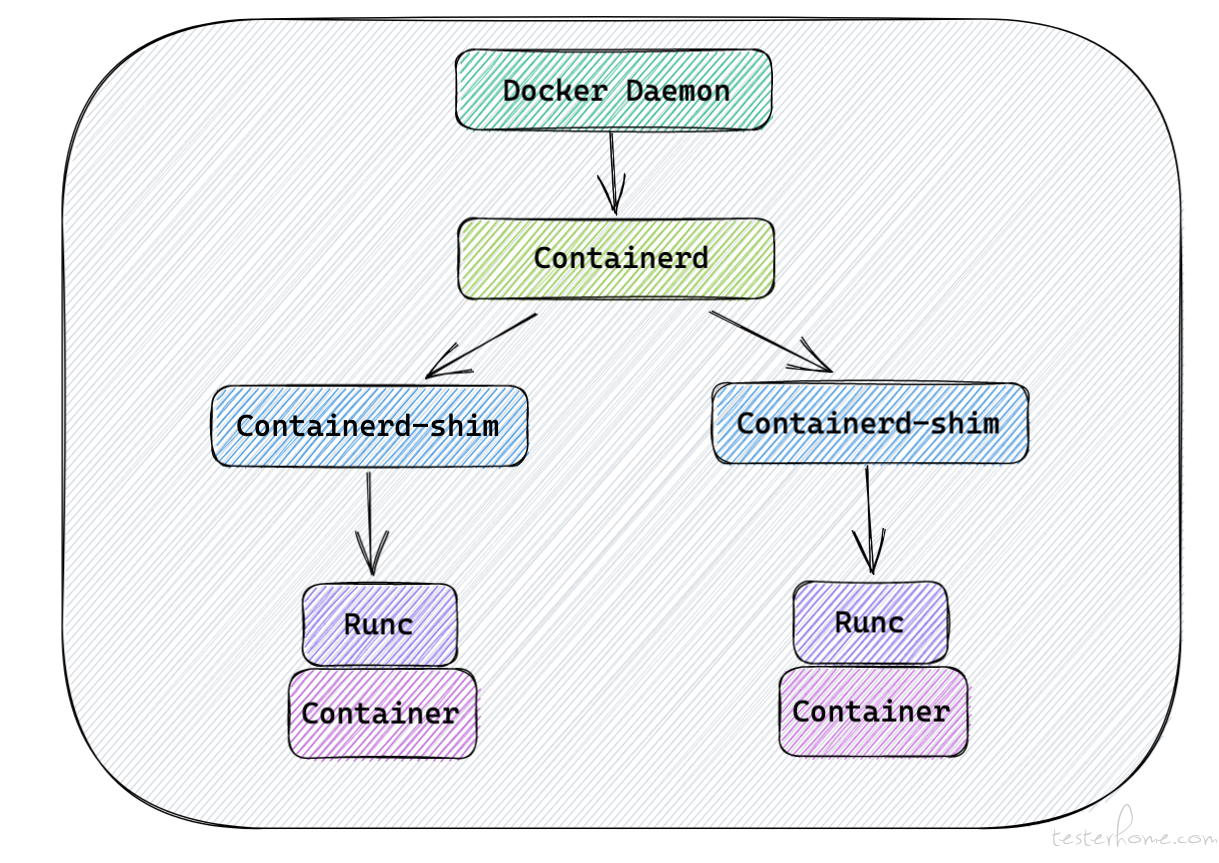
- Docker Daemon 会最先收到我们创建容器的请求,但是它并不会直接创建容器,而是告诉 Containerd 去创建容器。
- Containerd 收到请求以后,也不会直接创建容器,而是启动了一个 Containerd-shim 的进程。
- Containerd-shim 进程会调用 Runc 去启动容器。
- Runc 启动完容器会直接退出,Containerd-shim 会成为容器进程的父进程。
- Containerd-shim 收集容器状态,上报给 Containerd。
这样看起来很麻烦,实际上就是把启动容器的各个步骤细化拆解出来之后的模式。
OCI(Open Container Initiative)定义了容器运行时的标准,包含 runtime-spec 和 image-spec,只要满足了这些标准,容器就能运行在任何的硬件和系统上,而不再依赖于其他的组件。
简单来说就是符合 OCI 标准的容器就能启动,不需要依赖 Docker。
而 Runc 则是一个符合 OCI 标准的轻量级容器运行工具,用来创建和运行容器,包括说的 Namespace 隔离和 Cgroups 限制,都在这里。
而 Containerd 则是作为常驻进程,管理 Runc 创建的容器,维持它们的运行状态。
所以 Containerd 自己是不能作为容器的父进程的,这就是为什么它又创建了一个 Containerd-shim 进程代替自己成为容器的父进程。
而 Containerd-shim 则会在容器中 pid=1 的进程退出后,接管容器中的子进程进行清理,避免出现僵尸进程。
所以,把整个 Docker 容器启动的过程讲完,这些名词组件也就了解得七七八八了。
但是还少了一个 CRI。
CRI(Container Runtime Interface)是容器运行时接口,主要用来定义 Kubernetes 与容器运行时的 API 调用。
只要实现了 CRI 的容器运行时,就可以通过 Kubelet 组件,对接到 Kubernetes 中。
早期 Kubelet 会通过 CRI 调用 Docker-shim,使用 Docker 去启动 Containerd。
后期 Kubelet 直接实现了 CRI-containerd 替代 Docker 去启动 Containerd。
再后来,CRI-O 的出现,直接代替了 Containerd。

所以标准化这种东西,有利有弊,一方面能够让自己的落地能规模化,而另一方面,又让自己被替代的风险大大增加。
关于技术是否需要标准化是一个很值得探讨的问题,与本主题无关,就不展开了,感兴趣可以评论交流。
就这样,一个经过标准化的容器技术,开始被广泛应用。
......
未完待续,有空就开更。
 :
: